Loop engineering: the 14-step roadmap from prompter to loop designer
This post from @0xCodez on X provides a comprehensive 14-step roadmap for transitioning from manual prompting to designing autonomous loop systems in AI-assisted coding. Based on Anthropic engineering docs, Addy Osmani's essay, and recent studies, it's structured in three tiers: first, a 4-condition test to decide if a loop is warranted; second, five building blocks (automations, worktrees, skills, connectors via MCP, sub-agents with maker-checker split); third, building the minimal viable loop and avoiding failure modes like the 'Ralph Wiggum loop', comprehension debt, and security tax. The author emphasizes that loops are not universal—they only earn their cost when tasks repeat, verification is automated, the token budget can absorb waste, and the agent has senior engineer tools. Ideal for engineers already using coding agents who want to orchestrate them into batched, automated workflows.
Loop engineering: the 14-step roadmap from prompter to loop designer.
By @0xCodez · 2026-06-09T15:50:43.000Z

Most developers still prompt their coding agents by hand. They type, they wait, they read the diff, they type again. 9out of 10 builders have never written a single loop that prompts the agent for them.
No automation, no state file, no verifier, no schedule. The leverage point has moved - from typing prompts to designing systems that prompt. This is the 14-step roadmap from prompter to loop designer.
Follow my Linkedin to get fresh AI alpha: linkedin.com/in/lev-deviatkin
This is the 14-step roadmap to make that shift - sourced from Anthropic’s engineering docs, Addy Osmani’s long-form on loop engineering, and recent measurement studies.
Three tiers: figure out if you actually need a loop, learn the five building blocks, then build the smallest one that works without hurting you.
循环工程:从提示者到循环设计者的 14 步路线图
作者:@0xCodez · 2026-06-09T15:50:43.000Z
大多数开发者仍在手动向编程 agent 输入提示。他们打字、等待、阅读 diff,然后再打字。10 个开发者中有 9 个从未编写过一个能替他们提示 agent 的循环。
没有自动化,没有状态文件,没有验证器,没有计划。杠杆点已经转移——从输入提示转变为设计可以自行提示的系统。这是一份从提示者到循环设计者的 14 步路线图。
关注我的 LinkedIn 获取最新 AI 资讯:linkedin.com/in/lev-deviatkin
这份 14 步路线图助你完成这一转变——资料来源于 Anthropic 的工程文档、Addy Osmani 关于循环工程的长文,以及最近的测量研究。
三个层级:先判断是否真的需要循环,然后学习五个基础构件,最后构建一个最小可行且不会反噬你的系统。
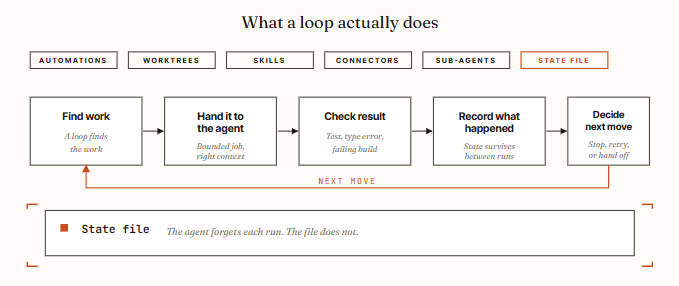
14 个步骤,3 个层级。停止手动提示,开始设计循环。
PART 1 · The Why & The Test
01. Loop engineering is replacing yourself as the prompter.
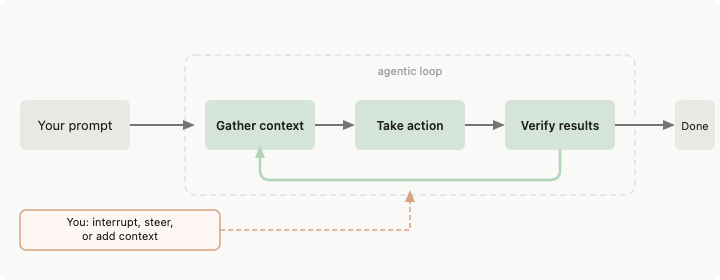
For two years, the way you got something out of a coding agent was: write a prompt, share the context, read what came back, write the next prompt. The agent was a tool and you held it the entire time. That part is ending.
Loop engineering is building a small system that finds the work, hands it to the agent, checks the result, records what happened, and decides the next move - on its own. You design that system once. The system prompts the agent from then on.
Addy Osmani breaks it into six parts:

Anthropic engineers now merge eight times as much code per day as they did in 2024 - a figure Anthropic itself calls “almost certainly an overstatement of the true productivity gain.”
The number is debated. The mechanism isn’t: the leverage point moved from typing prompts to designing the loop that prompts.
第一部分 · 为什么做 & 测试
01. 循环工程的核心是取代你自己作为提示者。
两年来,从编码 agent 获得结果的方式一直是:写一条提示、分享上下文、阅读返回结果、写下一条提示。agent 是工具,而你全程把持着它。这个阶段正在结束。
循环工程是构建一个微型系统,让它自行寻找工作、交给 agent、检查结果、记录已发生的事,并决定下一步——全自动完成。你只需设计一次这个系统,从此由系统来提示 agent。
Addy Osmani 将其分解为六个部分:
Anthropic 工程师现在每日合并的代码量是 2024 年的八倍——Anthropic 自己也称这个数字“几乎肯定夸大了真实的生产力提升”。
数字本身值得商榷,但机制不容置疑:杠杆点已经从输入提示转移到了设计提示循环本身。
02. Run the 4-condition test before you build anything.
Loops earn their cost under four conditions. Miss one and the loop costs more than it returns. The honest take from AlphaSignal’s analysis, and the part most X-threads skip:
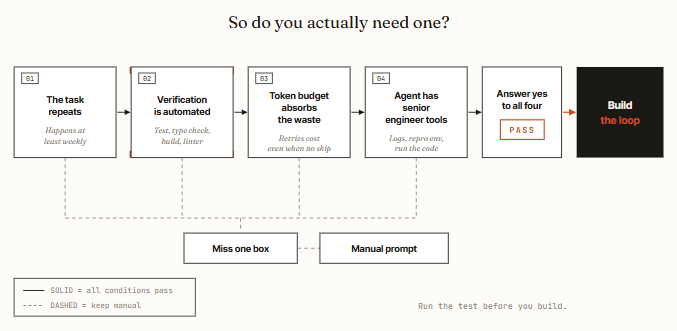
The four conditions in plain English:
- The task repeats. A loop amortizes its setup across many runs. For a one-time job, a good prompt is faster and cheaper. If the work does not recur weekly, you don’t have a loop - you have a script you ran once.
- Verification is automated. The loop needs something that can fail the work without you in the room. A test suite, a type checker, a linter, a build. No automated check means you’re back in the chair reading every diff - the exact job the loop was supposed to remove.
- Your token budget can absorb the waste. Loops re-read context, retry, explore. That burns tokens whether or not the run ships anything. The technique scales with budget, which is why it reads as obvious to people with effectively free tokens and reckless to people on a metered plan.
- The agent has a senior engineer’s tools. Logs, a reproduction environment, the ability to run the code it writes and see what breaks. Without that, the loop iterates blind.
02. 构建任何东西之前,先运行四项条件测试。
循环只有在满足四个条件时才值得投入成本。缺一条,回路花费的成本就会超过其回报。这是 AlphaSignal 分析中的坦率结论,也是大多数 X 帖子略过的部分:
用简单的话说,四个条件是:
- 任务可重复。循环将其搭建成本分摊到多次运行中。对于一次性任务,一句好的提示更快、更便宜。如果工作不是每周重复出现,那你就不是在做一个循环——你只是写了一个只跑一次的脚本。
- 验证是自动化的。循环需要某种能在无人值守时判定工作失败的东西:测试套件、类型检查器、linter、构建。没有自动化检查,意味着你又坐回椅子上阅读每条 diff——而这正是循环本该帮你省掉的活。
- 你的 token 预算能够承受浪费。循环会重读上下文、重试、探索。无论运行是否产出成果,这都会消耗 token。这项技术的效果随预算增长,这也解释了为什么在拥有近乎免费 token 的人看来这是显而易见的选择,而对按量付费的用户则显得鲁莽。
- agent 拥有资深工程师级别的工具:日志、可复现问题的环境、运行自己编写的代码并观察哪里出问题的能力。缺少这些,循环就是在盲目迭代。
03. Who wins, who loses. Loops favor whoever can spend.
The economics are not universal. The people calling loop engineering obvious tend to have unmetered tokens.
The people for whom it’s reckless are usually on a $20 consumer plan trying to run heavy verification loops without hitting limits or a surprise invoice.
Who actually benefits, in practice:
-
Teams with repetitive, machine-checkable work and the budget to run it - continuous test triage, dependency bumps, lint-and-fix passes, issue-to-PR drafts on a codebase with strong test coverage.
-
Codebases with strong existing test suites. If a junior engineer could do the task from a checklist and a test suite would catch their mistakes, a loop fits.
-
Async-first teams with multi-agent patterns already in use. For these teams, routines are the missing orchestration layer. Who should skip it, today:
-
Solo builders on consumer plans - the token bill arrives before the productivity gain does.
-
Anyone working on code with no automated verification. A loop with no real check is the agent agreeing with itself on repeat.
-
Teams whose real constraint is review capacity rather than typing speed. A loop generates more code; if review was already the bottleneck, it just makes the queue longer. For one-off tasks, exploratory work, or anything where “done” is a judgment call, a single well-aimed prompt still wins. The honest version of this article is: loop engineering is real, and most developers don’t need it yet.
03. 谁受益,谁受损。循环偏向有预算的人。
经济学原理并非普遍适用。那些声称循环工程是显而易见选择的人,往往拥有不限量的 token。
而视之为鲁莽行为的人,通常是使用 20 美元消费套餐、试图运行大量验证循环却又不敢触及限额或意外账单的用户。
实际受益者包括:
- 拥有重复性强、可通过机器检查的工作,并有足够的预算支撑运行的团队——例如持续测试分类、依赖升级、lint 修复、在测试覆盖率高的代码库上从 issue 到 PR 的草稿生成。
- 拥有成熟测试套件的代码库。如果一名初级工程师能按照清单完成任务,且测试套件能捕获他们的错误,那么循环就非常适合。
- 已在使用多 agent 模式的异步优先团队。对这些团队而言,例行程序正是缺失的编排层。
谁应该暂时跳过:
- 使用消费套餐的独立开发者——token 账单会先于生产力提升到来。
- 任何在缺乏自动化验证的代码上工作的人。没有真实检查的循环,不过是 agent 在一遍遍自说自话。
- 真正瓶颈在审查能力而非打字速度的团队。循环会生成更多代码;如果审查已是最短板,它只会让队列变得更长。
对于一次性任务、探索性工作,或任何“完成”需要主观判断的工作,一条精准的提示仍然更胜一筹。本文坦诚的结论是:循环工程真实有效,但大多数开发者目前还不需要。
04. The 30-second loop check.
The 4-condition test from step 2 is the strategic decision. This is the tactical one - the checklist you run on a specific task before you turn it into a loop.
Miss one box and keep it as a manual prompt.
-
- The task happens at least weekly. Less than weekly → setup cost will never amortize.
-
- A test, type check, build, or linter can reject bad output. No automated gate → the agent grades its own homework.
-
- The agent can run the code it changes. No reproduction environment → iteration is blind.
-
- The loop has a hard stop. Token budget, iteration count, or time limit. Without one, the loop runs until someone notices the bill.
-
- A human reviews before merge, deploy, or dependency changes. Anything irreversible needs a human approval gate before action.
Good first loops:
-
CI failure triage - nightly, scan failures, classify causes, draft fix PRs for the easy ones.
-
Dependency bump PRs - weekly, scan for updates, test compatibility, open PRs.
-
Lint-and-fix passes - on every PR open event, apply style fixes automatically.
-
Flaky test reproduction - loop until a theory survives the test.
-
Issue-to-PR drafts on code with strong tests, where bad output gets rejected by the suite. Bad first loops - these need a human in the chair:
-
Architecture rewrites
-
Auth or payments code
-
Production deploys
-
Vague product work
-
Anything where “done” is a judgment call
04. 30 秒循环快速检查。
第二步的四条件测试是战略决策,而这里是战术决策——在你将某个具体任务变成循环之前,逐项检查的清单。
只要有一项不满足,就继续使用手动提示。
-
- 任务至少每周发生一次。低于这个频率 → 搭建成本永远无法摊销。
-
- 测试、类型检查、构建或 linter 能对错误输出给出否决。没有自动化关口 → agent 就相当于在给自己批改作业。
-
- agent 能运行它修改的代码。没有可重现环境 → 迭代就是盲目的。
-
- 循环有硬性终止条件:token 预算、迭代次数或时间限制。没有这个限制,循环会一直运行,直到有人注意到账单。
-
- 合入、部署或依赖变更前需人工审查。任何不可逆的操作,在行动之前都必须有一个人工审批关卡。
好的初次循环选择:
- CI 失败分类——每晚运行,扫描失败项,分类原因,为简单问题起草修复 PR。
- 依赖更新 PR——每周扫描更新,测试兼容性,打开 PR。
- Lint 修复——在每次 PR 创建事件时自动应用样式修复。
- 不稳定测试复现——循环直到某个假设通过测试。
- 在测试覆盖强的代码上从 issue 生成 PR 草稿,不良输出会被测试套件拒绝。
糟糕的初次循环选择——这些需要人坐镇:
- 架构重写
- 认证或支付代码
- 生产部署
- 模糊的产品需求
- 任何“完成”需要主观判断的工作
PART 2 · The 5 Building Blocks
05. Automations: the heartbeat.
Automations are what make a loop an actual loop and not just one run you did once. They fire on a schedule, on an event, or on a trigger condition. They’re the heartbeat - everything else in the loop hangs off them.
What this looks like in the two tools that matter:
- Codex. The Automations tab - pick a project, set a prompt, set a cadence, choose local checkout or background worktree. Runs that find something land in a Triage inbox; runs that find nothing archive themselves.
- Claude Code. Three primitives that compose into the same shape:
/loop for session-scoped cadence, Desktop scheduled tasks for restart-survival, Routines for laptop-off cloud runs. Pair with hooks for lifecycle events. Two primitives inside an automation that separate working loops from expensive ones:
- /loop re-runs on a cadence. Use it when you want regular checks regardless of state.
- /goal keeps going until a condition you wrote is actually true. A separate small model checks completion, so the agent that wrote the code isn’t the one grading it.

This is the maker-vs-checker split applied to the stop condition itself.
> /loop 30m /goal All tests in test/auth pass and lint is clean.
Scan src/auth for new failures, propose fixes in claude/auth-fixes,
open draft PR when goal condition holds.
▲ Claude
CronCreate(*/30 * * * * : auth quality loop)
Stop condition: tests pass + lint clean (verified by checker)
✓ Scheduled. Will continue past intermediate completions
until /goal condition is met by independent checker.
第二部分 · 五个基础构件
05. 自动化是循环的心跳。
自动化才是让一个循环成为真正循环的东西,而不只是你手动执行一次的任务。它们基于计划、事件或触发条件来启动。它们就是心跳——循环里的其他一切部分都依附其上。
在两个重要的工具中,它们看起来是这样的:
- Codex。在 Automations 标签页中——选择项目、设置提示、设定频率、选择本地 checkout 或后台 worktree。有所发现的运行会进入 Triage 收件箱;无所得的运行会自动归档。
- Claude Code。三个可组合的基础元素,构成相同的形式:
/loop 用于会话范围内的定时重复,Desktop scheduled tasks 用于重启后依然存活的任务,Routines 用于笔记本电脑关闭后的云端运行。配合 hooks 处理生命周期事件。
自动化内部有两个基础原语,用来区分有效循环和昂贵的浪费:
/loop按固定频率重新运行。当你希望无论状态如何都定期检查时使用。/goal持续运行直到你设定的条件真正满足。由一个独立的小模型检查完成状态,这样编写代码的 agent 就不会给自己的成果打分。
这是将“制造者-检查者”分离原则应用到了停止条件本身。
> /loop 30m /goal All tests in test/auth pass and lint is clean.
Scan src/auth for new failures, propose fixes in claude/auth-fixes,
open draft PR when goal condition holds.
▲ Claude
CronCreate(*/30 * * * * : auth quality loop)
Stop condition: tests pass + lint clean (verified by checker)
✓ Scheduled. Will continue past intermediate completions
until /goal condition is met by independent checker.
06. Worktrees: parallel without chaos.
The second you run more than one agent, the files start colliding. Two agents writing the same file is the same headache as two engineers committing to the same lines without talking first.
A git worktree fixes it - a separate working directory on its own branch sharing the same repo history, so one agent’s edits literally cannot touch the other’s checkout.
How it shows up in both tools:
- Codex builds worktree support in - several threads hit the same repo at once without bumping into each other.
- Claude Code exposes git worktree directly, a --worktree flag to open a session in its own checkout, and an isolation: worktree setting on subagents so each helper gets a fresh checkout that cleans itself up after. Worktrees take away the mechanical collision, but you are still the ceiling. Your review bandwidth decides how many parallel agents you can actually run - not the tool.
06. Worktree:实现并行无冲突。
一旦运行超过一个 agent,文件就开始冲突。两个 agent 写入同一个文件,就像两个工程师不事先沟通就往同一行代码提交更改一样令人头痛。
git worktree 解决了这个问题——它为每个分支创建一个独立的 working directory,共享同一仓库历史,因此一个 agent 的编辑物理上不会触及另一个 agent 的 checkout。
在两个工具中它的表现如下:
- Codex 内置了 worktree 支持——多个线程可以同时操作同一仓库而不会互相冲突。
- Claude Code 直接暴露了 git worktree,提供一个
--worktree标志来在独立 checkout 中打开会话,以及 subagent 的isolation: worktree设置,让每个辅助 agent 获得一个用完即清理的全新 checkout。
Worktree 消除了机械冲突,但你仍然是天花板。你的审查带宽决定了实际能并行运行多少 agent——而不是工具本身。
07. Skills: write project knowledge once. Read on every run.
A Skill is how you stop re-explaining the same project context every session like a goldfish. Both tools use the same format: a folder with a SKILL.md inside, holding instructions and metadata, plus optional scripts, references, and assets.
Why this matters specifically for loops: a loop without skills re-derives your whole project context from zero every cycle. With skills, intent compounds.
The conventions, build steps, “we don’t do it like this because of that one incident” - written once on the outside, read by every run.
name: ci-triage
description: Classify CI failures by root cause (env, flake, real bug,
dependency, infra), draft fixes for the easy ones, escalate the rest.
Trigger whenever a workflow run fails or on the morning triage loop.
---
# CI triage skill
## Classification rules
- env: missing secret, wrong env var, infra not provisioned. # human
- flake: passes on retry without code change. # retry once, then file
- bug: deterministic failure tied to recent commit. # draft fix
- dependency: failure tied to a version bump. # draft rollback
- infra: timeout, OOM, runner issue. # escalate
## Fix patterns
- Auth tests → check src/auth/middleware first
- Database tests → verify migration applied in CI env
- E2E tests → check selectors against the latest UI snapshot
## Never do
- Disable failing tests — always file as escalation instead
- Modify CI config without human approval
- Touch src/payments/ or src/billing/ (in claude/permissions.md)
## State
Update STATE.md after each run: file paths checked, classifications,
PRs opened, items escalated.
07. Skill:一次编写项目知识,每次运行皆可读取。
Skill 是你摆脱“每次对话都像金鱼一样重新解释项目上下文”的方式。两个工具使用相同的格式:一个包含 SKILL.md 的文件夹,里面存放指令和元数据,以及可选的脚本、参考文件和资源。
这对于循环尤为关键:没有 skill 的循环在每一轮都会从零重新推导整个项目上下文。有了 skill,意图可以持续累积。
代码规范、构建步骤、“我们之所以不这么做是因为那次事故”——在外部一次性写好,每次运行都能读取。
name: ci-triage
description: Classify CI failures by root cause (env, flake, real bug,
dependency, infra), draft fixes for the easy ones, escalate the rest.
Trigger whenever a workflow run fails or on the morning triage loop.
---
# CI triage skill
## Classification rules
- env: missing secret, wrong env var, infra not provisioned. # human
- flake: passes on retry without code change. # retry once, then file
- bug: deterministic failure tied to recent commit. # draft fix
- dependency: failure tied to a version bump. # draft rollback
- infra: timeout, OOM, runner issue. # escalate
## Fix patterns
- Auth tests → check src/auth/middleware first
- Database tests → verify migration applied in CI env
- E2E tests → check selectors against the latest UI snapshot
## Never do
- Disable failing tests — always file as escalation instead
- Modify CI config without human approval
- Touch src/payments/ or src/billing/ (in claude/permissions.md)
## State
Update STATE.md after each run: file paths checked, classifications,
PRs opened, items escalated.
08. Connectors: the loop touches your real tools. Via MCP.
A loop that can only see the filesystem is a tiny loop. Connectors, built on the Model Context Protocol (MCP), let the agent read your issue tracker, query a database, hit a staging API, drop a message in Slack.

Codex and Claude Code both speak MCP, so the connector you wrote for one usually just works in the other.
This is the difference between an agent that says “here is the fix” and a loop that opens the PR, links the Linear ticket, and pings the channel once CI is green.
The connectors are the reason the loop can act inside your actual environment, not just tell you what it would do if it could.
The connectors that pay back fastest for loop work, in order:
- GitHub - read repos, create branches, open PRs, comment on issues, react to webhook events. The single biggest day-one win for any code loop.
- Linear or Jira - update tickets as the loop progresses, link PRs back to issues, close items automatically when verification passes.
- Slack - post triage results, ping humans on escalations, summarize overnight runs in the morning.
- Sentry / your error tracker - let the loop investigate live alerts and draft fixes for the high-frequency ones.
08. 连接器:通过 MCP 让循环触及真实工具。
一个只能看到文件系统的循环,是个极其受限的循环。基于 Model Context Protocol (MCP) 的连接器,让 agent 能够读取你的 issue 追踪器、查询数据库、调用 staging API、在 Slack 上发送消息。
Codex 和 Claude Code 都支持 MCP,因此你为其中一个编写的连接器通常可以直接在另一个中使用。
这就是“一个 agent 说‘这是修复方案’”和“一个循环直接打开 PR、关联 Linear ticket、等 CI 变绿后自动通知频道”之间的差别。
正是连接器让循环能够在你的实际环境中采取行动,而不只是告诉你“如果它能做到的话它会怎么做”。
对于循环工作而言回报最快的连接器,按重要性排列如下:
- GitHub——读取仓库、创建分支、打开 PR、评论 issue、响应 webhook 事件。对于任何代码循环而言,这是上线首日最大的收益。
- Linear 或 Jira——随着循环进展更新 ticket、将 PR 关联回 issue、验证通过时自动关闭条目。
- Slack——发布分类结果、在需要升级时通知人类、总结夜间运行的成果并在早上汇报。
- Sentry 或你的错误追踪器——让循环调查实时告警并为高频率错误起草修复方案。
09. Sub-agents: keep the maker away from the checker.
The most useful structural thing in a loop, by far, is splitting the agent that writes from the agent that checks.
Osmani’s framing is exact: the model that wrote the code is “way too nice grading its own homework.” A second agent with different instructions and sometimes a different model catches the stuff the first one talked itself into.

This is the evaluator-optimizer pattern from Anthropic’s December 2024 engineering post under a new name. One model generates, another critiques, repeat. The vocabulary going viral in 2026 was documented eighteen months ago.
How sub-agents land in both tools:
- Codex only spawns subagents when you ask, runs them at the same time, then folds results back into one answer. You define your own agents as TOML files in .codex/agents/ - name, description, instructions, optional model and reasoning effort.
Your security reviewer can be a strong model on high effort while your explorer is some fast read-only thing.
- Claude Code does the same with subagents in .claude/agents/ and agent teams that pass work between them.
The usual split: one agent explores, one implements, one verifies against the spec. The reason it matters specifically inside a loop: the loop runs while you are not watching, so a verifier you actually trust is the only reason you can walk away.
Sub-agents burn more tokens since each one does its own model and tool work - spend them where a second opinion is worth paying for.
09. 子 agent:让制造者与检查者分离。
到目前为止,循环中最有用的结构设计,就是将编写的 agent 和检查的 agent 分离。
Osmani 的表述一针见血:编写代码的模型“对自己的作业总是过于仁慈”。第二个 agent,携带不同的指令,有时甚至是不同的模型,能捕获第一个 agent 说服自己通过的问题。
这本质上就是 Anthropic 2024 年 12 月工程文章中提到的“评估器-优化器”模式,只是换了个新名字。一个模型生成,另一个模型批评,如此循环。2026 年才流行起来的术语,其实在 18 个月前就已经被记录下来。
子 agent 在两个工具中的具体体现:
- Codex 只在用户要求时才生成子 agent,让它们同时运行,然后将结果折叠回一个答案。你可以在
.codex/agents/中以 TOML 文件定义自己的 agent:包括名称、描述、指令、可选的模型和推理努力级别。你可以让安全审查员使用高努力的高强度模型,而探索 agent 则是一个快速的只读角色。 - Claude Code 也类似,通过
.claude/agents/中的子 agent 和 agent 团队在工作间传递任务来实现。
常见的划分方式是:一个 agent 探索,一个 agent 实现,一个 agent 根据规范进行验证。
这在循环中特别重要的原因:循环是在无人监督时运行的,因此一个你真正信任的验证器,才是你能够放心走开的唯一理由。
子 agent 会消耗更多 token,因为每个 agent 都要进行自身的模型调用和工具操作——请只在第二意见值得付出的地方使用它们。
PART 3 · Build It Right or Don’t Build It
10. The state file. The agent forgets. The file does not.
This is the piece that sounds too dumb to matter and is actually the spine of every working loop. A markdown file, a Linear board, a JSON state -anything that lives outside the single conversation and holds what’s done and what is next.
Why this matters: agents have short memory by default. What they learn this session is gone tomorrow unless you write it down.
Osmani’s rule: the agent forgets, the repo does not. A loop without persistent state restarts every run; a loop with state resumes.
# Loop state · ci-triage
## Last run
2026-06-09 03:30 UTC · 7 failures classified, 3 fixes drafted, 4 escalated
## In progress
- claude/fix-auth-token-refresh — tests passing locally, awaiting CI
- claude/fix-flaky-payment-webhook — retry pattern applied, monitoring
## Completed today
- claude/bump-axios-1.7.4 → merged (CI green, deps loop verified)
- claude/lint-fix-pass-june-9 → merged
## Escalated to humans
- src/billing/refund.ts — tests failing in 3 ways, root cause unclear
- ci/staging-runner — infra timeouts, not a code issue
## Lessons learned (write here, not in chat)
- 2026-06-08: PowerShell hits TLS 1.2 issue on this Windows runner. Use bash.
- 2026-06-07: tests/e2e/checkout requires Stripe webhook secret in env. Skip if missing.
## Stop conditions met since last review
- /goal “all tests pass + lint clean” achieved on commit 3a7b8c1 at 02:14 UTC
Two patterns for where the state file lives:
- Markdown in the repo - STATE.md at the root or inside .claude/. Version-controlled. Simple. Diff-readable. Best for solo or small team work.
- External system (Linear, GitHub Issues, a database) - survives across repos, queryable, supports team-wide visibility. Best for production loops where multiple humans need to see what the loop is doing. For long-running loops that risk drifting off the goal, pair the state file with a standing high-level spec - VISION.md or AGENTS.md - that the agent rereads each run. State tells the agent where it is. The spec tells it where to go.
第三部分 · 要么正确构建,要么不建
10. 状态文件:agent 会忘记,文件不会。
这听起来是个蠢到无关紧要的点,但实际上它正是每个工作循环的脊梁。一个 markdown 文件、一块 Linear 看板、一个 JSON 状态——任何独立于单次对话之外、记录了已完成和待办事项的东西。
为什么重要:agent 默认只有短暂记忆。它们在这场对话中学到的东西明天就会消失,除非你把它写下来。
Osmani 的原则:agent 会忘记,仓库不会。没有持久状态的循环,每次运行都从零开始;有状态的循环,可以从中断处继续。
# Loop state · ci-triage
## Last run
2026-06-09 03:30 UTC · 7 failures classified, 3 fixes drafted, 4 escalated
## In progress
- claude/fix-auth-token-refresh — tests passing locally, awaiting CI
- claude/fix-flaky-payment-webhook — retry pattern applied, monitoring
## Completed today
- claude/bump-axios-1.7.4 → merged (CI green, deps loop verified)
- claude/lint-fix-pass-june-9 → merged
## Escalated to humans
- src/billing/refund.ts — tests failing in 3 ways, root cause unclear
- ci/staging-runner — infra timeouts, not a code issue
## Lessons learned (write here, not in chat)
- 2026-06-08: PowerShell hits TLS 1.2 issue on this Windows runner. Use bash.
- 2026-06-07: tests/e2e/checkout requires Stripe webhook secret in env. Skip if missing.
## Stop conditions met since last review
- /goal “all tests pass + lint clean” achieved on commit 3a7b8c1 at 02:14 UTC
状态文件存放位置的两种模式:
- 仓库内的 Markdown——在根目录或
.claude/内放置STATE.md。版本控制。简单。可读 diff。最适合单人开发或小团队。 - 外部系统(Linear、GitHub Issues、数据库)——跨仓库存活,可查询,支持团队层面的可视化。最适合生产环境中的循环,这种情况下需要多个人了解循环在做什么。
对于存在偏离目标风险的长运行循环,将状态文件与一个常设的高层规范(VISION.md 或 AGENTS.md)配对,让 agent 每次运行重新阅读。状态告诉 agent 当前所在位置。规范告诉它该往哪里去。
11. The minimum viable loop.
If you passed the 4-condition test in step 2, build the smallest loop that works before anything fancy. Four parts, no swarm.

The four parts, in plain language:
- One automation. A scheduled run that fires on a cadence and stops on a clear condition. Use /loop in Claude Code or an automation in Codex. Pair with /goal when you want it to run until a stated condition holds.
- One skill. A single SKILL.md that stores the project context the agent would otherwise re-derive from zero every run.
- One state file. A markdown file or a Linear board that records what is done and what is next. Tomorrow’s run resumes instead of restarting.
- One gate. The test, type check, or build that fails bad work automatically. This is the part that decides whether the loop helps or just spends. Order matters: get one manual run reliable first. Turn it into a skill. Wrap it in a loop. Then schedule it. Skipping ahead is how loops fail in production.
The metric that matters is cost per accepted change - not tokens spent, not tasks attempted, not loops scheduled. If your accepted-change rate is below 50% you’re doing review work the loop saved you from, and the loop is losing.
11. 最小可行循环。
如果你通过了第二步的四条件测试,那么先构建一个能工作的最小循环,不要一上来就搞花哨的东西。只需要四个部件,不需要 swarm。
用简单的语言说明这四个部件:
- 一个自动化。按固定节奏触发并在明确条件满足时停止的调度运行。在 Claude Code 中使用
/loop,或在 Codex 中使用自动化功能。当你想让它一直运行直到指定条件成立时,配合/goal使用。 - 一个 skill。一份
SKILL.md文件,存放 agent 每次运行本需从零重新推导的项目上下文。 - 一个状态文件。一个 markdown 文件或 Linear 看板,记录已完成和待办事项。明天的运行将从断点处恢复,而不是从零开始。
- 一个关口。测试、类型检查或构建,能自动对不良输出给出失败判定。这部分决定了循环是在帮忙,还是在单纯消耗资源。
顺序很重要:先让一次手动运行稳定可靠。然后将其转化为 skill。再把它包装进循环。最后才安排调度。跳过这些步骤,正是循环在生产环境失败的根源。
真正重要的指标是每次被接受的变更所花费的成本——而不是消耗的 token 数量、尝试的任务次数或安排了多少循环。如果你的变更接受率低于 50%,你就在做本应由循环帮你节省的审查工作,而这个循环正在亏本。
12. The Ralph Wiggum loop. Loops that fail quietly.
Engineer Geoffrey Huntley documented this failure mode and named it. An agent meant to emit a completion token only when finished emits it early, and the loop exits on a half-done job. Without a hard gate, loops fail quietly and keep spending.

The Ralph Wiggum loop is what happens when:
- No real verifier. Just a second agent asked to “review,” no objective signal. Two optimists agreeing.
- Soft completion conditions. “Done” defined by the agent’s judgment, not by a test, build, or type check.
- No hard stops. Loop continues until something external kills it (rate limit, you noticing) rather than until success is verified. The fix is the gate from step 11 - something objective that can fail the work. A test that passes or fails. A build that compiles or doesn’t. A linter that returns zero or non-zero. Not a verifier that has an opinion.
Other measured failure modes worth knowing:
- Goal drift over long sessions. Each summarization step is lossy; “don’t do X” constraints disappear at turn 47. Mitigation: a standing VISION.md or AGENTS.md reread each run.
- Self-preferential bias. The agent that wrote the code is too nice grading its own homework. Mitigation: a separate verifier subagent with no exposure to the maker’s reasoning.
- Agentic laziness. The loop declares “done enough” at partial completion. Mitigation: /goal with an objective stop condition checked by a fresh model.
12. Ralph Wiggum 循环:悄无声息地失败。
工程师 Geoffrey Huntley 记录并命名了这种失败模式。一个本应只在完成时发射完成信号的 agent 提前发射了信号,导致循环在一半工作尚未完成时就退出了。没有硬性关口,循环就会静默失败,同时持续消耗资源。
Ralph Wiggum 循环的典型特征如下:
- 没有真正的验证器。仅仅让第二个 agent 去“审查”,缺乏客观信号。两个乐观主义者达成了共识。
- 模糊的完成条件。“完成”由 agent 的判断来定义,而不是由测试、构建或类型检查来定义。
- 没有硬性终止条件。循环一直运行,直到外部因素(如速率限制、你注意到)来终止它,而不是直到成功被验证。
解决方案就是第 11 步中的关口——某个能客观判定工作失败的机制。一个通过或不通过的测试。一个编译成功或失败的构建。一个返回零或非零的 linter。不是一个有自己看法的验证器。
其他值得了解的已知失败模式:
- 长时间会话中的目标漂移。每一次摘要步骤都会丢失信息;“不要做 X”这样的限制在 47 轮后就会消失。缓解办法:一个每次运行都重新阅读的常设
VISION.md或AGENTS.md。 - 自我偏好偏误。编写代码的 agent 对自己的作业过于仁慈。缓解办法:一个独立的验证子 agent,不接触制造者的推理过程。
- 代理懒惰。循环在部分完成时就宣布“做得够好了”。缓解办法:使用
/goal搭配一个由全新模型检查的客观停止条件。
13. Comprehension debt and cognitive surrender.
This is the failure mode that gets sharper as the loop gets better, not worse. Two named risks, both from Osmani’s essay:
-
Comprehension debt. The faster the loop ships code you didn’t write, the larger the distance between what the repository contains and what you understand. The bill that hurts is not the token bill. It is the day you have to debug a system no one on the team has read.
-
Cognitive surrender. The pull to stop forming an opinion and accept whatever the loop returns. Designing the loop is the cure when you do it with judgment and the accelerant when you do it to avoid thinking. Same action, opposite result. The mitigations are not technical:
-
Read the diffs. If you don’t read what the loop ships, you’re renting comprehension debt at compound interest.
-
Spot-check the gate. Pick a few PRs the loop opened and verify the test that approved them actually catches the failure mode you care about. Gates rot.
-
Block the loop from architecture work. Keep it on small, machine-checkable changes. The moment you let it touch judgment calls, comprehension debt accelerates.
-
Pair-design loops with a teammate. A second pair of eyes when designing the loop catches blind spots the loop will exploit forever otherwise.
13. 理解债务与认知放弃。
这是一种随循环变好而变得更尖锐的失败模式,而非变差。两个明确的风险均来自 Osmani 的文章:
- 理解债务。循环交付你不曾编写的代码速度越快,仓库实际内容与你理解之间的鸿沟就越大。真正让人受伤的账单不是 token 消耗,而是有天你不得不调试一个团队中无人曾阅读过的系统。
- 认知放弃。你倾向于不再形成自己的判断,而是接受循环返回的任何结果。当你带着判断力去设计循环时,它是解药;当你为了逃避思考而去设计循环时,它就成了催化剂。同样的动作,相反的结果。
缓解方法并非技术性手段:
- 阅读 diff。如果你不阅读循环交付的内容,你就是在以复利的方式租借理解债务。
- 抽检关口。随机挑选几个循环打开的 PR,验证批准它们的测试是否真的捕获了你关心的失败模式。关口是会退化的。
- 禁止循环触碰架构工作。把它限制在小型、可机器检查的变更上。一旦让它触及需要主观判断的工作,理解债务就会加速累积。
- 与队友结对设计循环。设计循环时多一双眼睛,能发现那些循环日后会永久利用的盲点。
14. The security tax. An unattended loop is an unattended attack surface.
A loop running unattended is also an attack surface running unattended.
The threat model your loop has to defend against:
- Generated code shipping unreviewed. The loop opens PRs faster than a human can read them. Without a gate that includes security checks (SAST, dependency audit, secret scanning), insecure code merges automatically.
- Skills as injection vectors. A loop that auto-installs skills inherits every prompt injection hiding in their descriptions. Audit skill sources before installing.
- Credentials in logs. Debug logging during a long-running loop scatters secrets across logs you don’t monitor. Disable verbose logging in production loops; sanitize what does get logged.
- Permission scope creep. A loop tested with read-only permissions gets “just one” write permission added for convenience, then never re-audited. Re-audit permissions every 30 days.
14. 安全税:无人值守的循环就是无人值守的攻击面。
一个无人值守运行的循环,同时也是一个无人值守的攻击面。
你的循环需要防御的威胁模型包括:
- 未审查的生成代码直接上线。循环打开 PR 的速度比人类阅读它们更快。如果关口不包含安全检查(SAST、依赖审计、机密扫描),不安全的代码会自动合入。
- Skill 作为注入向量。一个自动安装 skill 的循环会继承隐藏在其描述中的每一条提示注入。安装前请审计 skill 的来源。
- 日志中的凭据泄露。长时间运行的循环中的调试日志会将其散落到你并不监控的日志中。在生产环境的循环中禁用详细日志;对确实需要记录的内容进行脱敏处理。
- 权限范围逐步扩大。一个用只读权限测试过的循环,为了便利添加了“仅仅一个”写入权限,之后从未重新审计。请每 30 天重新审计一次权限。
§ The mistakes that turn loops into money pits
- Building a loop without running the 4-condition test. Step 2 exists for a reason. Most developers fail at least one condition.
- No objective gate. A second agent asked to “review” without a test, type check, or build is just a second optimist.
- One agent doing both writing and verifying. Self-preferential bias. The maker grades its own homework and it’s always “A+.”
- No state file. Tomorrow’s run restarts from zero instead of resuming.
- Vague stop conditions. “Done when it looks good” never holds. Use a test, a type pass, or a passing build.
- No token budget cap. Loops re-read context and retry. Without a cap, ambitious loops burn 5-10× the tokens you expected.
- Running loops on a consumer plan with heavy verification. Token bill or rate limit, one of them gets you.
- Auto-installing community skills. 520 of 17,022 audited skills leak credentials. Read the source before installing.
- Loops on judgment-call work. Architecture, auth, payments, vague product decisions. Keep the loop on lint-and-fix, not strategy.
- Not reading the diffs. Comprehension debt at compound interest. The day you debug a system no one has read costs more than the tokens ever did.
§ 导致循环变成吞金兽的常见错误
- 不运行四项条件测试就构建循环。第 2 步存在是有原因的。大多数开发者至少会 fail 一个条件。
- 没有客观关口。仅仅让第二个 agent“审查”而没有测试、类型检查或构建,不过是多了第二个乐观主义者。
- 同一个 agent 既编写又验证。自我偏好偏误。制造者给自己的作业打分,永远得“A+”。
- 没有状态文件。明天的运行将从零重启,而不是恢复。
- 模糊的停止条件。“看起来没问题就完成”从未真正成立。请用一个测试、类型检查通过或构建通过来定义。
- 没有 token 预算上限。循环会重读上下文、重试。没有上限,好高骛远的循环可能会消耗你预期的 5 到 10 倍的 token。
- 在消费套餐上运行需要大量验证的循环。token 账单或速率限制,总有一项会击中你。
- 自动安装社区 skill。受审计的 17,022 个 skill 中有 520 个泄露了凭据。安装前请阅读源代码。
- 对需要主观判断的工作运行循环。架构、认证、支付、模糊的产品决策。请让循环专注于 lint 修复,而不是策略制定。
- 不阅读 diff。按复利增长的理解债务。有一天你调试一个无人阅读过的系统所付出的代价,远超你曾支付的任何 token 费用。
Conclusion:
The leverage moved. Your job did too.
For two years, the leverage in working with coding agents was at the prompt. Better prompts, better context, better one-shot output.
That phase is ending. The agents got good enough that the next leverage point is one floor up: the system that decides what they work on, when, with what gate, and what state survives between runs.
But the honest version of this story is not that everyone should rush to build loops. Most developers don’t need one yet - not until the task repeats, verification is automated, the budget can absorb the waste, and the agent has senior engineer tools.
Miss one condition and the loop costs more than it returns.
If you pass the test, build small. One automation. One skill. One state file. One gate. Get a manual run reliable. Turn it into a skill. Wrap it in a loop. Then schedule it. Order matters. Skip ahead and you’re paying for a system no one understands.
Cherny’s point isn’t that the work got easier. It’s that the leverage point moved. Build the loop. Stay the engineer.
结论:
杠杆已转移,你的角色也已改变。
两年来,与编码 agent 协作的杠杆在于提示本身。更好的提示、更完整的上下文、更精准的一次性输出。
这个阶段正在结束。agent 已经足够优秀,以至于下一个杠杆点在其上一层:一个决定它们该做什么、何时做、用什么关口、以及哪些状态在运行之间得以持久保存的系统。
但诚实的版本并非人人都应争相构建循环。大多数开发者目前还不需要——只有当任务可重复、验证已自动化、预算能承受浪费、且 agent 拥有高级工程师工具时,才应考虑。
缺失任何一个条件,循环都会得不偿失。
如果你通过了测试,从小处着手。一个自动化。一个 skill。一个状态文件。一个关口。先让一次手动运行稳定可靠。然后将其转化为 skill。再把它包装进循环。最后才安排调度。顺序至关重要。跳过这些步骤,你就是在为一个无人理解的系统付费。
Cherny 想说的不是工作变容易了。而是杠杆点发生了转移。构建循环,继续做那个工程师。