Claude Subagents vs. Agent Teams, explained
Compares two Claude multi-agent paradigms: sub-agents (fire-and-forget, isolated context, return compressed results) for embarrassingly parallel tasks, and agent teams (persistent, direct peer communication, shared task list) for ongoing coordination. Provides design principles: decompose by context boundaries, not by roles; start simple and add complexity only when measurable. Covers five orchestration patterns, three situations where multi-agent systems are justified, and common failure modes. Practical advice with code examples for engineers building LLM‑powered agents.
Most people reach for multi-agent systems the moment a task feels complex.
That's almost always the wrong instinct.
The right question isn't "should I use multiple agents?" It's "what kind of coordination does this task actually need?"
The answer to that determines everything about your architecture.
Claude gives you two distinct multi-agent paradigms: sub-agents and agent teams. They look similar on the surface. Architecturally, they solve completely different problems.
大多数人一旦遇到复杂任务,就本能地想到多智能体系统。
这几乎总是错误的直觉。
正确的问题不是"我该不该用多个智能体?",而是"这个任务实际需要哪种协调方式?"
这个问题的答案决定了整个架构。
Claude 提供了两种截然不同的多智能体范式:子智能体(sub-agents)和智能体团队(agent teams)。它们表面上看起来相似。但在架构上,它们解决的是完全不同的问题。
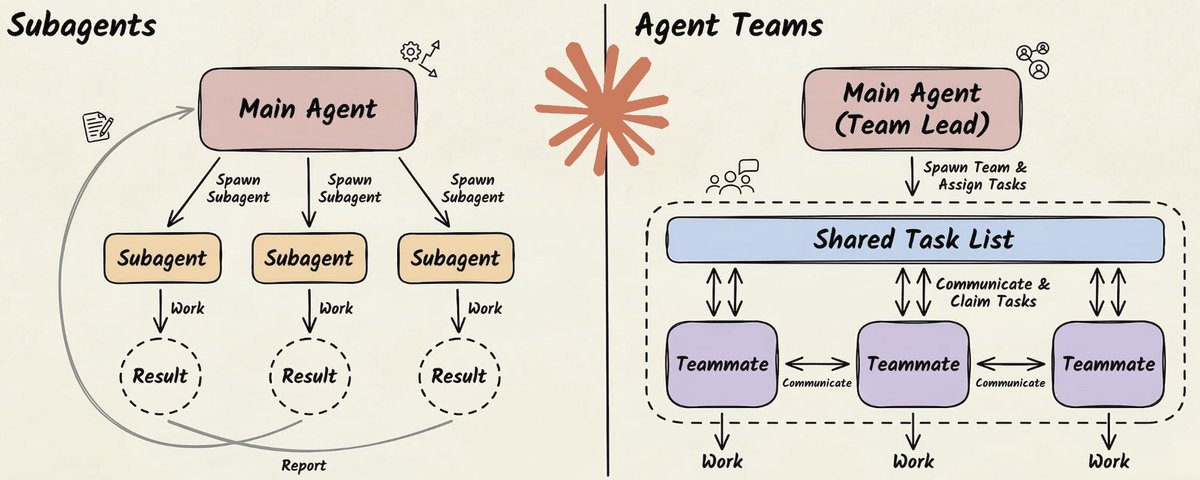
Sub-Agents: Parallelism Through Isolation
A sub-agent is a specialized Claude instance that runs in its own isolated context window.
Here's the mental model: imagine you're a research lead. You don't read every primary source yourself. You delegate focused questions to researchers, they come back with distilled findings, and you synthesize everything into a coherent output.
That's exactly what sub-agents do.
Each sub-agent gets:
- Its own system prompt defining its specialty
- A specific set of tools it can access
- A clean, isolated context window
- One job to do
子智能体:通过隔离实现并行
子智能体是一个专用的 Claude 实例,运行在自己的隔离上下文窗口中。
这里是它的心智模型:想象你是一个研究负责人。你不会自己去读每一篇原始资料。你把有针对性的问题委派给研究人员,他们带回提炼后的发现,然后你把所有东西综合成一个连贯的输出。
这正是子智能体所做的。
每个子智能体拥有:
- 定义其专长的系统提示
- 可访问的一套特定工具
- 一个干净的隔离上下文窗口
- 一件要做的工作
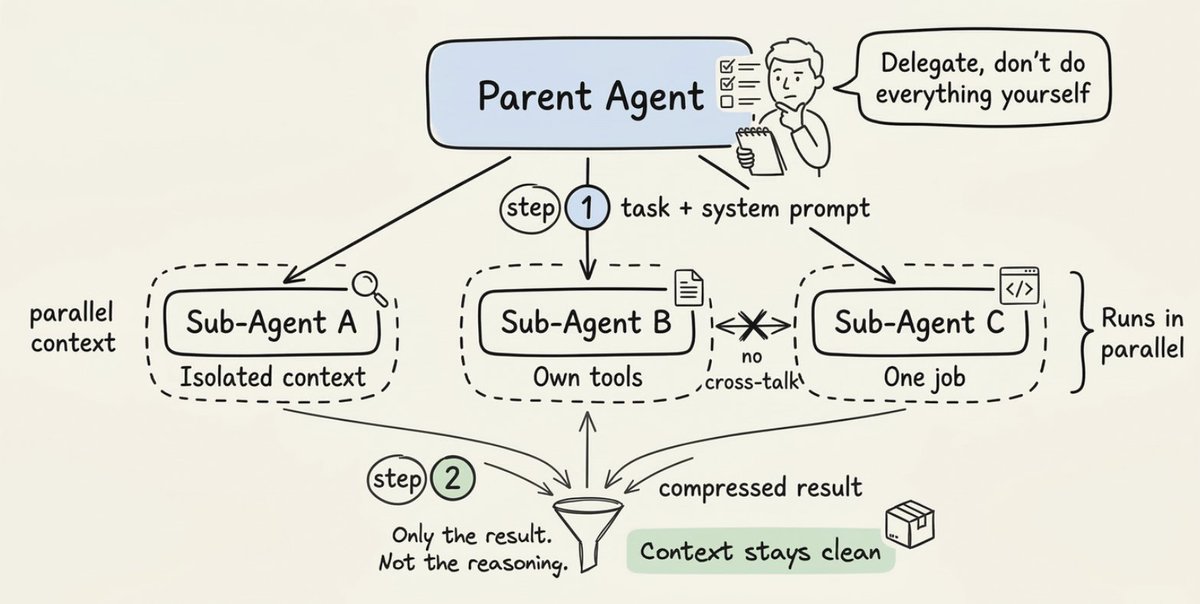
When it finishes, only the final result returns to the parent. Not the full reasoning chain. Not the intermediate steps. Just the compressed output.
The point of sub-agents isn't just parallelism, it's compression. You're distilling a vast amount of exploration into a clean signal, without polluting your parent agent's context with noise.
One hard constraint: sub-agents can't spawn other sub-agents, and they can't talk to each other. Every result flows back to the parent. The parent is the sole coordinator.
This constraint is a feature, not a limitation. It keeps the system predictable. You always know where information flows and where decisions get made.
当它完成后,只有最终结果返回给父智能体。不是完整的推理链。不是中间步骤。只是压缩后的输出。
子智能体的关键不仅是并行,更是压缩。你把大量的探索提炼成干净的信号,而不会用噪音污染父智能体的上下文。
一个硬约束:子智能体不能生成其他子智能体,也不能互相通信。所有结果都流回父智能体。父智能体是唯一的协调者。
这个约束是一个特性,而不是限制。它让系统可预测。你永远知道信息流向哪里,决策在哪里做出。
Here's a minimal SDK example of defining and invoking sub-agents:
from claude_agent_sdk import query, ClaudeAgentOptions, AgentDefinition
async def main():
async for message in query(
prompt="Review the authentication module for security vulnerabilities",
options=ClaudeAgentOptions(
allowed_tools=["Read", "Grep", "Glob", "Agent"],
agents={
"security-reviewer": AgentDefinition(
description="Security specialist. Use for vulnerability checks and security audits.",
prompt="You are a security specialist with expertise in identifying vulnerabilities.",
tools=["Read", "Grep", "Glob"],
model="sonnet",
),
"performance-optimizer": AgentDefinition(
description="Performance specialist. Use for latency issues and optimization reviews.",
prompt="You are a performance engineer with expertise in identifying bottlenecks.",
tools=["Read", "Grep", "Glob"],
model="sonnet",
),
},
),
):
print(message)
The description field is what tells the parent agent which sub-agent to invoke. Here, the prompt mentions "security vulnerabilities" so the parent routes to security-reviewer, not performance-optimizer. If the prompt had asked about latency or bottlenecks instead, the other agent would have been picked. The description is the routing signal. Keep it specific.
这是定义和调用子智能体的一个最小 SDK 示例:
from claude_agent_sdk import query, ClaudeAgentOptions, AgentDefinition
async def main():
async for message in query(
prompt="Review the authentication module for security vulnerabilities",
options=ClaudeAgentOptions(
allowed_tools=["Read", "Grep", "Glob", "Agent"],
agents={
"security-reviewer": AgentDefinition(
description="Security specialist. Use for vulnerability checks and security audits.",
prompt="You are a security specialist with expertise in identifying vulnerabilities.",
tools=["Read", "Grep", "Glob"],
model="sonnet",
),
"performance-optimizer": AgentDefinition(
description="Performance specialist. Use for latency issues and optimization reviews.",
prompt="You are a performance engineer with expertise in identifying bottlenecks.",
tools=["Read", "Grep", "Glob"],
model="sonnet",
),
},
),
):
print(message)
description 字段告诉父智能体该调用哪个子智能体。这里,提示中提到了"security vulnerabilities",所以父智能体将任务路由到 security-reviewer,而不是 performance-optimizer。如果提示询问的是延迟或瓶颈,那么本应选另一个智能体。描述是路由信号。保持具体。
Agent Teams: Coordination Through Communication
Agent teams are a fundamentally different model.
Where sub-agents are short-lived workers that complete a task and disappear, agent teams are long-running instances that persist, communicate directly with each other, and coordinate through shared state.
Think of it like the difference between hiring contractors for isolated tasks vs. assembling a team that works together in the same room.
An agent team has three moving parts:
- A team lead that coordinates work, assigns tasks, and synthesizes results
- Teammates that are independent agent instances, each with their own context window, working in parallel
- A shared task list that tracks what's pending, in progress, and done, along with dependencies between tasks
智能体团队:通过通信协调
智能体团队是一种根本不同的模型。
子智能体是完成工作即消失的短命工人,而智能体团队则是长期运行的实例,它们持续存在、直接相互通信,并通过共享状态进行协调。
可以把它想象成为孤立任务雇佣承包商和组建一个在同一房间内协作的团队之间的区别。
一个智能体团队有三个活动部件:
- 一个团队领导,负责协调工作、分配任务并综合结果
- 队友是独立的智能体实例,每个都有自己的上下文窗口,并行工作
- 一个共享任务列表,跟踪哪些待办、进行中和已完成,以及任务间的依赖关系
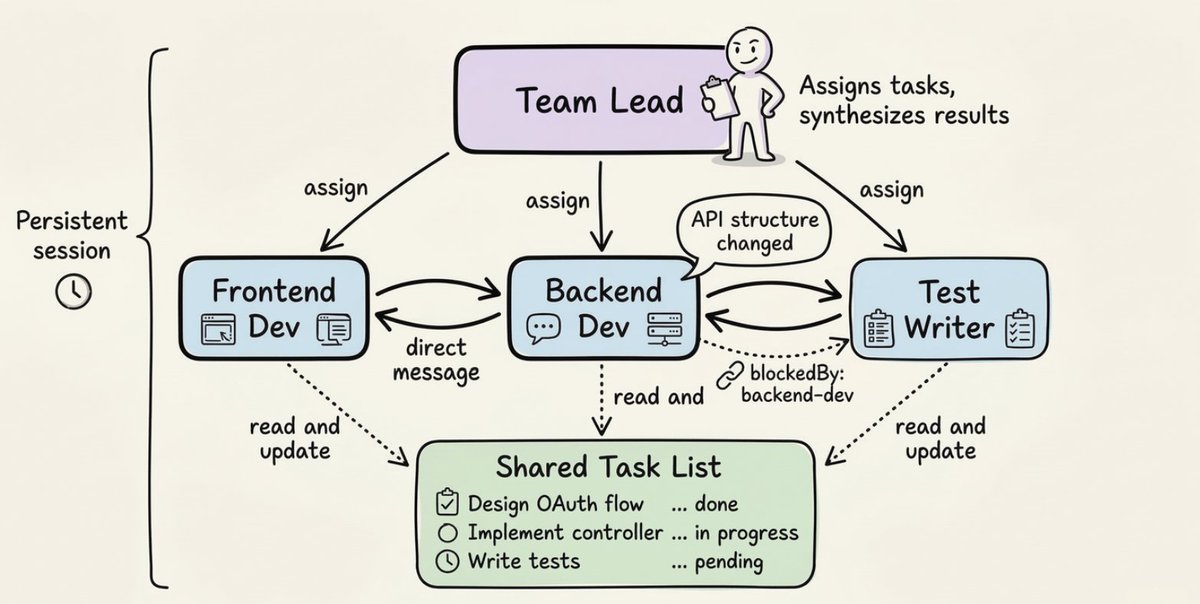
A typical lifecycle looks like this:
Claude (Team Lead):
└── spawnTeam("auth-feature")
Phase 1 - Planning:
└── spawn("architect", prompt="Design OAuth flow", plan_mode_required=true)
Phase 2 - Implementation (parallel):
└── spawn("backend-dev", prompt="Implement OAuth controller")
└── spawn("frontend-dev", prompt="Build login UI components")
└── spawn("test-writer", prompt="Write integration tests", blockedBy=["backend-dev"])
Notice the blockedBy field on the test writer. That's the shared task list doing real coordination work: the test writer won't start until the backend agent is done, without the lead having to manually manage that sequencing.
The big difference from sub-agents is direct peer-to-peer communication. Teammates can send messages to each other, share findings, surface blockers, and negotiate without routing everything through the lead.
You can also interact with individual teammates directly. You're not forced to go through the lead agent for everything.
一个典型的生命周期如下所示:
Claude (Team Lead):
└── spawnTeam("auth-feature")
Phase 1 - Planning:
└── spawn("architect", prompt="Design OAuth flow", plan_mode_required=true)
Phase 2 - Implementation (parallel):
└── spawn("backend-dev", prompt="Implement OAuth controller")
└── spawn("frontend-dev", prompt="Build login UI components")
└── spawn("test-writer", prompt="Write integration tests", blockedBy=["backend-dev"])
注意测试编写器上的 blockedBy 字段。这就是共享任务列表在执行的真正协调工作:测试编写器直到后端智能体完成之后才会启动,而不需要领导手动管理排序。
与子智能体最大的不同是直接的点对点通信。队友可以互相发送消息、分享发现、提出阻塞问题并协商,而不用所有事情都通过领导路由。
你也可以直接与单个队友交互。你不必什么都通过领导智能体。
The Core Distinction: Fire-and-Forget vs. Ongoing Coordination
Here's how to think about the choice between them.
Sub-agents are fire-and-forget.
- You give them a task, they complete it, they report back
- No conversation between agents
- No shared memory, no ongoing state
- Each sub-agent lives and dies within a single session
Agent teams are collaborative.
- Agents persist and accumulate context over time
- Mid-task discoveries surface to teammates immediately
- A frontend agent can tell a backend agent "the API response structure needs to change" and the backend agent adjusts without waiting for the lead to mediate
The clearest way to choose between them:
- Use sub-agents when your work is embarrassingly parallel: independent research streams, codebase exploration, or lookups where the parent only needs the summary
- Use agent teams when your work requires ongoing negotiation: agents that need to reconcile their outputs before proceeding, or where a discovery in one thread changes what another thread should do
核心区别:即发即忘 vs. 持续协调
这是如何思考它们之间选择的方式。
子智能体是即发即忘型的。
- 你交给它们一个任务,它们完成,然后回报
- 智能体之间没有对话
- 没有共享内存,没有持久状态
- 每个子智能体在一次会话中生灭
智能体团队是协作型的。
- 智能体持久存在并随时间积累上下文
- 任务中途的发现立即传达给队友
- 前端智能体可以告诉后端智能体"API 响应结构需要更改",后端智能体无需等待领导调解就能调整
最清晰的决策标准:
- 当你的工作是极度可并行的——独立的研究流、代码库探索或父智能体只需摘要的查找——使用子智能体
- 当你的工作需要持续协商——智能体需要在继续之前协调输出,或一个线程中的发现会改变另一个线程应该做什么——使用智能体团队
How to Design Agent Systems From First Principles
Most multi-agent designs fail because people split work by role instead of by context.
The intuitive instinct is to split by role: planner, implementer, tester. It feels organized. But it creates a telephone game where information degrades at every handoff.
- The implementer doesn't have what the planner knew
- The tester doesn't have what the implementer decided
- Quality drops at every boundary
如何从第一性原理设计智能体系统
大多数多智能体设计失败,是因为人们按角色而不是按上下文拆分工作。
直觉本能是按角色拆分:规划者、实现者、测试者。这感觉有组织。但它制造了一场传话游戏,信息在每次交接时都会衰减。
- 实现者没有规划者所掌握的上下文
- 测试者没有实现者做出的决定
- 质量在每个边界处下降
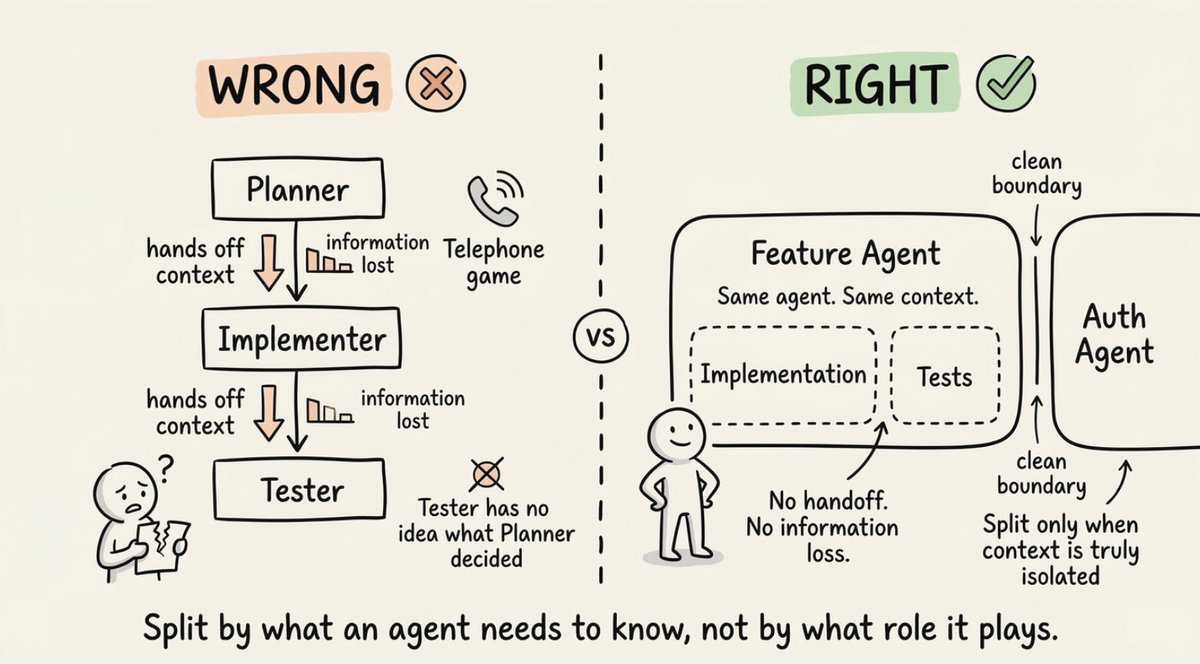
The right mental model is context-centric decomposition.
Ask: what context does this subtask actually need? If two subtasks need deeply overlapping information, they probably belong to the same agent. If they can operate with truly isolated information and clean interfaces between them, that's where you split.
A practical example: an agent implementing a feature should also write the tests for that feature. It already has the context. Splitting those two into separate agents creates a handoff problem that costs more than the parallelism saves.
Only separate when context can be genuinely isolated.
正确的心智模型是以上下文为中心的分解。
要问:这个子任务到底需要什么上下文?如果两个子任务需要深度重叠的信息,它们可能属于同一个智能体。如果它们能够用真正隔离的信息和清晰的接口运作,那才是拆分的时机。
一个实际的例子:实现某个功能的智能体也应该为它写测试。它已经拥有上下文。将那两者拆分成不同的智能体会制造一个交接问题,其代价超过了并行带来的节省。
只有在上下文可以真正隔离的时候才分离。
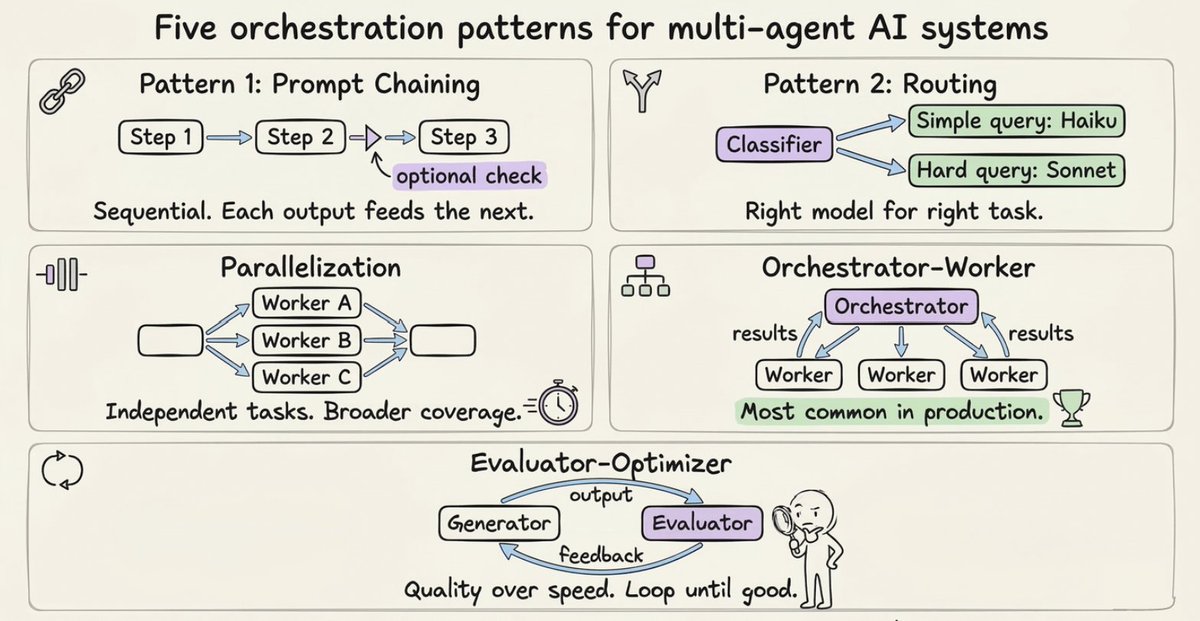
The Five Orchestration Patterns Worth Knowing
Regardless of which paradigm you use, these five patterns cover most real-world needs:
- Prompt chaining: Sequential steps where each call processes the previous output. Use when order matters and steps are dependent.
- Routing: A classifier decides which specialized handler gets the task. Easy questions go to cheaper, faster models. Hard questions go to more capable ones. This is how you keep costs from exploding.
- Parallelization: Independent subtasks run simultaneously. Either the same task runs multiple times for diverse outputs (voting), or different subtasks run at the same time (sectioning).
- Orchestrator-worker: A central agent breaks down the task, delegates to workers, and synthesizes results. This is the dominant architecture for both sub-agents and agent teams, and what most production systems actually use.
- Evaluator-optimizer: One agent generates, another evaluates and provides feedback in a loop. Useful when quality matters more than speed and a single pass isn't reliable enough.
五种值得了解的编排模式
不管你用哪种范式,这五种模式覆盖了大多数现实需求:
- 提示链:顺序步骤,每一步处理前一步的输出。当顺序重要且步骤有依赖时使用。
- 路由:一个分类器决定哪个专门的处理器接收任务。简单问题交给更便宜、更快的模型。难题交给能力更强的模型。这是防止成本爆炸的方法。
- 并行化:独立的子任务同时运行。同一个任务运行多次以获取多样输出(投票),或者不同的子任务同时运行(分段)。
- 协调器-工作者:一个中央智能体分解任务,委派给工作者,并综合结果。这是子智能体和智能体团队的主导架构,也是大多数生产系统实际使用的。
- 评估器-优化器:一个智能体生成,另一个评估并在循环中提供反馈。当质量比速度更重要且单次通过不够可靠时很有用。
When Not to Use Multi-Agent Systems at All
This is the part most articles skip.
Teams have spent months building elaborate multi-agent pipelines only to discover that better prompting on a single agent achieved equivalent results.
Start simple. Add complexity only when you can clearly measure that it's needed.
什么时候根本不该用多智能体系统
这是大多数文章跳过的部分。
团队们花了数月构建复杂的多智能体管线,却发现对单个智能体更好的提示就能达到同等效果。
从简单开始。只有当你清晰衡量到确实需要它时,才增加复杂性。
Multi-agent systems earn their cost in three situations:
- Context protection: A subtask generates information irrelevant to the main task. Keeping it in a sub-agent prevents context bloat.
- True parallelization: Independent research or search tasks that benefit from simultaneous coverage.
- Specialization: The task requires conflicting system prompts, or one agent is juggling so many tools that its performance degrades.
多智能体系统在三种情形下值得其成本:
- 上下文保护:一个子任务产生了与主任务无关的信息。把它放在子智能体中可防止上下文膨胀。
- 真正的并行化:可以从同时覆盖中受益的独立研究或搜索任务。
- 专业化:任务需要冲突的系统提示,或一个智能体要兼顾过多的工具导致性能下降。
They're the wrong call when:
- Agents constantly need to share context with each other
- Inter-agent dependencies create more overhead than execution value
- The task is simple enough that one well-prompted agent handles it
在以下情形下,它们是错误的选择:
- 智能体不断需要共享上下文
- 智能体间的依赖造成的开销超过执行价值
- 任务足够简单,一个良好提示的智能体能处理
One specific warning for coding: parallel agents writing code make incompatible assumptions. When you merge their work, those implicit decisions conflict in ways that are hard to debug. Sub-agents for coding should answer questions and explore, not write code simultaneously with the main agent.
一个针对编码的具体警告:并行智能体写代码会做出不兼容的假设。当你合并它们的工作时,那些隐含的决策会以难以调试的方式冲突。用于编码的子智能体应该回答问题并进行探索,而不是与主智能体同时写代码。
What Makes Multi-Agent Systems Actually Fail
Three failure modes show up constantly.
- Vague task descriptions cause agents to duplicate each other's work.
Every agent needs a clear objective, an expected output format, guidance on what tools or sources to use, and explicit boundaries on what it should not cover. Without this, two agents will research the same thing and neither will notice.
是什么让多智能体系统真正失败
三种失败模式反复出现。
- 模糊的任务描述导致智能体相互重复工作。
每个智能体都需要一个明确的目标、预期的输出格式、关于使用哪些工具或来源的指导,以及明确的边界——不该涵盖什么。没有这些,两个智能体会研究同一个东西,而谁都注意不到。
- Verification agents declare victory without verifying.
Explicit, concrete instructions are non-negotiable: run the full test suite, cover these specific cases, do not mark as complete until each one passes. Vague approval criteria produce false positives.
- 验证智能体未经核实就宣告成功。
明确、具体的指令是不容妥协的:运行完整的测试套件,覆盖这些特定案例,在每一个都通过之前不要标记为完成。模糊的批准标准会产生误报。
- Token costs compound faster than you expect.
The solution is to tier your models intelligently:
- Use your most capable model where it genuinely matters
- Route routine work to faster, cheaper models
- Build in budget controls so costs can't run away unchecked
- 令牌成本的复利增长比你预期的要快。
解决方案是智能地对模型进行分层:
- 在真正重要的地方使用能力最强的模型
- 将常规工作路由到更快、更便宜的模型
- 内置预算控制,防止成本失控
The One Design Principle That Actually Matters
Design around context boundaries, not around roles or org charts.
Start with a single agent. Push it until you find where it breaks. That failure point tells you exactly what to add next.
Add complexity only where it solves a real, measured problem.
真正重要的唯一设计原则
围绕上下文边界设计,而不是围绕角色或组织架构。
从单个智能体开始。推动它直到找到它断裂的地方。那个故障点确切地告诉你要添加什么。
只在解决真正可衡量的问题时才增加复杂性。