Practical Guide to Setting Up a Local Coding Agent Stack with Open-Weight Models
This is a step-by-step tutorial for building a fully local coding agent using open-weight LLMs (primarily Qwen3.6 35B-A3B) served via Ollama and the Qwen-Code harness. The author covers model selection, speed/memory benchmarking with a custom script, a small agent capability evaluation (5 tasks), and a security audit checklist before running any harness. It then compares the same local model across three harnesses—Qwen-Code, Codex (open-source), and Claude Code—finding that Codex achieves the same task success rate with roughly half the token usage of Claude Code. The guide also explains SSH tunneling to run the model on a dedicated machine (e.g., DGX Spark) while using the harness on the main workstation. Targeted at engineers comfortable with the CLI who want a transparent, inspectable, and free alternative to proprietary coding agents.
Many people reached out to me in the past asking about my local agent stack as well as how I set up my local agent stack.
So, I thought it might be useful to put together a little tutorial on how to set up a local (coding) agent using open-source tools and open-weight LLMs.
过去很多人问我本地代理栈是什么,以及我具体是如何搭建的。 因此,我想写一篇教程,介绍如何使用开源工具和开放权重大语言模型(LLM)搭建一个本地编码代理。
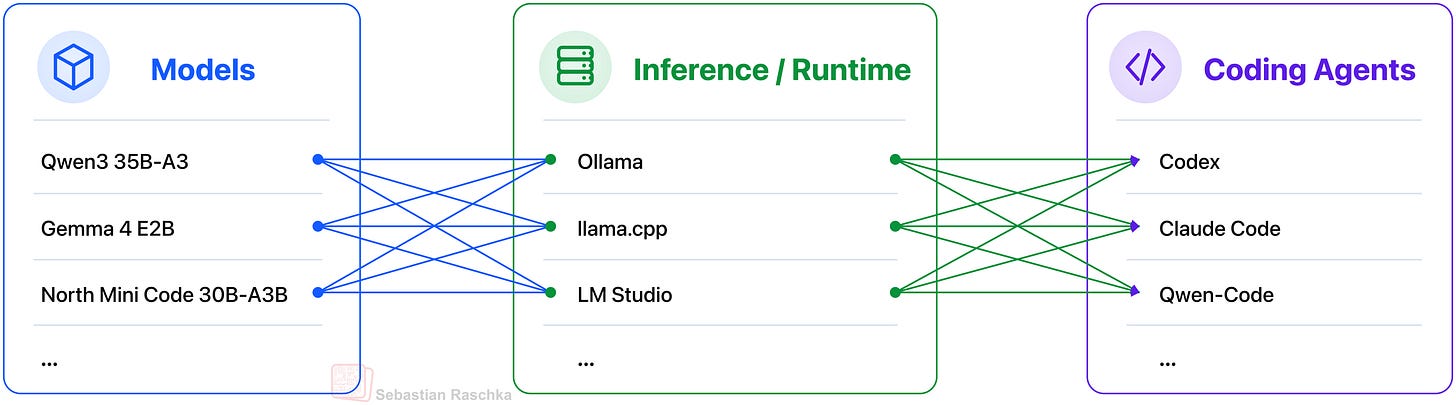
Figure 1: Overview of the local stack, that is, a coding agent harness that uses a local model hosted through an inference engine / runtime server.
This article is a tutorial on setting up a production-ready coding agent with a fully local stack. We will use a locally served LLM together with a local coding harness that can read files, make edits, run commands, and verify changes as shown in the figure above.
Here, we can think of the LLM as the engine that provides the reasoning and code generation. And the surrounding harness provides the operating environment that allows the LLM to do meaningful coding work in our local projects.
图 1:本地栈概览——一个编码代理框架,利用推理引擎/运行时服务器托管的本地模型。
本文是一篇教程,教你如何搭建一个可用于生产环境的全本地编码代理。我们将使用本地托管的 LLM,并结合一个本地编码框架,它能够读取文件、进行编辑、运行命令并验证变更,如上图所示。 在此架构中,LLM 相当于引擎,负责推理和代码生成;而围绕它的框架则提供了操作系统,让 LLM 能在本地项目中进行有意义的编码工作。
Why local? For many coding workflows, a local setup is an interesting alternative to proprietary services such as GPT in Codex or Opus in Claude Code. The local setup is transparent, inspectable, and free to run apart from hardware and electricity costs. It also stays fully under your control, and you can modify the coding harness in any way you like. Plus, it’s a lot of fun!
为什么要用本地方案?对许多编码工作流来说,本地搭建是一个很有意思的替代方案,可以代替 GPT in Codex 或 Opus in Claude Code 等专有服务。本地方案透明、可审查,除了硬件和电费外,运行成本为零。它完全在你的掌控之中,而且你可以随意修改编码框架。另外,这个过程也很有趣!
By the way, in case you want a bit more background information on coding agent harnesses, I covered the core components of coding agents (and building a coding agent from scratch for learning purposes) here:
I have to admit that I still primarily alternate between Codex and Claude Code as my daily drivers, for now (and just to keep up with the new tooling and functions that are constantly being added). Also, the plan limits (especially for Codex) are still so generous that I haven’t had to worry about costs so far.
However, I’ve been using local solutions for a while, too, to test things and because it somehow gives me joy to have and use a fully local setup (versus proprietary services).
顺便提一句,如果你想了解更多关于编码代理框架的背景信息,我之前已经介绍过编码代理的核心组件(以及为了学习目的从头构建一个编码代理的方法),请参考这里。
我必须承认,目前我日常工作中主要还是交替使用 Codex 和 Claude Code(也是为了跟上不断新增的工具和功能)。而且,这些服务的订阅限制(尤其是 Codex)仍然相当宽松,所以到目前为止我还没担心过成本问题。 不过,我也一直在使用本地解决方案来测试新东西,并且不知为何,拥有并使用一套完全本地的方案(而非专有服务)让我感到愉悦。
Either way, local solutions become more and more attractive each day. One aspect is the costs. If you have the hardware, they are practically free to run. And then there’s, of course, the privacy angle. For example, for organizing and processing my receipts, I’d be more comfortable with a local model ingesting them rather than sending the data over to OpenAI or Anthropic.
(Then, if we keep in mind that Anthropic was recently throttling their flagship model’s performance for LLM research, proprietary services may become more restrictive over time, and it’s maybe a good idea to be comfortable with open-weight alternatives as a backup.)
And there are many, many additional reasons and use cases like that.
无论如何,本地解决方案每天都变得越来越有吸引力。一方面是成本:只要你有硬件,运行它们几乎不花钱。当然还有隐私方面的考量。例如,在处理和组织我的收据时,我更愿意让本地模型来消化这些数据,而不是将其发送给 OpenAI 或 Anthropic。 (此外,如果我们还记得 Anthropic 最近为了 LLM 研究而对其旗舰模型进行性能限制,那么专有服务可能会随着时间的推移变得更加严格,因此熟悉开放权重模型作为备选或许是个好主意。) 还有很多很多类似的原因和用例。
Your motivations for using local LLMs and coding harnesses may include:
Predictable, fixed costs if you reach your subscription plan limits, and immunity to API price changes.
Reproducibility; sometimes it's nice if a model is upgraded (e.g., GPT 5.4 -> GPT 5.5 -> GPT 5.6) and it solves all your queries more reliably. However, this can also break existing workflows.
Offline use in the classic airplane flight scenario with slow or no internet, or when going on a coding/writing retreat in the cabin in the woods w/o a Starlink subscription.
And there are probably several others.
你使用本地 LLM 和编码框架的动机可能包括: · 当达到订阅计划限制时,成本可预测且固定,并且不受 API 价格变动的影响。 · 可复现性;有时模型升级(如 GPT 5.4 → GPT 5.5 → GPT 5.6)后能更可靠地解决所有查询,固然不错,但这也可能破坏现有的工作流。 · 离线使用:比如在经典的飞机场景中,网络慢或没有网络;或者去没有 Starlink 订阅的林中小屋进行编码/写作静修时。 可能还有其他一些原因。
So, in this article, we will set up and use popular harnesses like Codex and Claude Code with open-weight models and investigate whether using a model-specific harness (like Qwen-Code for Qwen3.6) brings any additional benefits. (Of course, there are many more harnesses like OpenCode, Cline, Pi, and Noumena Code, but I thought that most people already have muscle memory with either Codex or Claude Code, which makes switching to open-weight models a bit smoother).
Most coding agent harnesses follow similar principles and have more or less the same features and functionality. However, the implementation details may differ, and certain LLMs have usually been primarily optimized for a specific harness. Of course, many open-weight LLMs like GLM 5.2, for example, would run Claude Code, etc.
However, if an LLM developer also develops a coding harness, it is somewhat safe to assume that their model is optimized for their own harness first (while also supporting others).
Here, I am primarily going to use Qwen3.6 with the Qwen-Coder coding client. However, I will also go over other options for using a local LLM with other agent harnesses, for example, Claude Code, Codex, and the increasingly popular Cline, but more on that later.
因此,在本文中,我们将搭建并使用 Codex 和 Claude Code 等流行框架来搭配开放权重模型,并探究使用特定于模型的框架(如针对 Qwen3.6 的 Qwen-Code)是否能带来额外好处。(当然,还有很多其他框架,如 OpenCode、Cline、Pi 和 Noumena Code,但我认为大多数人已经对 Codex 或 Claude Code 形成了肌肉记忆,这会使切换到开放权重模型的过程更平滑。) 大多数编码代理框架遵循相似的原理,拥有大致相同的特性和功能。然而,实现细节可能有所不同,而且通常某些 LLM 会主要针对某一种框架进行优化。当然,许多开放权重 LLM,例如 GLM 5.2,也能在 Claude Code 中运行。 不过,如果一个 LLM 的开发者同时也开发了一个编码框架,那么有理由认为他们的模型会首先针对自家框架进行优化(同时也会支持其他框架)。 在本文中,我将主要使用 Qwen3.6 搭配 Qwen-Coder 编码客户端。不过,我也会讨论使用其他代理框架(如 Claude Code、Codex 以及越来越流行的 Cline)搭配本地 LLM 的选项,稍后会详细说明。
The reason why I am primarily using Qwen-Code when working with Qwen models is that:
it is open-source, like Codex (https://github.com/openai/codex) but unlike Claude Code;
Qwen models have been specifically optimized for the Qwen-Code harness (more information below);
I can run both Codex (with the latest GPT model) and Qwen-Code with a local Qwen model side by side on the same machine without having to switch manually back and forth between models.
我使用 Qwen 模型时主要选择 Qwen-Code,原因如下: · 它是开源的,和 Codex(https://github.com/openai/codex)一样(但 Claude Code 不是); · Qwen 模型已经针对 Qwen-Code 框架进行了专门优化(详情见下文); · 我可以在同一台机器上同时运行 Codex(搭配最新的 GPT 模型)和 Qwen-Code(搭配本地 Qwen 模型),无需手动来回切换模型。
Regarding the second point in the list above, that Qwen models work better in Qwen-Code, Nvidia's Polar: Agentic RL on Any Harness at Scale paper (May 2026) has a benchmark showing that the Qwen3.5-4B base model has the best coding performance in said Qwen-Code harness (both before and after their Polar-RL training), which I included below.
The benchmark in the table above is for an older Qwen3.5 model, and I am assuming that the latest Qwen3.6 models are even further optimized to do well in Qwen-Code specifically.
However, Pi (https://github.com/earendil-works/pi) also seems to be a very interesting candidate that I need to play around with in the future.
关于上面第二点——Qwen 模型在 Qwen-Code 中表现更好,Nvidia 的论文《Polar: Agentic RL on Any Harness at Scale》(2026 年 5 月)中有一个基准测试表明,Qwen3.5-4B 基础模型在 Qwen-Code 框架中(无论是在 Polar-RL 训练前还是训练后)的编码性能都是最好的,如下图所示。 上表中的基准测试针对的是较旧的 Qwen3.5 模型,而我假设最新的 Qwen3.6 模型会针对 Qwen-Code 进行更深入的优化。 不过,Pi(https://github.com/earendil-works/pi)看起来也是一个非常有趣的候选,我将来需要好好研究一下。
By the way, Qwen3.6 35B-A3B is about 22 GB to download, requires roughly 30-40 GB of RAM, and runs pretty swiftly on both a Mac Mini with M4 and a DGX Spark.
Based on the recent benchmarks shared by Cohere earlier in June, it is currently the best local model in its size class.
As seen above, Qwen3.6 35B-A3B dominates all but one benchmark in this size class. However, that being said, Qwen Code is a general harness and also supports other types of models. For instance, we could also connect North Mini Code or Gemma 4 in Qwen Code.
顺便提一下,Qwen3.6 35B-A3B 的下载大小约为 22 GB,大约需要 30–40 GB 的 RAM,在搭载 M4 芯片的 Mac Mini 和 DGX Spark 上运行都非常流畅。 根据 Cohere 在 6 月初分享的最新基准测试,它是目前同类尺寸中最好的本地模型。 如上图所示,Qwen3.6 35B-A3B 在该尺寸级别中几乎在所有基准测试中都占据领先地位(仅有一项例外)。不过话说回来,Qwen Code 是一个通用框架,也支持其他类型的模型。例如,我们也可以在 Qwen Code 中连接 North Mini Code 或 Gemma 4。
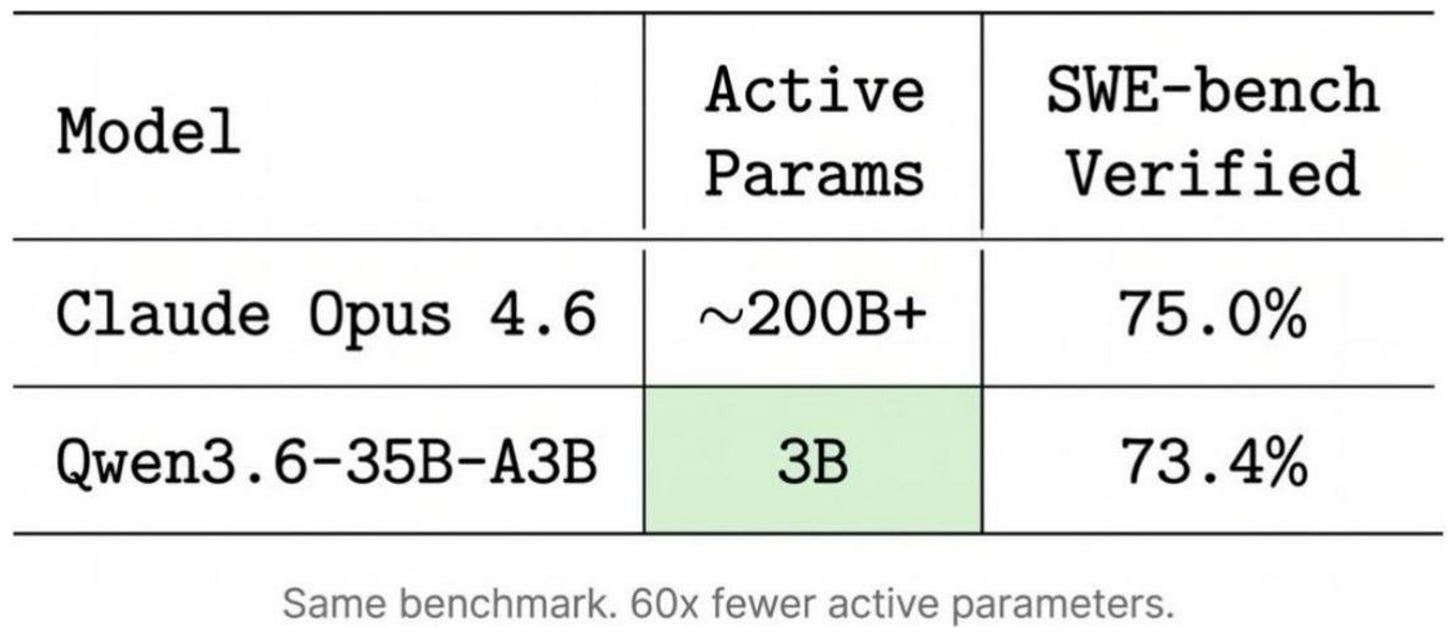
Figure 4: Yes, Qwen3.6 35B-A3B is a really good model! (Via x.com/pupposandro/status/2064707907489272147/)
Architecture-wise, the Qwen3.6 35B-A3B model has hybrid attention similar to Qwen3-Coder and Qwen3.5. I wrote more about it in Beyond Standard LLMs.
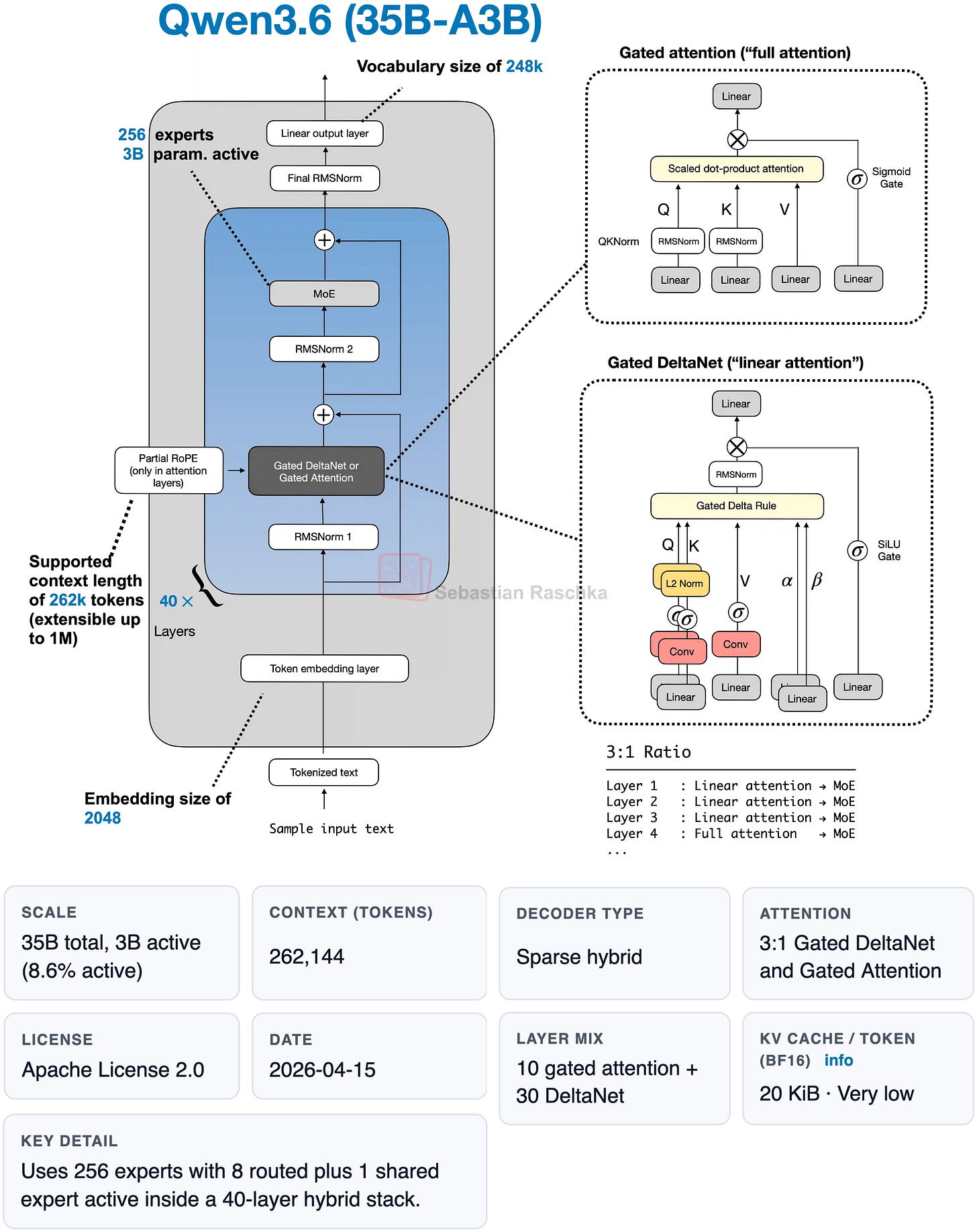
Figure 5: Qwen3.6 architecture and fact sheet from my LLM gallery.
Alternatively, if you don't want to use Qwen3.6, Cohere's North Mini Code is probably the most interesting, capable alternative at this size class right now. I will go over this model in the next local LLM setup section as well.
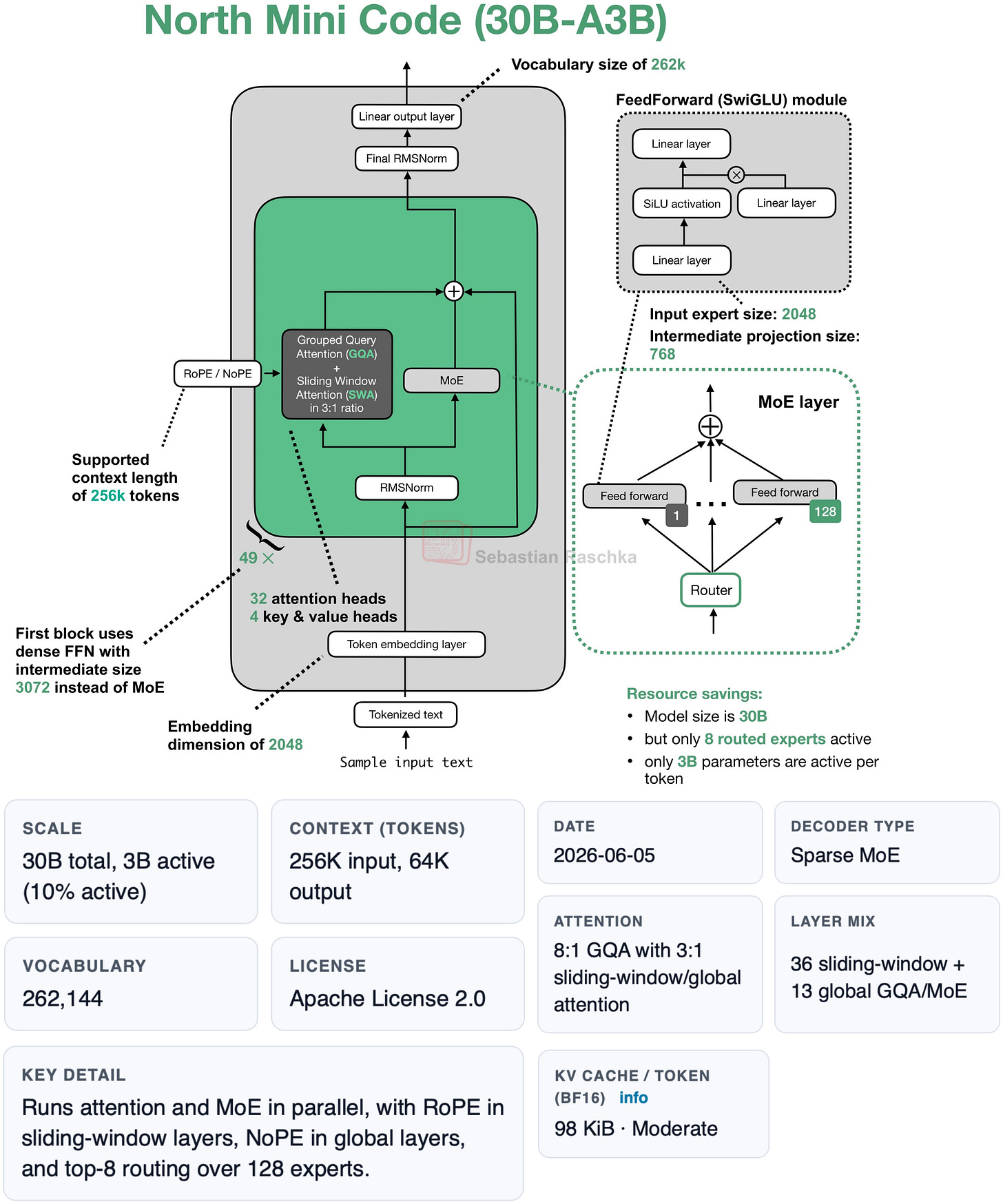
Figure 6: North Mini Code architecture and fact sheet from my LLM gallery.
图 4:没错,Qwen3.6 35B-A3B 确实是一个非常好的模型!(来源:x.com/pupposandro/status/2064707907489272147/)
在架构上,Qwen3.6 35B-A3B 采用了与 Qwen3-Coder 和 Qwen3.5 类似的混合注意力机制。我在《超越标准 LLM》一文中对此有更详细的介绍。
图 5:来自我的 LLM 图库的 Qwen3.6 架构与技术规格表。
另外,如果你不想使用 Qwen3.6,Cohere 的 North Mini Code 可能是目前同类尺寸中最有趣、能力最强大的替代品。我也会在下一节本地 LLM 设置部分介绍这个模型。
图 6:来自我的 LLM 图库的 North Mini Code 架构与技术规格表。
No matter what agent harness we use (Qwen-Code, Codex, or Claude Code), we have to set up a local LLM, such as Qwen3.6 35B-A3B, first.
There are several options like Ollama, LM Studio, vLLM, SGLang, MLX, etc to serve models locally. You know from my Build A Large Language Model (From Scratch) and Build A Reasoning Model (From Scratch) projects that I like to code these myself. Implementing a model from scratch has the benefits that we understand the whole stack, plus we can modify and further train and fine-tune it.
However, here, we just look for a model serving framework that has been super optimized for inference speed and resource needs since we don't plan to do any training or fine-tuning at this point. (We could, as an extra step, convert and import our own from-scratch fine-tuned model into these efficient serving stacks, but this is out of the scope for this article.)
For this tutorial, we will use Ollama as our efficient model serving engine because it's relatively easy to install and use from the command line across different operating systems (although LM Studio also added a non-GUI llmster client, but I am less familiar with it).
无论我们使用何种代理框架(Qwen-Code、Codex 或 Claude Code),都必须首先部署一个本地 LLM,例如 Qwen3.6 35B-A3B。 有多种选项可用于本地部署模型,如 Ollama、LM Studio、vLLM、SGLang、MLX 等。你从我的《从零构建大语言模型》和《从零构建推理模型》项目中可以知道,我喜欢自己动手编码实现这些。从头实现一个模型的好处是,我们能够理解整个技术栈,并且可以对其进行修改、进一步训练和微调。 然而,在这里,我们只是需要一个在推理速度和资源需求方面进行了超级优化的模型服务框架,因为我们目前不打算进行任何训练或微调。(作为一个额外的步骤,我们可以将我们自己从头微调的模型转换并导入到这些高效的服务栈中,但这超出了本文的范围。) 在本教程中,我们将使用 Ollama 作为高效的模型服务引擎,因为它相对容易安装,并且可以在不同操作系统上通过命令行使用(尽管 LM Studio 也添加了一个非 GUI 的 llmster 客户端,但我对它不太熟悉)。
By the way, I am not affiliated with any of the tools mentioned in this article, but one nice thing about Ollama is that they also optionally support open-weight models hosted in the cloud, including the currently strongest open-weight model, GLM 5.2, which is too large to run locally on consumer hardware. (The cloud models are not free, of course, but have similar subscription plans as ChatGPT and Claude; it's still nice though that this option exists to conveniently test the latest state-of-the-art open-weight models “locally.”)
顺便提一句,我与本文提到的任何工具都没有关联。但 Ollama 有一个好处是,它们还可选择性地支持托管在云端的开放权重模型,包括当前最强的开放权重模型 GLM 5.2(该模型太大,无法在消费级硬件上本地运行)。当然,云端模型并非免费,但其订阅计划与 ChatGPT 和 Claude 类似。不过,有这样一个选项可以方便地“本地”测试最新的最先进的开放权重模型,还是很不错的。
Anyways, setting up Ollama is pretty straightforward, and you can find the official macOS/Linux/Windows download instructions on their download page.
After installing, I recommend downloading a model for a quick test run. For instance, on macOS, we can use the ollama app to download models directly via the GUI:
Figure 7: Using the Ollama app to find and download models
Otherwise, this can be done on the command line as well via
By the way, the above-mentioned qwen3.6:35b-mlx is a model using Apple's Metal performance shaders, i.e., optimized for Macs with Apple silicon chips. I highly recommend using *-mlx versions of models working on Macs (if available).
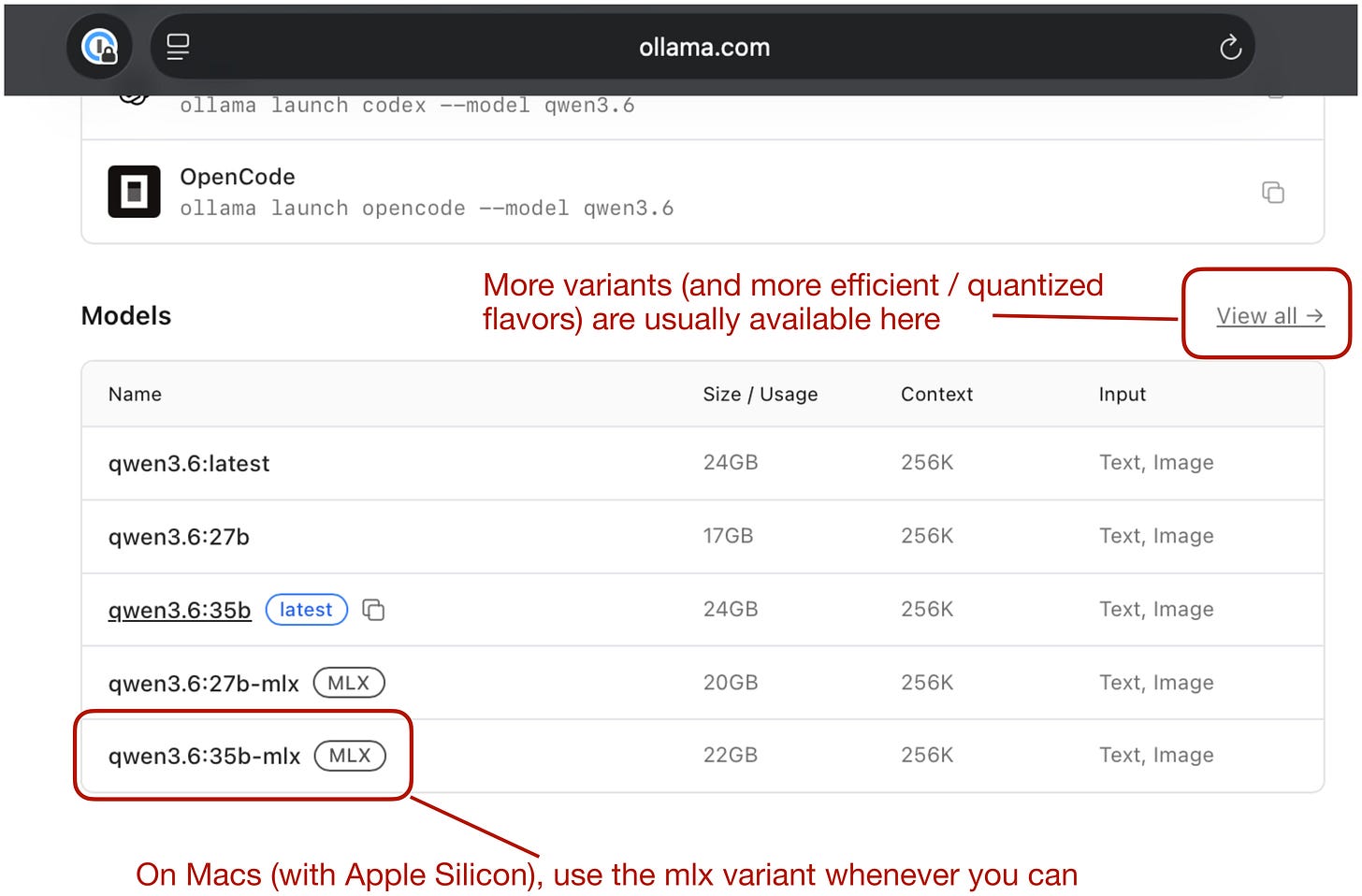
Figure 8: Prefer the MLX version when using a Mac (with an Apple Silicon chip).
On a Linux machine, use the non-MLX version:
Then, to make sure that it works, you can either use the GUI again or launch Ollama from the command line.
Figure 9: Running Ollama in the terminal.
You can exit this session via the /bye command.
无论如何,搭建 Ollama 非常简单,你可以在其下载页面上找到官方的 macOS/Linux/Windows 安装说明。
安装完成后,我建议下载一个模型进行快速测试。例如,在 macOS 上,我们可以使用 Ollama 应用程序直接通过 GUI 下载模型:
图 7:使用 Ollama 应用查找并下载模型。
当然,也可以通过命令行完成。
顺便提一下,上面提到的 qwen3.6:35b-mlx 是使用了 Apple 的 Metal 性能着色器的模型,即针对配备 Apple Silicon 芯片的 Mac 进行了优化。我强烈推荐在 Mac 上使用模型的 *-mlx 版本(如果有的话)。
图 8:在 Mac(配备 Apple Silicon 芯片)上使用时,首选 MLX 版本。
在 Linux 机器上,请使用非 MLX 版本。
然后,为了确保一切正常,你可以再次使用 GUI 或从命令行启动 Ollama。
图 9:在终端中运行 Ollama。
你可以通过 /bye 命令退出此会话。
Before deciding on whether to use an LLM as a local coding agent, it's usually not a bad idea to run a quick speed and quality assessment. Here, for the speed assessment, I would look for tokens/sec performance. Additionally, I'd also make sure this stays stable for (very) long contexts, which is what we are usually dealing with during agentic coding workflows (as opposed to simpler chatbots).
Of course, we also don't want the memory cost to explode either.
You could run my ollama_speed_memory_bench.py script to do a quick check. In a nutshell, it sends different prompts (ranging from 1k to 50k words) to an Ollama model and asks it to generate up to 8k tokens by default. It reports simple statistics like prefill speed from Ollama's prompt evaluation metrics, generation speed from output-token timing, and memory use from the Ollama process plus NVIDIA GPU memory when available.
For example, to evaluate the qwen3.6:35b-mlx on macOS, if you downloaded or cloned the scripts from https://github.com/rasbt/local-coding-agent-evals, we can run the following, which takes about 5 minutes:
On Linux, we can run:
Note that this assumes that you already downloaded the respective model as explained in the previous section. Also, depending on your system, if you have less than 30 GB RAM, you may have to use a smaller model like gemma4:e2b, which uses up to about 8 GB RAM on long contexts. Of course, there are also many smaller models, but in my experience, they make pretty bad local coding agents.)
Note that for models, the RSS RAM report is not super accurate on macOS (especially for mlx model variants that utilize the Metal backend), and I suggest keeping an eye on the activity monitor's RAM usage for Ollama during the run as well. In this case, the RAM usage fluctuated between 20 - 29 GB.
Anyways, the bottom line is that for 50k contexts, the Qwen3.6 and North Mini Code models use up to 30 GB RAM and generate output with about 40 tok/sec on a recent Mac Mini and 30 tok/sec on a DGX.
Below is a visual summary of the different runs.
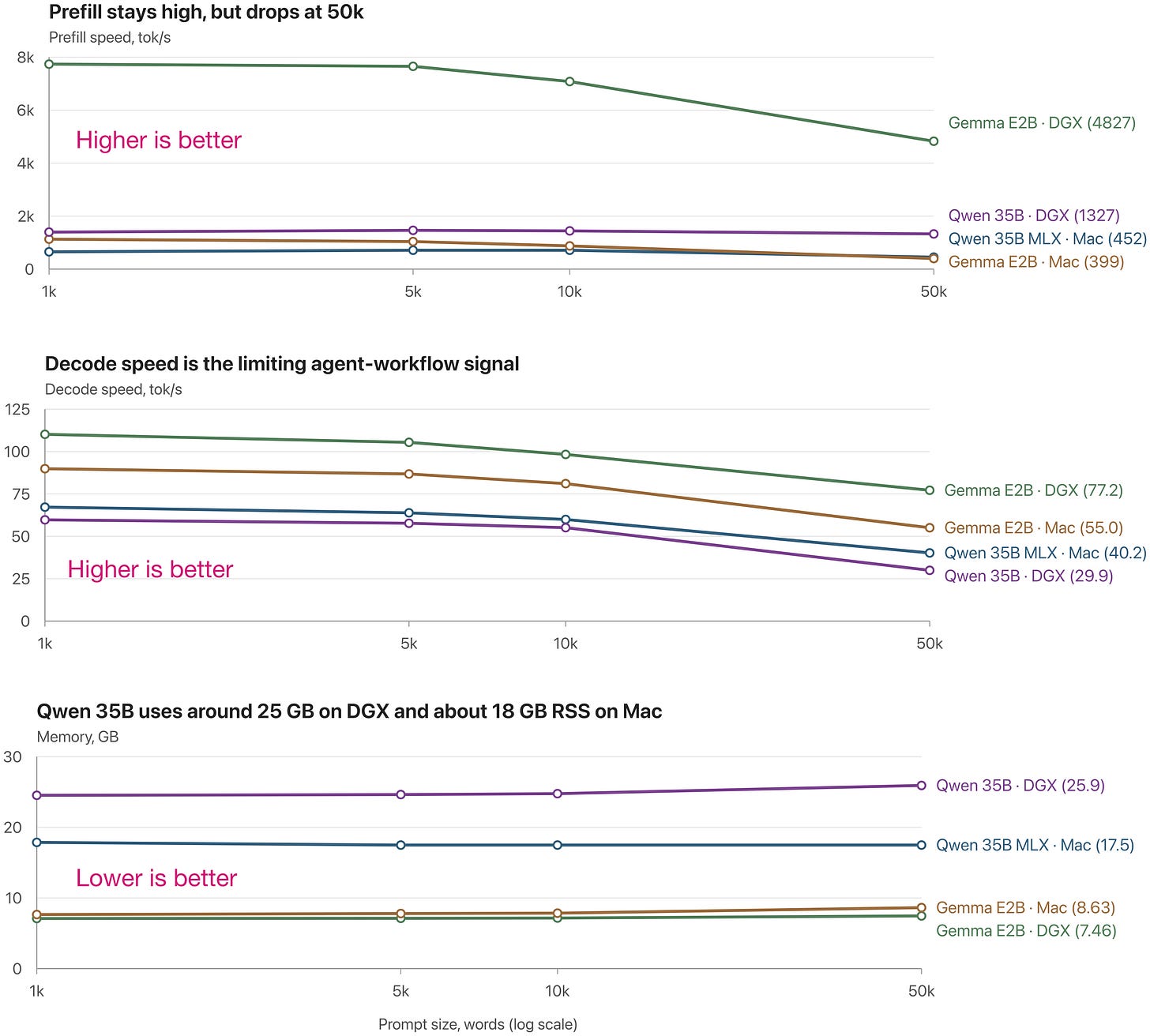
Figure 11: Quick speed comparison of the different models on different systems. Note that the macOS RAM consumption is not super accurate there. Also, note that the Qwen 35B-A3B model is faster on Mac than on the DGX Spark (which is the other way around for the Gemma 4 E2B model) thanks to the optimized MLX version. Code to reproduce: https://github.com/rasbt/local-coding-agent-evals
Another interesting question is how Qwen 35B-A3B compares to the similarly-sized Cohere North Mini model? If we take similarly quantized models into account (above, I was using the Qwen3.6 default), they are pretty similar, although North Mini is perhaps slightly ahead overall, as shown below.
Anyway, the bottom line is that, in my opinion, anything faster than 20-30 tok/sec is pretty reasonable for local agent work. This is about the same speed as GPT 5.5 with “high” reasoning. In this case, both models clear the bar easily.
By the way, personally, I run my agents almost exclusively on my DGX Spark because I don't want my Mac Mini to get too hot and I want to have the RAM available for other tasks.
Of course, there are always ways to optimize this more with different frameworks (other than Ollama), quantizations, MTP, and so on. However, Ollama is a good plug & play allrounder with minimal setup time that connects easily to various coding agent frameworks and where it's super simple to swap and try out different models.
在决定是否将一个 LLM 用作本地编码代理之前,进行快速的速度和质量评估通常是一个好主意。在速度评估方面,我会关注 tokens/秒 的性能。此外,我还会确保它在(非常)长的上下文中保持稳定,这是代理编码工作流中经常遇到的情况(与简单的聊天机器人不同)。当然,我们也不希望内存消耗激增。
你可以运行我的 ollama_speed_memory_bench.py 脚本进行快速检查。简而言之,它会向一个 Ollama 模型发送不同的提示(长度从 1k 到 50k 词汇不等),并默认要求其生成最多 8k tokens。它会报告简单的统计数据,比如来自 Ollama 提示评估指标的预填充速度、输出 token 计时的生成速度,以及来自 Ollama 进程的内存使用情况(如果有的话,还包括 NVIDIA GPU 内存)。
例如,要在 macOS 上评估 qwen3.6:35b-mlx,如果你已经从 https://github.com/rasbt/local-coding-agent-evals 下载或克隆了脚本,可以运行以下命令,大约需要 5 分钟:
在 Linux 上,我们可以运行:
请注意,这假设你已经按照上一节所述下载了相应的模型。另外,根据你的系统,如果你拥有的 RAM 少于 30 GB,你可能需要使用更小的模型,比如 gemma4:e2b,它在长上下文下大约占用 8 GB RAM。当然,还有更多更小的模型,但根据我的经验,它们作为本地编码代理表现很差。)
注意,对于模型来说,macOS 上的 RSS RAM 报告并不非常准确(特别是对于利用 Metal 后端的 mlx 模型变体),我建议在运行期间也关注活动监视器中 Ollama 的 RAM 使用情况。在这种情况下,RAM 使用量在 20–29 GB 之间波动。
无论如何,底线是:对于 50k 的上下文,Qwen3.6 和 North Mini Code 模型最多使用 30 GB RAM,在较新的 Mac Mini 上生成速度约为 40 tok/sec,在 DGX 上约为 30 tok/sec。
以下是不同运行结果的直观总结。
图 11:不同模型在不同系统上的快速速度对比。注意,macOS 上的 RAM 消耗数据并非超级准确。另外请注意,得益于优化的 MLX 版本,Qwen 35B-A3B 在 Mac 上的速度比在 DGX Spark 上快(而 Gemma 4 E2B 模型则相反)。可复现代码:https://github.com/rasbt/local-coding-agent-evals
另一个有趣的问题是,Qwen 35B-A3B 与大小相近的 Cohere North Mini 模型相比如何?如果我们考虑类似量化水平的模型(上面我用的是 Qwen3.6 的默认版本),它们非常相似,尽管 North Mini 总体上可能略微领先,如下所示。
总之,在我看来,对于本地代理工作,任何快于 20–30 tok/sec 的速度都是相当合理的。这大约与 GPT 5.5 使用“高”推理模式时的速度相同。在这种情况下,两个模型都轻松达标。
顺便提一下,我个人几乎只在 DGX Spark 上运行我的代理,因为我不想让我的 Mac Mini 过热,并且我想把 RAM 留给其他任务。
当然,总会有更多优化的方法,比如使用不同的框架(非 Ollama)、不同的量化方式、MTP 等。然而,Ollama 是一个很好的即插即用型全能工具,设置时间最短,可以轻松连接到各种编码代理框架,并且可以超级简单地切换和尝试不同的模型。
After checking that the model is fast enough for convenient local work, I recommend doing a quick modeling performance assessment. Sure, there are many standardized benchmarks out there we could take a look at and even run ourselves.
Usually, you can find the numbers for relevant benchmarks in the model's technical report or model hub page. Usually, I also find it useful to look at a relative comparison with other models on https://artificialanalysis.ai/models/.
Based on the figure above, we can see that Qwen3 35B-A3B is much more capable than the Gemma 4 E4B and E2B models, for example.
Note that the Artificial Intelligence Index numbers keep changing over time as they swap benchmarks and update the weighting, so there are no “absolute” numbers we could use as a reference point for deciding which model is “good enough”. Rather, I would compare a new, interesting model to a model you used before as an anchor or reference point.
Beyond standard benchmarks, I would also curate a personal set of tasks that are relevant to you to do a quick check whether this model is even suitable for any type of work that you might want it to perform.
在确认模型速度足够快,可以方便地进行本地工作之后,我建议进行快速的模型性能评估。当然,有很多标准化的基准测试可以参考,甚至我们自己也可以运行。 通常,你可以在模型的技术报告或模型中心的页面上找到相关基准测试的数据。我还发现,在 https://artificialanalysis.ai/models/ 上查看与其他模型的相对比较也很有用。 基于上图,我们可以看到,例如,Qwen3 35B-A3B 比 Gemma 4 E4B 和 E2B 模型的能力强得多。 请注意,人工智能指数会随着基准测试的替换和权重的更新而不断变化,因此没有可以用来判断哪个模型“足够好”的“绝对”数字。相反,我会将一个新的、有趣的模型与你之前使用过的一个模型作为锚点或参考点进行比较。 除了标准基准测试,我还会整理一套与你的工作相关的个人任务集,以快速检查这个模型是否适合你想要它执行的任何类型的工作。
Below are the outputs of a reasoning- and code-related set of questions that also test the tool calling capabilities of the models. Here, the model returns the tool call but doesn't execute the code itself.
➜ uv run ollama_hard_reasoning_bench.py --model qwen3.6:35b PASS debug_empty_tokenizer_regression: ok PASS review_shell_command_injection: ok FAIL choose_minimal_edit_for_cross_platform_path: argument instructions missing required content FAIL triage_import_error_after_refactor: wrong tool: expected read_file, got ask_clarification PASS debug_mutable_default_cache_leak: ok
Score: 3/5 passed (60.0%)
➜ uv run ollama_hard_reasoning_bench.py --model north-mini-code-1.0 FAIL debug_empty_tokenizer_regression: wrong tool: expected final_answer, got edit_file PASS review_shell_command_injection: ok FAIL choose_minimal_edit_for_cross_platform_path: invalid JSON: Extra data: line 2 column 1 (char 235) FAIL triage_import_error_after_refactor: wrong tool: expected read_file, got ask_clarification FAIL debug_mutable_default_cache_leak: wrong tool: expected final_answer, got edit_file
Score: 1/5 passed (20.0%)
uv run ollama_hard_reasoning_bench.py --model gemma4:e2b FAIL debug_empty_tokenizer_regression: wrong tool: expected final_answer, got edit_file FAIL review_shell_command_injection: wrong tool: expected final_answer, got ask_clarification FAIL choose_minimal_edit_for_cross_platform_path: wrong argument path: expected 'code/tool-reasoning-benchmark/ollama_tool_reasoning_bench.py', got 'code/tool-reasoning-benchmark/personal_tool_reasoning_tasks.jsonl' FAIL triage_import_error_after_refactor: wrong tool: expected read_file, got ask_clarification FAIL debug_mutable_default_cache_leak: wrong tool: expected final_answer, got edit_file
Score: 0/5 passed (0.0%)
以下是一组与推理和编码相关问题输出,同时也测试了模型的工具调用能力。这里,模型返回工具调用,但不会自己执行代码。 ➜ uv run ollama_hard_reasoning_bench.py --model qwen3.6:35b PASS debug_empty_tokenizer_regression: ok PASS review_shell_command_injection: ok FAIL choose_minimal_edit_for_cross_platform_path: argument instructions missing required content FAIL triage_import_error_after_refactor: wrong tool: expected read_file, got ask_clarification PASS debug_mutable_default_cache_leak: ok
得分:3/5 通过(60.0%)
➜ uv run ollama_hard_reasoning_bench.py --model north-mini-code-1.0 FAIL debug_empty_tokenizer_regression: wrong tool: expected final_answer, got edit_file PASS review_shell_command_injection: ok FAIL choose_minimal_edit_for_cross_platform_path: invalid JSON: Extra data: line 2 column 1 (char 235) FAIL triage_import_error_after_refactor: wrong tool: expected read_file, got ask_clarification FAIL debug_mutable_default_cache_leak: wrong tool: expected final_answer, got edit_file
得分:1/5 通过(20.0%)
uv run ollama_hard_reasoning_bench.py --model gemma4:e2b FAIL debug_empty_tokenizer_regression: wrong tool: expected final_answer, got edit_file FAIL review_shell_command_injection: wrong tool: expected final_answer, got ask_clarification FAIL choose_minimal_edit_for_cross_platform_path: wrong argument path: expected 'code/tool-reasoning-benchmark/ollama_tool_reasoning_bench.py', got 'code/tool-reasoning-benchmark/personal_tool_reasoning_tasks.jsonl' FAIL triage_import_error_after_refactor: wrong tool: expected read_file, got ask_clarification FAIL debug_mutable_default_cache_leak: wrong tool: expected final_answer, got edit_file
得分:0/5 通过(0.0%)
For instance, we can say that qwen3.6:35b gets the conceptual debugging and security-review tasks right, but still struggles with agentic judgment around “what file/action first” tasks. 3/5 is usable but not fully reliable for autonomous tool use. But a harness that constrains actions, adds retries, and maybe gives stronger project context could make it pretty usable.
On the other hand, gemma4:e2b failing 0/5 is a strong signal that it is less suitable for this kind of tool-use reasoning, even if it is fast. Note that the failures are not just formatting issues. It looks like it chooses the wrong tool, asks for clarification when enough context is present, etc. I would probably not use it as a coding-agent model beyond very narrow or heavily constrained tasks.
例如,我们可以说 qwen3.6:35b 能正确完成概念调试和安全审查任务,但在“先处理哪个文件/操作”这类需要代理判断的任务上仍有困难。3/5 的通过率表明它可用,但对于自主工具使用来说并非完全可靠。不过,一个能约束操作、增加重试机制,或许还能提供更强项目上下文信息的框架,可以使其相当实用。 另一方面,gemma4:e2b 以 0/5 失败,这是一个强烈的信号,表明它不太适合这种工具使用推理,即使它速度很快。请注意,这些失败不仅仅是格式问题。它看起来选择了错误的工具,或者在上下文足够的情况下要求澄清,等等。除了非常狭窄或高度受限的任务之外,我可能不会把它作为编码代理模型来使用。
Now, after this lengthy preamble setting up a local LLM, let's get back to the main topic, the coding agent harness. As mentioned at the beginning of this article, we will use the qwen-code (https://github.com/QwenLM/qwen-code) harness, as Qwen models have been optimized for it.
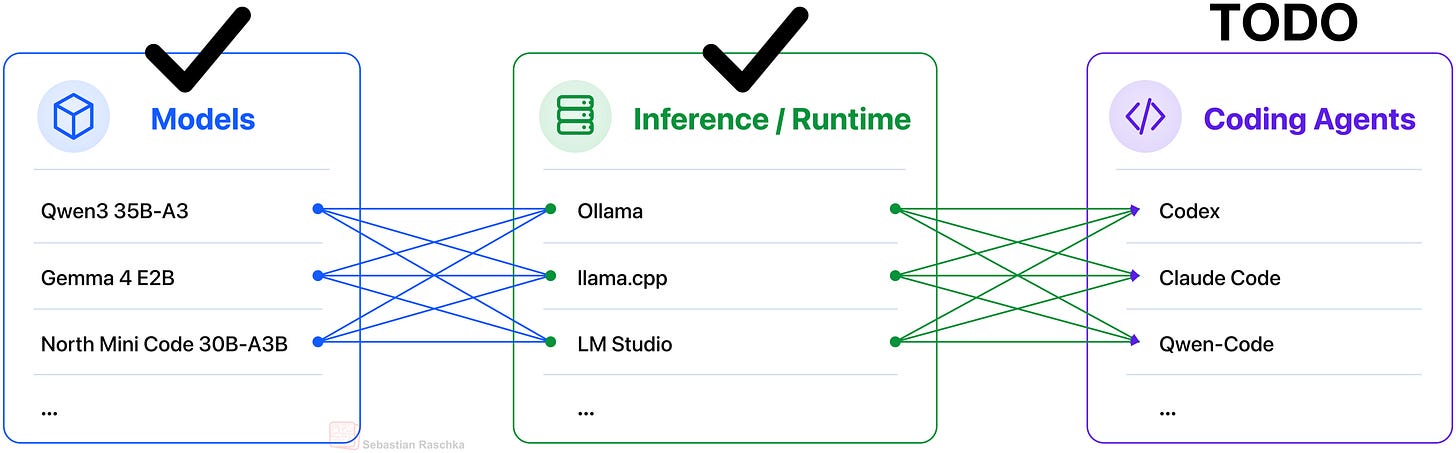
Figure 14: Next, we are trying to connect the locally served model to the coding agent harness.
If you are familiar with Claude Code, it's basically the same thing but fully open-source. However, I will also go over how to connect the local Qwen3.6 model to Codex and Claude Code in the next sections.
现在,经过前面冗长的本地 LLM 设置铺垫,让我们回到主要话题——编码代理框架。正如本文开头所述,我们将使用 qwen-code(https://github.com/QwenLM/qwen-code)框架,因为 Qwen 模型已经针对它进行了优化。
图 14:接下来,我们将尝试将本地托管的模型连接到编码代理框架。
如果你熟悉 Claude Code,这基本上是相同的概念,但 Qwen-Code 是完全开源的。不过,我将在接下来的部分中介绍如何将本地 Qwen3.6 模型连接到 Codex 和 Claude Code。
Note that coding harnesses are much more capable than LLMs by themselves. This is where I recommend being more careful about what you are running and where. For instance, when trying new (coding) agents, I like to
Do an audit of the (open-source) agent code base first.
Run it on separate hardware (e.g., my DGX Spark) or a separate user account and/or virtual environment on my machine at the very least.
Regarding the audit, I recommend looking for data sharing/egress and the default blast radius when it comes to file permissions, as well as some baseline robustness to prompt injection. The figure below attempts to summarize the main points.
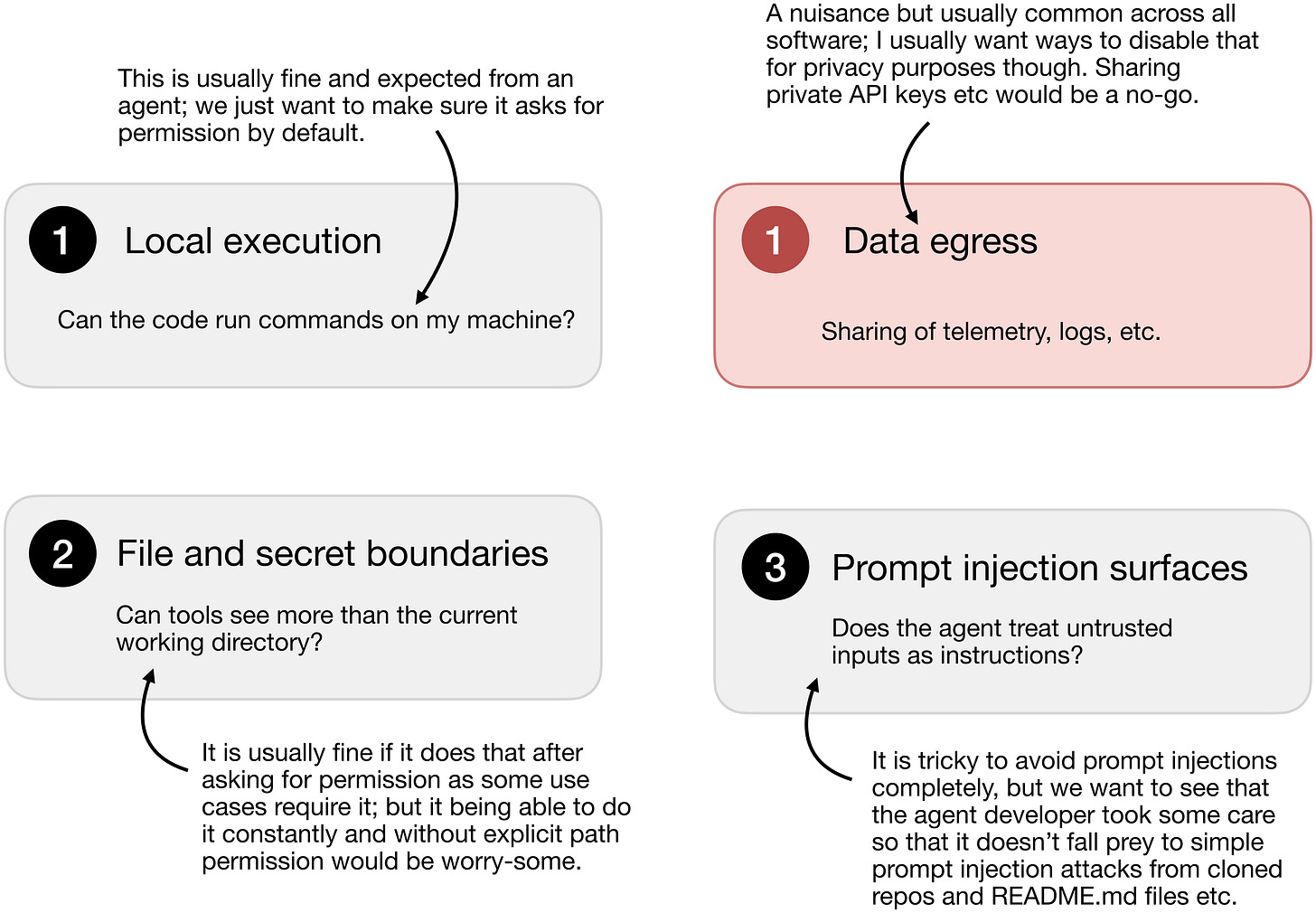
Figure 15: Practical audit checklist before running an installed coding agent harness.
Similar concerns apply to the local model serving engine (e.g., Ollama) as well. However, coding agents require even more attention as they can directly read data from your machine and manipulate files.
请注意,编码框架本身的能力远超单纯的 LLM。因此,我建议在运行它们时格外小心,无论是运行什么还是在哪里运行。例如,在尝试新的(编码)代理时,我喜欢:
· 首先对(开源)代理代码库进行审计。
· 在单独的硬件(例如我的 DGX Spark)上运行,或者至少在我的机器上使用单独的用户账户和/或虚拟环境。
关于审计,我建议关注数据共享/外传、文件权限方面的默认影响范围,以及对提示注入的一些基础鲁棒性。下图试图总结主要要点。
图 15:在运行已安装的编码代理框架之前的实用审计清单。
类似的担忧也适用于本地模型服务引擎(例如 Ollama)。然而,编码代理需要更多关注,因为它们可以直接从你的机器读取数据并操作文件。
To do a basic audit, I recommend the following:
Clone the repo:
Ask a trusted agent you used before (like GPT 5.5 in Codex or Opus 4.8 in Claude Code) to review it with a focused prompt. Something like the following:
You are auditing ./qwen-code before I install or run the agent on my machine.
Focus only on practical local-machine risk from the installed agent and the code paths that create it:
install scripts and package lifecycle hooks
shell command execution by the agent
file read/write boundaries at runtime
secret handling and environment-variable inheritance
how repo files, project instructions, and tool output can influence the agent
MCP, plugin, extension, or tool integrations
network calls and telemetry
update mechanisms after installation
terminal escape/output handling
data egress and data residency
Ignoring internet downloads that are strictly required for installation, check whether the installed agent can send prompts, files, telemetry, logs, identifiers, or metadata to remote servers when I use a local model through Ollama. Ignore cloud-model configurations.
Do not infer risk from the project owner alone. Identify concrete endpoints, SDKs, default providers, environment variables, config defaults, and docs that control network behavior, including any endpoints operated in foreign countries or by third-party companies.
Do not do broad style review. Do not refactor. Produce:
high-risk findings with file/line references
medium-risk concerns
network/data-egress findings, including any foreign, third-party, or China-linked endpoints or defaults
commands I should avoid running until reviewed
settings or environment variables that reduce local-machine risk
a short recommendation: safe to test in sandbox, safe to use, or do not run
For each item, say whether it is expected behavior for a coding agent or inherently riskier than Codex or Claude Code.
要进行基础审计,我推荐以下步骤: 克隆仓库: 使用你之前信任的代理(例如 Codex 中的 GPT 5.5 或 Claude Code 中的 Opus 4.8)并提供一个聚焦的提示来审查它。类似以下内容: “你正在审计 ./qwen-code,在我安装或运行这个代理到我的机器之前。 只关注已安装代理对其所在本地机器的实际风险以及产生风险的代码路径: · 安装脚本和包生命周期钩子 · 代理执行的 shell 命令 · 运行时的文件读/写边界 · 秘密处理和环境变量继承 · 仓库文件、项目指令和工具输出如何影响代理 · MCP、插件、扩展或工具集成 · 网络调用和遥测 · 安装后的更新机制 · 终端转义/输出处理 · 数据外传和数据驻留 忽略安装所严格需要的互联网下载,检查当我通过 Ollama 使用本地模型时,已安装的代理是否可以将提示、文件、遥测、日志、标识符或元数据发送到远程服务器。忽略云模型配置。 不要仅根据项目所有者推断风险。识别具体的端点、SDK、默认提供商、环境变量、配置默认值以及控制网络行为的文档,包括任何在外国或由第三方公司运营的端点。 不要进行广泛的风格审查。不要重构。产出: · 高风险发现(附带文件/行引用) · 中等风险问题 · 网络/数据外传发现,包括任何外国、第三方或与中国相关的端点或默认设置 · 在审查前应避免运行的命令 · 降低本地机器风险的设置或环境变量 · 简短的建议:在沙盒中测试安全、可以安全使用或不要运行 对于每一项,说明它是编码代理的预期行为,还是本质上比 Codex 或 Claude Code 风险更高。”
Below is a summary of the main findings (because the full report may be a bit boring and too long for this article):
Local execution Qwen Code can run shell commands on our machine through its shell tool but there are strict approval controls unless permissive modes such as --yolo are enabled. This is expected for a coding agent, and it's actually what makes it useful in practice. But of course it becomes risky if run unsandboxed or with a full environment containing secrets.
Data egress Even with local Ollama, Qwen Code can send usage telemetry and metadata to Alibaba/Aliyun endpoints unless usage statistics and telemetry are disabled (more on that below). This is riskier than a local-only setup because model prompts may stay local, but session IDs, tool metadata, model info, and local base URL metadata can still leave the machine. But again, this is also common among all kinds of tools (yes, Codex and Claude do that as well).
File and secret boundaries Workspace files are readable by default, while writes generally require approval and include some overwrite protections. This is good and standard agent practice.
Prompt injection surfaces Repo instructions, tool output, MCP tools, extensions, and project config can influence the agent's behavior. Prompt injection attacks can be reduced via the approval gates mentioned above. This is normal for coding agents, but untrusted repos should be treated as hostile by default because they can steer the agent toward reading files, running commands, or sending data through approved tools.
Regarding the main privacy concerns in point 2, most of it is fixable via a custom ~/.qwen/settings.json with the following contents:
The "general": { "enableAutoUpdate": false } setting is a tradeoff. Security fixes will not be installed automatically, but I prefer having explicit control over when updates happen instead of letting the tool pull and apply new code in the background.
By the way, cline (https://github.com/Cline/Cline), Codex (https://github.com/openai/codex), and Claude Code have similar telemetry data sharing defaults that would need to be disabled explicitly.
(Note that Claude Code doesn't have an official open-source version of their codebase, which makes trusting it even trickier, and it does seem to send data to both Anthropic and Datadog.)
Either way, overall, it seems Qwen-Code follows standard practices, and as of this writing, there is no particular concern that is non-standard for coding agents.
以下是主要审计发现的摘要(因为完整报告可能有些枯燥且对本文来说过长): · 本地执行:Qwen Code 可以通过其 shell 工具在我们的机器上运行 shell 命令,但有严格的审批控制,除非启用了诸如 --yolo 之类的宽松模式。这对于编码代理来说是预期的行为,实际上也是它在实践中发挥作用的原因。当然,如果在非沙盒环境中运行或带有包含秘密的完整环境,它会变得有风险。 · 数据外传:即使使用本地 Ollama,Qwen Code 也可能将使用遥测和元数据发送到阿里云/Aliyun 端点,除非禁用了使用统计和遥测(下文会详述)。这比纯本地设置风险更高,因为模型提示可能留在本地,但会话 ID、工具元数据、模型信息和本地 base URL 元数据仍可能离开机器。但再次说明,这在各种工具中都很常见(是的,Codex 和 Claude 也会这样做)。 · 文件和秘密边界:工作区文件默认可读,而写入通常需要批准并包含一些覆盖保护。这是良好的标准代理实践。 · 提示注入面:仓库指令、工具输出、MCP 工具、扩展和项目配置可能会影响代理的行为。通过上述审批关卡可以减少提示注入攻击。这对编码代理来说是正常的,但不受信任的仓库应默认被视为恶意,因为它们可以引导代理读取文件、运行命令或通过已批准的工具发送数据。 关于第 2 点中主要的隐私问题,大部分可以通过自定义 ~/.qwen/settings.json 文件并包含以下内容来解决: 设置 "general": { "enableAutoUpdate": false } 是一个权衡。安全修复不会自动安装,但我喜欢明确控制何时更新,而不是让工具在后台拉取并应用新代码。 顺便提一下,cline(https://github.com/Cline/Cline)、Codex(https://github.com/openai/codex)和 Claude Code 也有类似的遥测数据共享默认设置,需要明确禁用。 (请注意,Claude Code 没有官方开源版本的代码库,这使得信任它更加棘手,而且它似乎确实会向 Anthropic 和 Datadog 发送数据。) 无论如何,总体来看,Qwen-Code 遵循了标准实践,在撰写本文时,没有发现任何对编码代理来说非标准的特别问题。
If we accept the reported findings and risks (personally, I didn't see any red flags), we can now proceed with the installation and hook up our local Qwen3.6-35B-A3B model to Qwen Code (and Codex and Claude Code in the next sections).
As mentioned before, I preferably experiment with and run coding agents, which can read and edit local files, on a separate machine (in my case a DGX Spark, but it could also be a separate Mac or Linux workstation). Alternatively, I would run it in a VM or set up a separate macOS or Linux user account as a practical middle ground.
(I heard from some friends that they also rent servers for that, like Linode or Heroku, for tinkering purposes. However, instead of the monthly hosting costs for a somewhat capable machine, I would probably rather get a relatively cheap $200-500 hardware box, or even an old retired laptop, and run a local harness and then use a stronger open-weight model hosted in the cloud via Ollama cloud models, OpenRouter, etc if you are looking for alternatives to GPT or Claude.)
如果我们接受上述发现和风险(就我个人而言,我没有看到任何危险信号),那么现在可以继续进行安装,并将我们的本地 Qwen3.6-35B-A3B 模型连接到 Qwen Code(以及下一节中的 Codex 和 Claude Code)。 如前所述,我更倾向于在另一台机器(我的情况是 DGX Spark,但也可以是另一台 Mac 或 Linux 工作站)上实验和运行能够读取和编辑本地文件的编码代理。或者,我会在虚拟机中运行它,或者设置一个单独的 macOS 或 Linux 用户账户作为实用的折中方案。 (我听说有些朋友也会为了摆弄而租用服务器,比如 Linode 或 Heroku。然而,与其每月支付一台性能尚可的机器的托管费用,我宁愿买一台相对便宜的 200–500 美元的硬件盒子,甚至是一台旧的退役笔记本电脑,运行本地框架;然后,如果你正在寻找 GPT 或 Claude 的替代品,可以通过 Ollama 云模型、OpenRouter 等使用托管在云端的更强的开放权重模型。)
Anyways, let's install Qwen-Code. The listed options include, e.g.,
curl -fsSL https://qwen-code-assets.oss-cn-hangzhou.aliyuncs.com/installation/install-qwen-standalone.sh | bash
and
However, running the commands above assumes that the published artifacts match the code we just reviewed in the GitHub repo. If we are extra careful/paranoid, we can also build it ourselves from the GitHub repo. Be warned, this is more manual/messier though (I recommend executing them one at a time instead of copy & pasting the whole block into the terminal):
不管怎样,让我们开始安装 Qwen-Code。列出的选项包括,例如: curl -fsSL https://qwen-code-assets.oss-cn-hangzhou.aliyuncs.com/installation/install-qwen-standalone.sh | bash 以及 然而,运行上述命令假设发布的构件与我们刚刚在 GitHub 仓库中审查的代码一致。如果我们格外小心/多疑,我们也可以从 GitHub 仓库自己构建。但需要注意,这会更手动/更混乱(我建议逐个执行命令,而不是将整个代码块复制粘贴到终端中):
After completing the installation, we can now launch the Qwen-Code client via the qwen command from the terminal to complete the setup and connect to the locally served LLM.
For this, after running the qwen command, we select “Custom Provider”, as shown below.
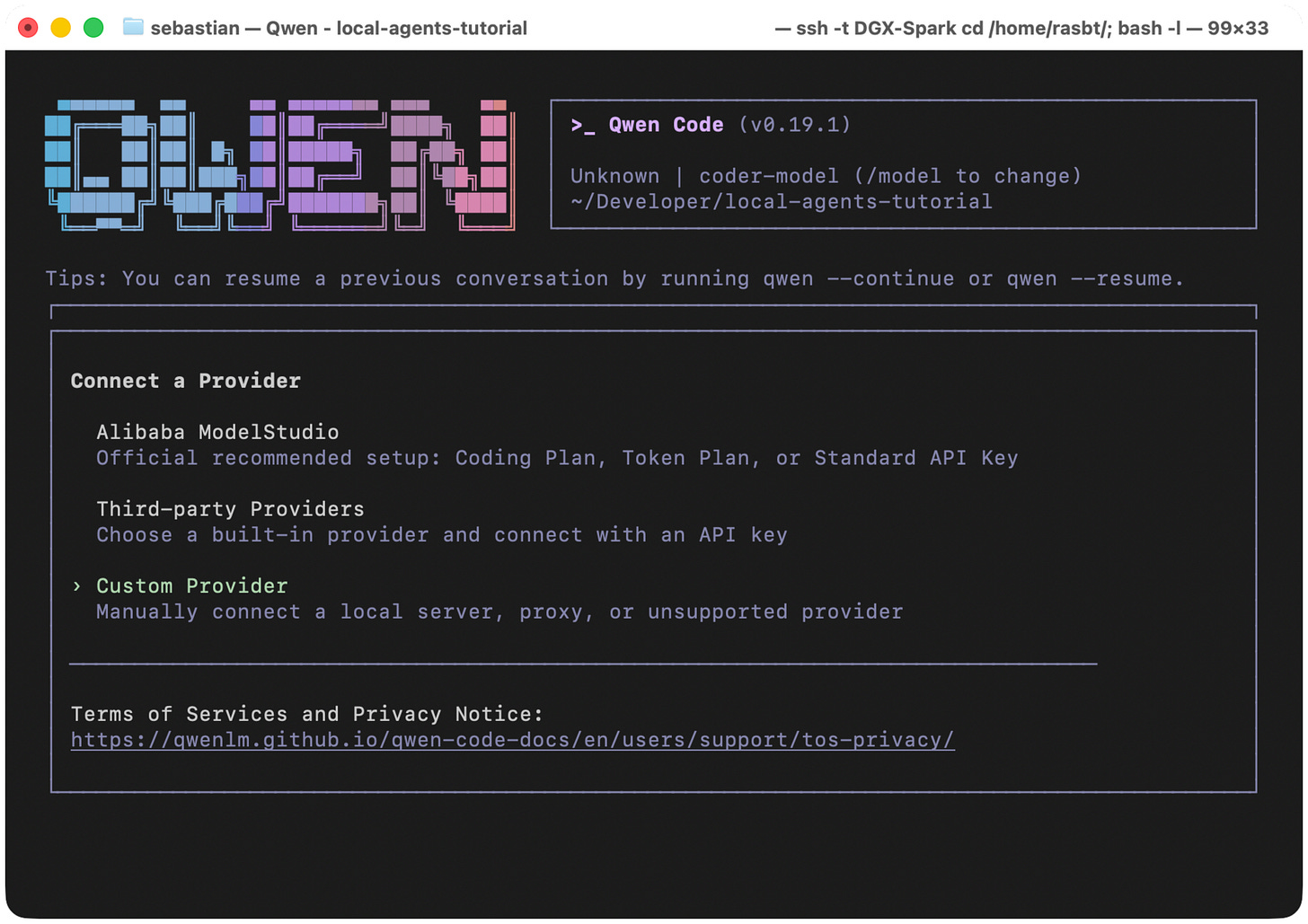
Figure 16: Choose “Custom Provider,” which lets us connect the Ollama LLM.
Ollama uses the OpenAI API standard. So, next, we follow the on-screen setup guide and choose the “OpenAI-compatible” option.
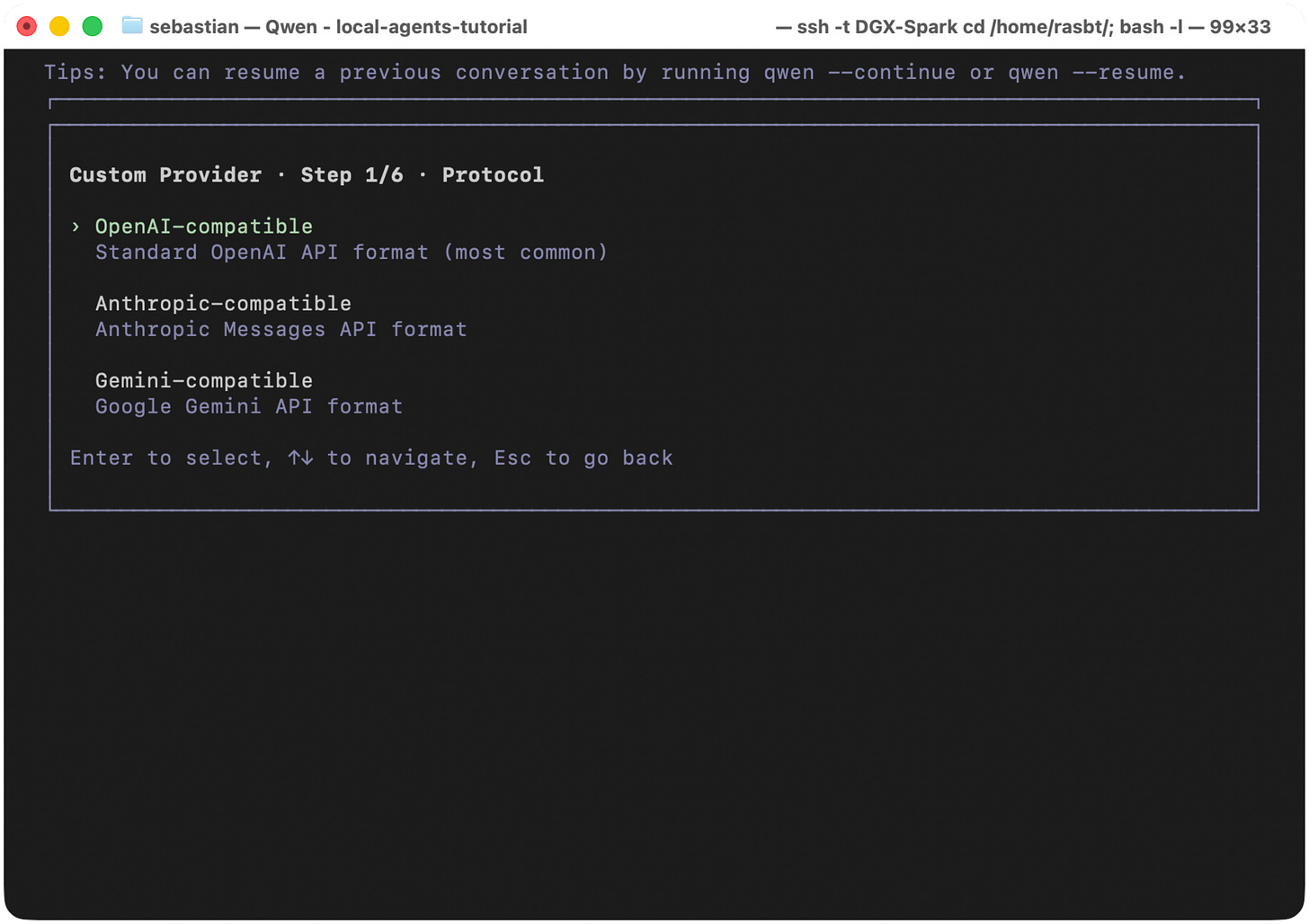
Figure 17: Since Ollama follows the OpenAI API standard, we choose “OpenAI-compatible” here.
Next, we need to provide the API endpoint of the running Ollama application that serves our local LLM. Usually that's the local http://127.0.0.1:11434 address by default. We enter http://127.0.0.1:11434/v1(including the /v1) since that's the OpenAI-compatible base URL.
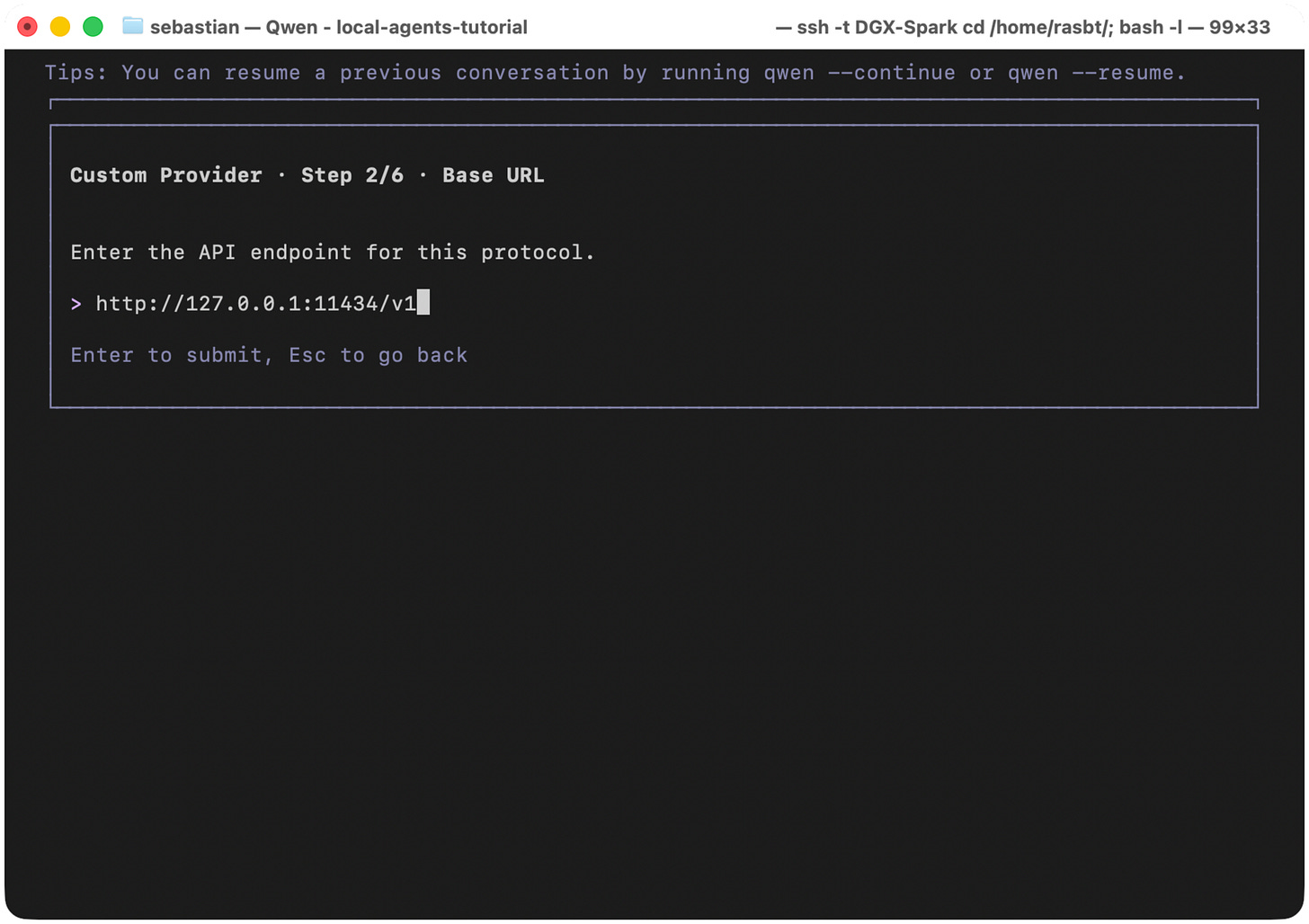
Figure 18: Configure Qwen Code to use Ollama's local OpenAI-compatible endpoint, http://127.0.0.1:11434/v1.
Next, we enter ollama as our custom provider.
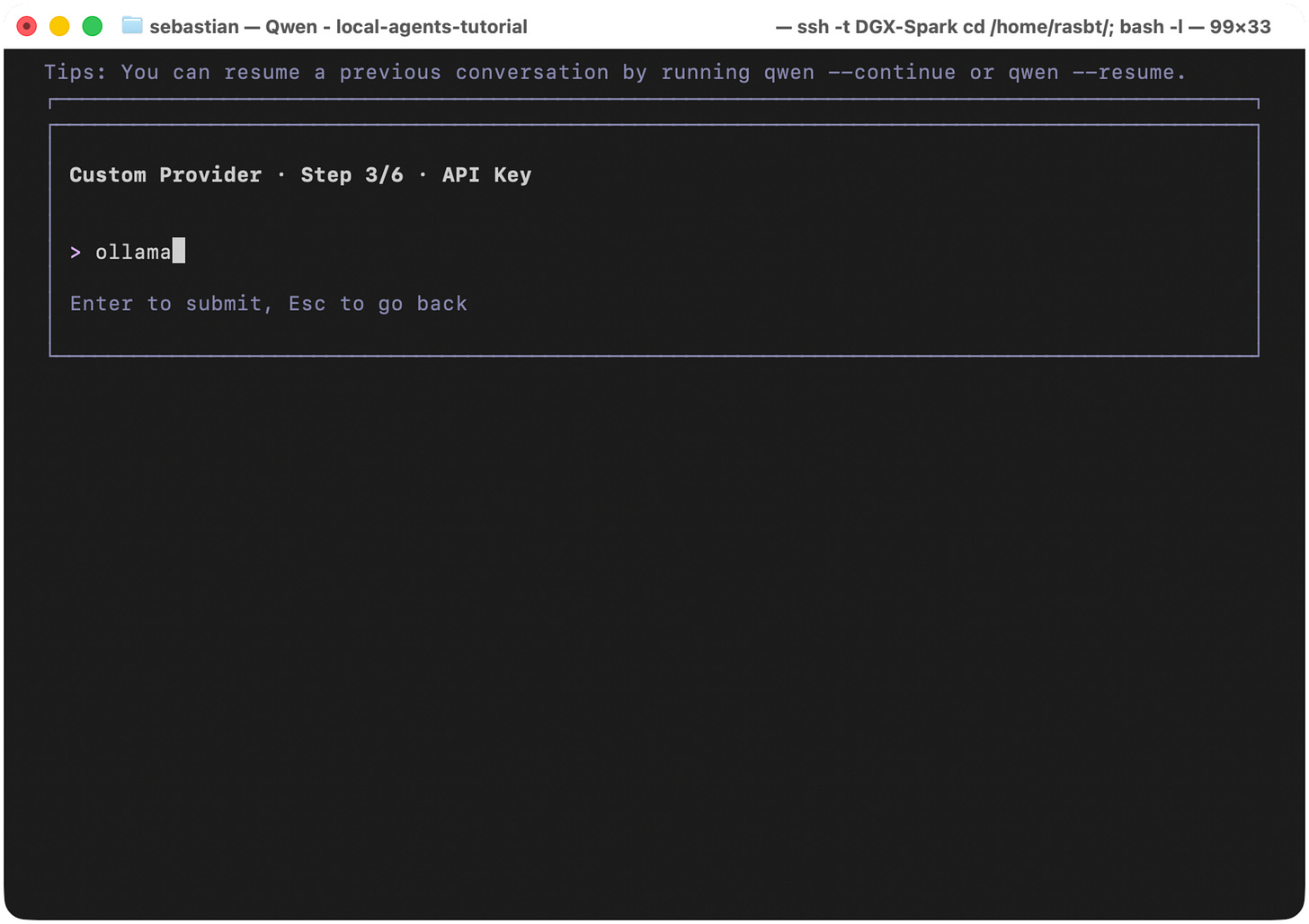
Figure 19: Enter ollama as the API key placeholder for the local custom provider.
Next, we can select the available models. These are the ones that we downloaded via ollama pull. You can enter only a single model or multiple ones separated by commas. You can double-check the list of downloaded models via ollama list. By the way, you can always add more models easily later (I'll explain after completing the setup).
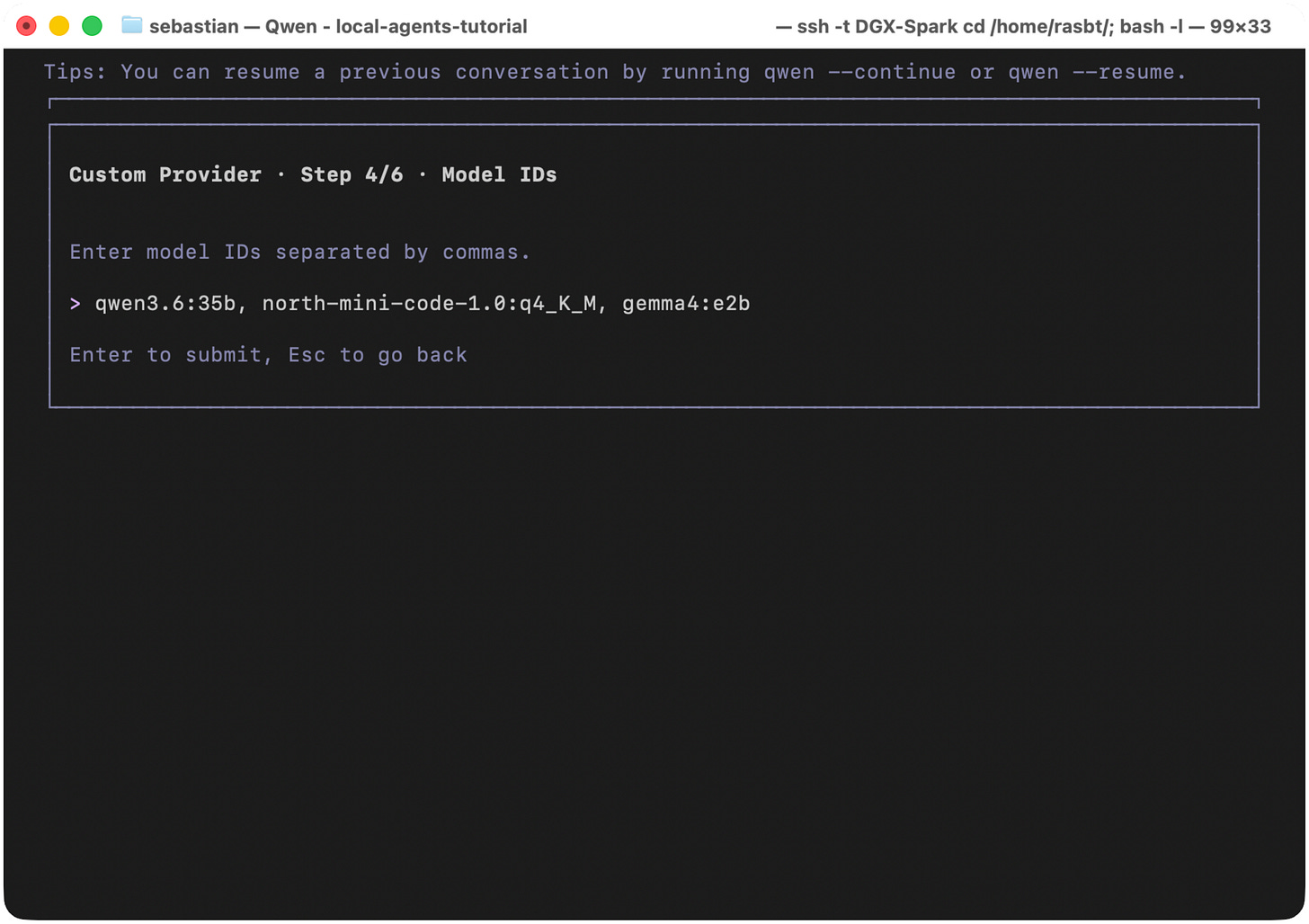
Figure 20: Select the local Ollama models that Qwen Code should make available through the custom provider.
We are almost done! In step 5/6, we of course select “Enable thinking” mode, which will result in higher token usage but the better resulting problem-solving capabilities are worth it.
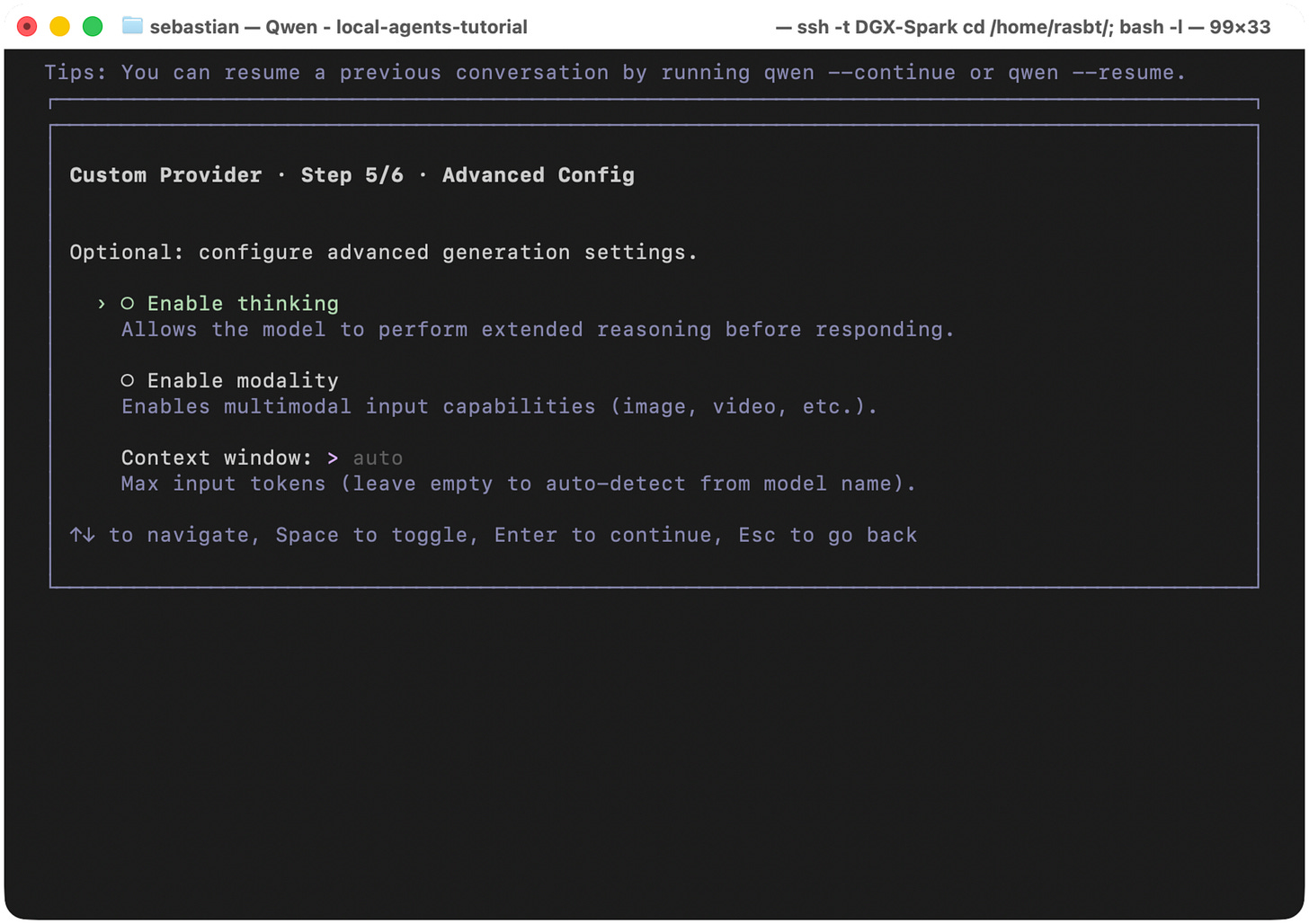
Figure 21: Enable thinking mode for the local model provider.
And that's basically it. Step 6 is basically a review step that we can confirm by pressing “Enter”.
完成安装后,我们现在可以通过终端中的 qwen 命令启动 Qwen-Code 客户端,以完成设置并连接到本地托管的 LLM。
为此,在运行 qwen 命令后,我们选择“自定义提供商”,如下图所示。
图 16:选择“自定义提供商”,这样我们就可以连接 Ollama LLM。
Ollama 使用的是 OpenAI API 标准。因此,接下来我们按照屏幕上的设置指南操作,选择“OpenAI 兼容”选项。
图 17:由于 Ollama 遵循 OpenAI API 标准,我们在这里选择“OpenAI 兼容”。
接下来,我们需要提供正在运行并提供本地 LLM 服务的 Ollama 应用程序的 API 端点。通常默认是本地地址 http://127.0.0.1:11434。我们输入 http://127.0.0.1:11434/v1(包括 /v1),因为这是 OpenAI 兼容的 base URL。
图 18:配置 Qwen Code 使用 Ollama 的本地 OpenAI 兼容端点 http://127.0.0.1:11434/v1。
然后,我们输入 ollama 作为我们的自定义提供商。
图 19:为本地自定义提供商输入 ollama 作为 API 密钥占位符。
接下来,我们可以选择可用的模型。这些是我们通过 ollama pull 下载的模型。你可以只输入一个模型,或者输入多个模型(用逗号分隔)。你可以通过 ollama list 来再次检查下载的模型列表。顺便说一下,之后你总是可以轻松地添加更多模型(我将在完成设置后解释)。
图 20:选择 Qwen Code 应通过自定义提供商提供的本地 Ollama 模型。
我们快完成了!在第 5/6 步中,我们当然要选择“启用推理”模式,这会导致更高的 token 使用量,但由此带来的更好问题解决能力是值得的。
图 21:为本地模型提供商启用推理模式。
基本上就是这样了。第 6 步是一个复查步骤,我们可以按“Enter”键确认。
Congratulations, you should now have a working fully-local LLM workflow set up. The usage is pretty much similar to Claude Code, where you can use / commands for various functionality. E.g., you can switch models via the /model command, as shown below.
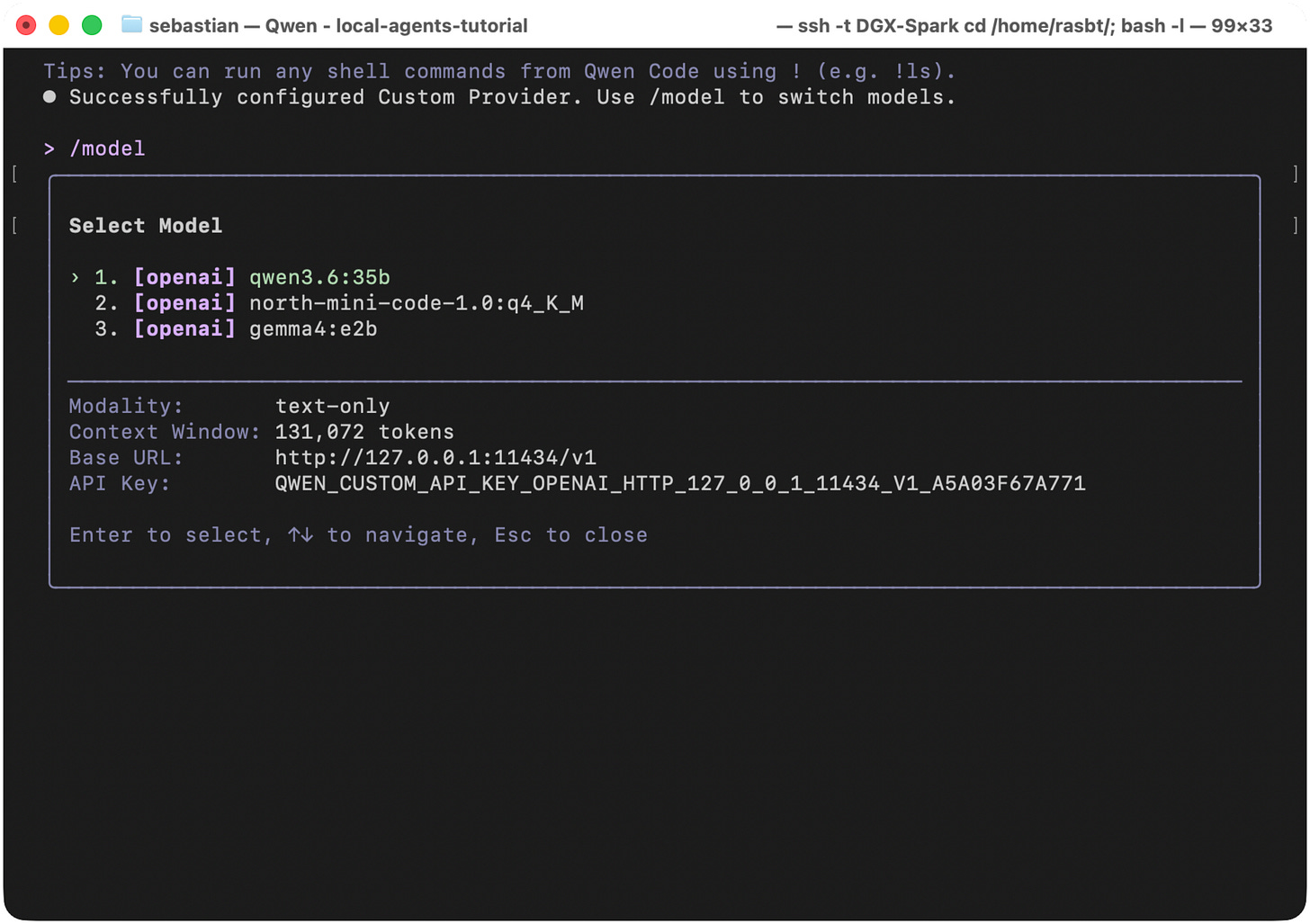
Figure 22: Use /model to switch models.
By the way, as I mentioned before, it's relatively easy to add new models from ollama. Once you pull a new model via ollama pull, you can add it as a new entry in ~/qwen/settings.json. Here, just copy & paste an existing entry into the file and change the “id” and “name” to that of the Ollama model name.
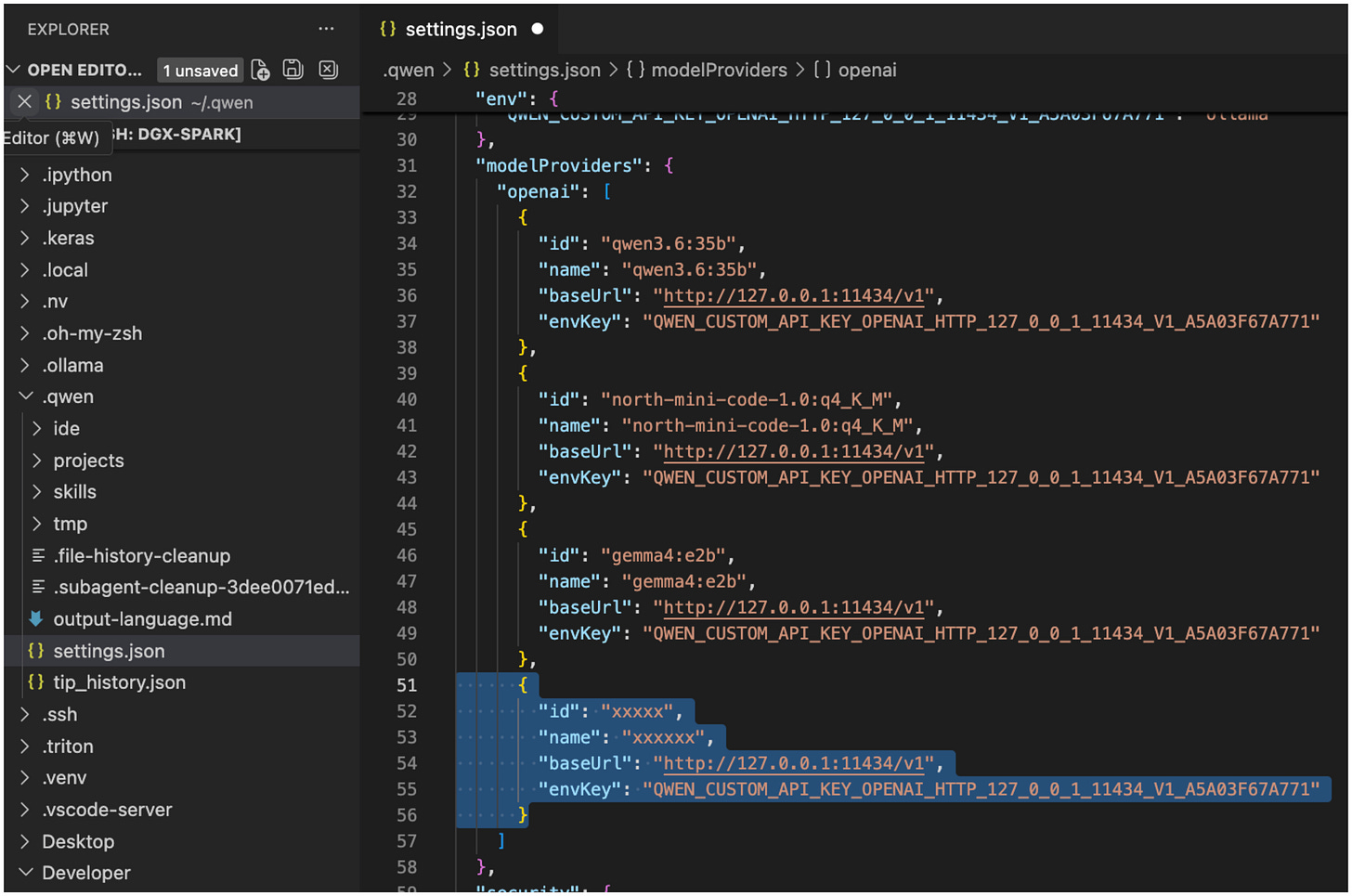
Figure 23: We can add new ollama models by editing the ~/qwen/settings.json config file. Here, "xxxxx" is the name of the ollama model name, e.g., "nemotron-3-nano:30b".
By the way, to update the qwen-code tool once in a while, if we used the git clone & local build route, we can pull a recent GitHub snapshot and update it as follows:
恭喜!你现在应该已经成功搭建了一个可用的全本地 LLM 工作流。其使用方法与 Claude Code 非常相似,你可以使用 / 命令来实现各种功能。例如,你可以通过 /model 命令切换模型,如下所示。
图 22:使用 /model 来切换模型。
顺便提一下,正如我之前提到的,从 Ollama 添加新模型相对容易。一旦你通过 ollama pull 下载了一个新模型,你就可以在 ~/qwen/settings.json 中将其添加为一个新条目。只需复制粘贴文件中的一个现有条目,并将 id 和 name 修改为 Ollama 模型的名称即可。
图 23:我们可以通过编辑 ~/qwen/settings.json 配置文件来添加新的 Ollama 模型。这里,xxxxx 是 Ollama 模型的名称,例如 nemotron-3-nano:30b。
顺便提一下,如果要偶尔更新 qwen-code 工具,如果我们使用 git clone 和本地构建的方式,可以拉取最新的 GitHub 快照并按如下方式更新:
Now that we have a fully working, local coding agent, the question is: how well does it perform, and is it actually good enough for my tasks? Of course, there are benchmarks for this, but in my opinion, nothing beats trying it for yourself on some of your workflow. In other words, this basically means using it for a day or two to decide whether it meets your bar.
I also recommend compiling a small set of tasks that reflect your common coding agent usage. And if you come upon a particularly challenging one when working on a given project, it may not be a bad idea to add it to this set to evaluate future models.
现在我们有了一个功能齐全的本地编码代理,问题是:它的实际表现如何?是否真的足以胜任我的任务?当然,对此有基准测试,但在我看来,没有什么比亲自在你的工作流中试用一下更好了。换句话说,这基本上意味着使用它一两天,以决定它是否达到你的标准。 我还建议整理一个小任务集,以反映你常见的编码代理使用场景。如果你在处理某个特定项目时遇到了特别有挑战性的任务,将其添加到这个任务集中以评估未来的模型,可能是一个不错的主意。
As an example of what I mean, I shared a relatively small, simple, and general set of tasks we can use to test the agents here on GitHub: https://github.com/rasbt/local-coding-agent-evals/tree/main/agent-problem-pack. This is basically an extension of the tasks from the Local LLM Setup section.
The details on how to run these are in the GitHub README: https://github.com/rasbt/local-coding-agent-evals/tree/main/agent-problem-pack#quick-start-running-benchmarks-manually.
Below is the outcome for the different LLMs tested in Qwen-Code.
As we can see, both the Qwen3.6 and North Mini Code 35B-A3B models solve 4 out of 5 of these problems. Gemma 4 E2B fails a lot. Out of curiosity, I also added the a bit older Nemotron 3 Nano model. It has a similar size and compute performance as the aforementioned Qwen and North models, and it performs similarly well.
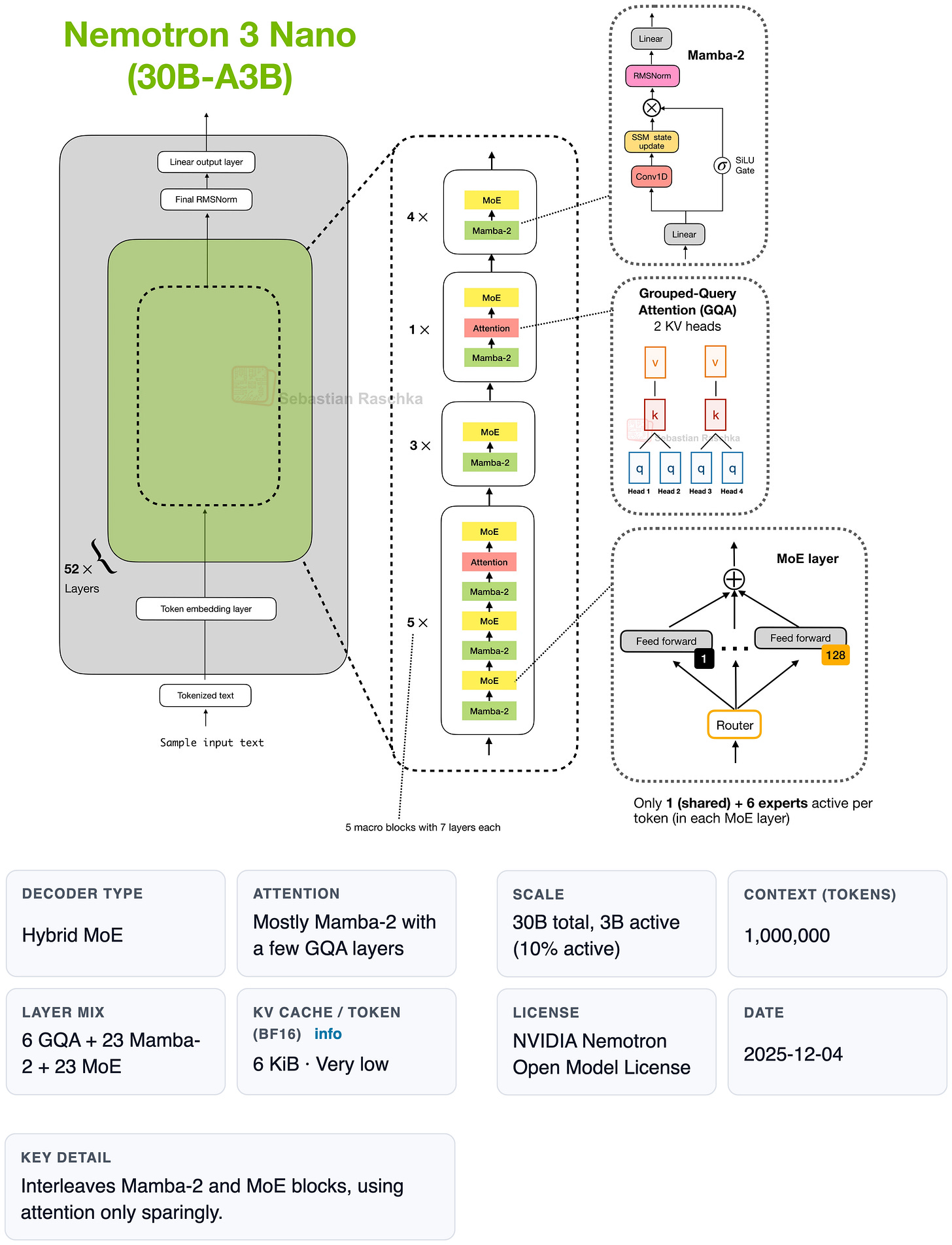
Figure 25: Nemotron 3 Nano architecture overview from my LLM Gallery
作为例子,我在 GitHub 上分享了一个相对较小、简单且通用的任务集,我们可以用它来测试代理:https://github.com/rasbt/local-coding-agent-evals/tree/main/agent-problem-pack。这基本上是对本地 LLM 设置部分任务的扩展。
如何运行这些任务的详细信息在 GitHub README 中:https://github.com/rasbt/local-coding-agent-evals/tree/main/agent-problem-pack#quick-start-running-benchmarks-manually。
以下是在 Qwen-Code 中测试的不同 LLM 的结果。
我们可以看到,Qwen3.6 和 North Mini Code 35B-A3B 模型都解决了 5 个问题中的 4 个。Gemma 4 E2B 失败了很多次。出于好奇,我还添加了稍旧一点的 Nemotron 3 Nano 模型。它的大小和计算性能与前面提到的 Qwen 和 North 模型相似,并且表现也同样出色。
图 25:来自我的 LLM 图库的 Nemotron 3 Nano 架构概览。
Unfortunately, as far as I know, the Codex UI does not support non-OpenAI models, but we can use the Codex CLI to run our Ollama models.
If you haven't installed the OpenAI Codex CLI yet, you can get and install it analogously to qwen-code from their open-source GitHub directory: https://github.com/openai/codex (Yes, the Codex CLI is open source!)
I will spare you the lengthy listing of the commands and recommend checking the repo's README instead for the official instructions. (Cloning the repo and running an audit similar to qwen-code is not a bad idea here, as well.)
Then, once installed, there are multiple ways to enable local model use. In my opinion, the most convenient way is to set up a separate config ~/.codex/ollama.config.toml (inside the existing ~/.codex folder) with some default options:
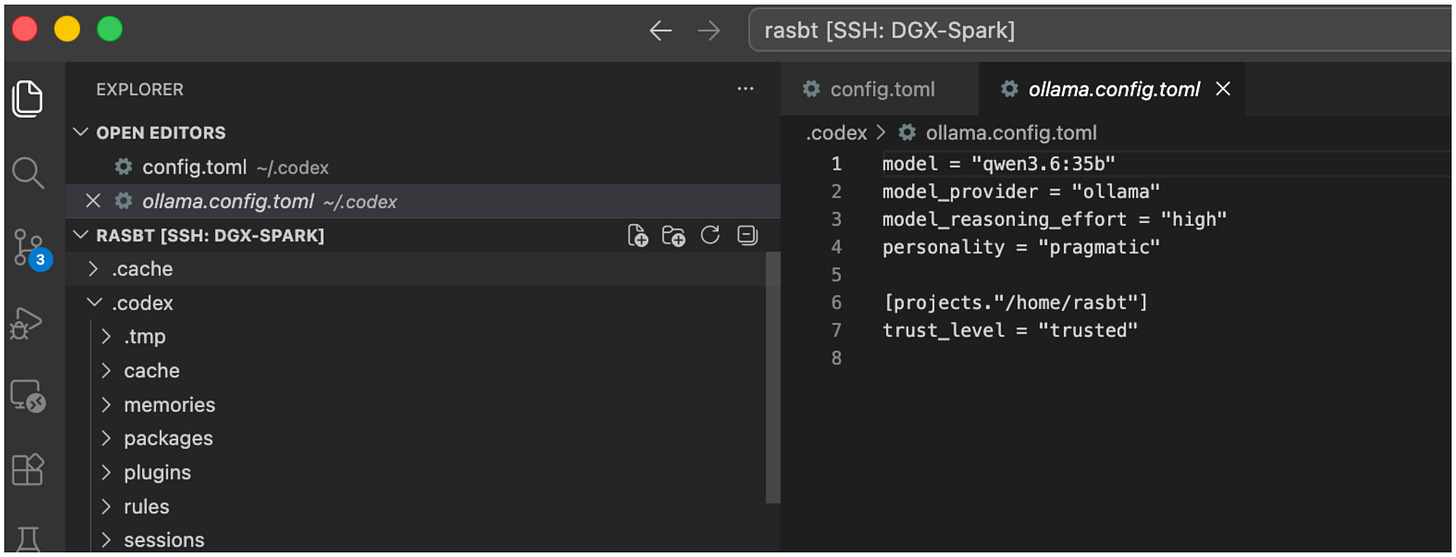
Figure 26: Set up a separate Ollama profile for Codex for convenience.
Then, we can still use codex to launch the regular “Codex with GPT 5.5” mode and use our Ollama model via codex --profile ollama.
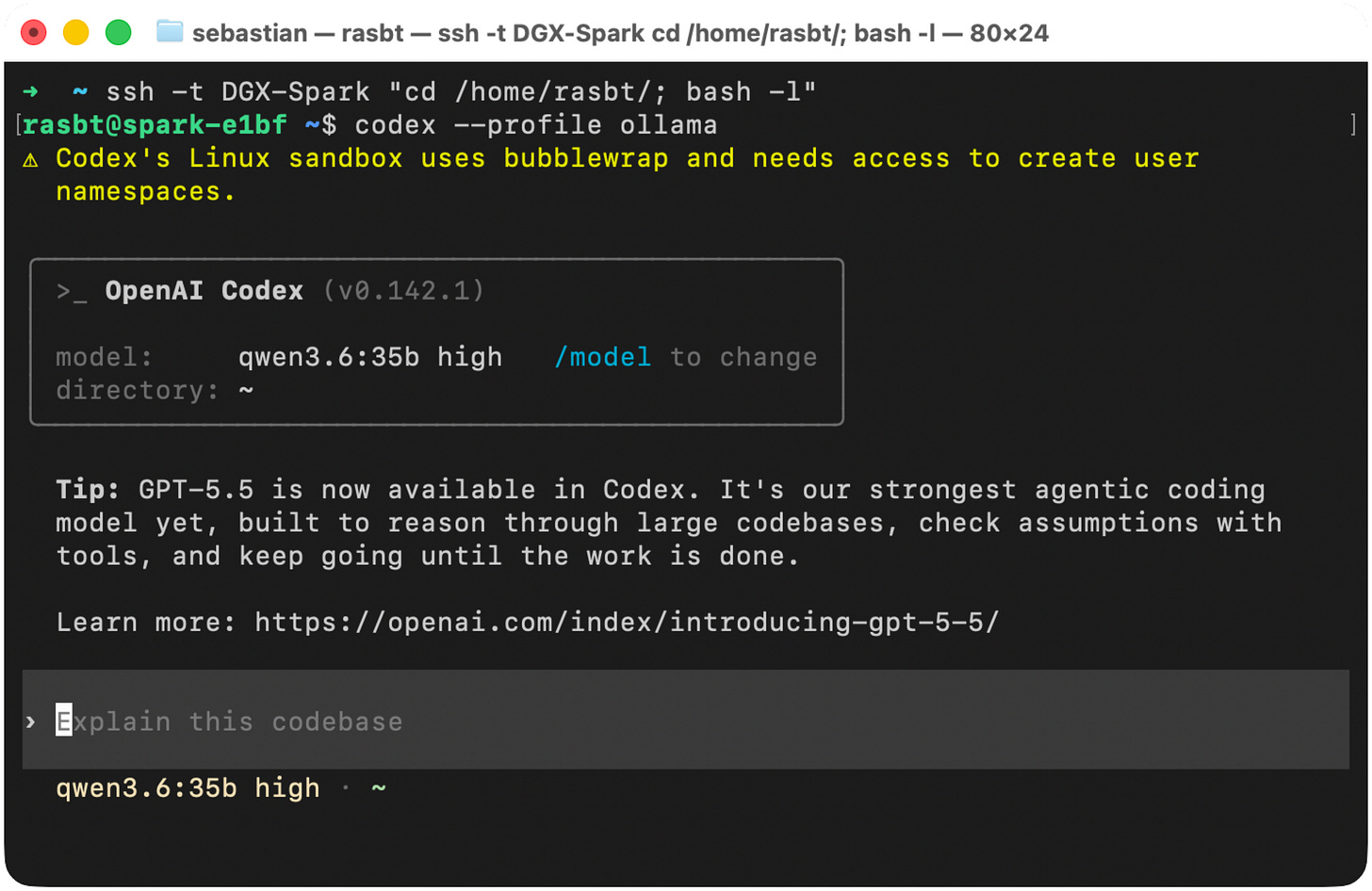
Figure 27: Launch Codex using a local Ollama model.
不幸的是,据我所知,Codex 用户界面不支持非 OpenAI 模型,但我们可以使用 Codex CLI 来运行我们的 Ollama 模型。
如果你还没有安装 OpenAI Codex CLI,可以根据他们开源的 GitHub 目录(https://github.com/openai/codex)来获取并安装它,类似于 qwen-code 的安装方式(是的,Codex CLI 是开源的!)。
我就不再列出冗长的命令了,建议你查看仓库的 README 以获取官方说明。(在此处克隆仓库并运行类似于 qwen-code 的审计也是一个不错的主意。)
安装完成后,有多种方法可以启用本地模型。在我看来,最方便的方式是设置一个单独的配置文件 ~/.codex/ollama.config.toml(位于已有的 ~/.codex 文件夹内),并包含一些默认选项:
图 26:为了方便,为 Codex 设置一个独立的 Ollama 配置文件。
然后,我们仍然可以使用 codex 启动常规的“Codex with GPT 5.5”模式,并通过 codex --profile ollama 使用我们的 Ollama 模型。
图 27:使用本地 Ollama 模型启动 Codex。
When rerunning the test cases from the Agent Capability Assessment section, to my surprise, Qwen3.6 does actually perform better via Codex compared to its “native” Qwen-Code coding harness, as shown below.

Figure 28: Small local agent capability benchmark in Codex.
Even though this is just a small set of benchmarks, it suggests that using Codex as the universal coding agent harness may not be such a bad idea after all.
当重新运行代理能力评估部分的测试用例时,令我惊讶的是,Qwen3.6 通过 Codex 的表现实际上比通过其“原生”的 Qwen-Code 编码框架更好,如下所示。
图 28:Codex 中的小规模本地代理能力基准测试。
尽管这只是一个小型基准测试,但它表明使用 Codex 作为通用编码代理框架也许终究不是一个坏主意。
Of course, there is also the popular Claude Code agent harness that we could use as a harness around our local LLMs. While very popular and capable, this is probably my least favorite option for local setups because the codebase is proprietary. That also means we cannot readily inspect and/or disable Anthropic's data logging practices.
To set it up, if you don't have Claude Code already installed on your machine, I suggest checking the official docs for recommended installation commands: https://code.claude.com/docs/en/quickstart.
Claude Code itself does not expose the same local-provider configuration path as Codex. However, Ollama provides an integration via ollama launch claude: https://docs.ollama.com/integrations/claude-code
I.e., we can execute ollama launch claude to run the Claude Code harness with an Ollama model.
By the way, this also works for codex via ollama launch codex, but I personally prefer the codex --profile ollama route we discussed earlier, as it gives me a bit more insight and control about how things works etc.
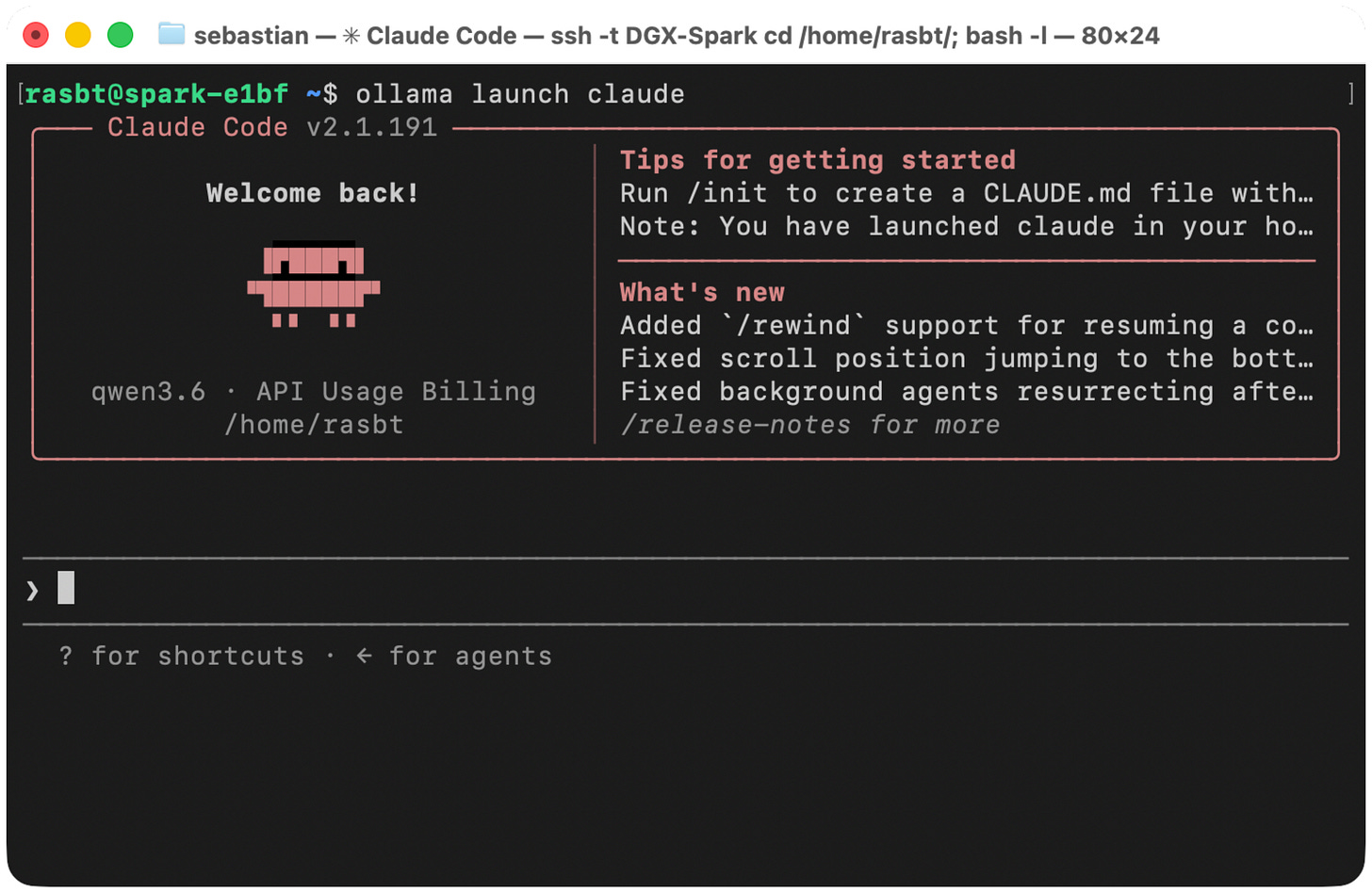
Figure 29: Claude Code with a local Qwen3.6 model through Ollama.
当然,还有流行的 Claude Code 代理框架,我们可以用它来包裹我们的本地 LLM。虽然它非常流行且功能强大,但这可能是我最不喜欢的本地设置选择,因为它的代码库是专有的。这也意味着我们无法轻易检查和/或禁用 Anthropic 的数据记录行为。
要设置它,如果你的机器上尚未安装 Claude Code,我建议查看官方文档以获取推荐的安装命令:https://code.claude.com/docs/en/quickstart。
Claude Code 本身没有像 Codex 那样暴露本地提供商的配置路径。不过,Ollama 通过 ollama launch claude 提供了一个集成:https://docs.ollama.com/integrations/claude-code。
也就是说,我们可以执行 ollama launch claude 来使用 Ollama 模型运行 Claude Code 框架。
顺便提一下,这同样适用于 codex(通过 ollama launch codex),但我个人更喜欢我们之前讨论的 codex --profile ollama 方式,因为它能让我对事情的工作原理有更多的了解和掌控。
图 29:通过 Ollama 在 Claude Code 中使用本地 Qwen3.6 模型。
However, as a user, it feels like Claude Code takes much longer to come up with a solution. It probably has a much higher token usage. So, below, I additionally looked at the token usage of all three harnesses.
As we can see, Claude Code uses by far the most tokens on average, Codex the least.
When it comes to the little agent capability assessment benchmark, the Qwen and North Mini Code models also get 5/5, and even the small Gemma 4 model does ok!
Interestingly, we can also see that the token usage is largely driven by the harness, not the LLM itself. I.e., among all three LLMs that are capable of solving (almost) all 5 tasks, they all use the same number of tokens (e.g., Qwen3.6 uses roughly the same number of tokens as North Mini Code and Nemotron 3 Nano when used inside Claude Code). Only Gemma 4 uses fewer tokens, but it also fails almost all tasks, likely because of insufficient tool-calling capabilities where the tasks interrupt early.
For reference, below is again the summarized task-success rate.

Figure 31: Summarized task success rates.
Anyway, the takeaway here is that if more tokens help the model-harness combination to solve more (and more complex) problems, great! But if we have two harnesses that both have an equal task success rate, a harness that uses 50% fewer tokens (e.g., Codex over Claude Code), then this is a huge win, because it will make tasks run twice as fast.
然而,作为用户,感觉 Claude Code 需要更长的时间来想出一个解决方案。它可能使用了更多的令牌。因此,下面我还额外查看了所有三个框架的令牌使用情况。
我们可以看到,Claude Code 平均使用的令牌数量远远最多,Codex 最少。
在小型代理能力评估基准测试中,Qwen 和 North Mini Code 模型也获得了 5/5 的成绩,甚至较小的 Gemma 4 模型表现也不错!
有趣的是,我们还可以看到,令牌使用量很大程度上是由框架驱动的,而不是 LLM 本身。也就是说,在所有能够解决(几乎)全部 5 个任务的三个 LLM 中,它们使用的令牌数量相同(例如,在 Claude Code 内部使用时,Qwen3.6 使用的令牌数量与 North Mini Code 和 Nemotron 3 Nano 大致相同)。只有 Gemma 4 使用了更少的令牌,但它也几乎失败了所有任务,很可能是因为工具调用能力不足,导致任务过早中断。
作为参考,下面再次给出了任务成功率的总结。
图 31:汇总的任务成功率。
总之,这里的要点是:如果更多的令牌能帮助模型-框架组合解决更多(以及更复杂)的问题,那很好!但如果两个框架具有相同的任务成功率,那么使用令牌少 50% 的框架(例如 Codex 对比 Claude Code)将是一个巨大的胜利,因为这将使任务运行速度提高一倍。
However, the big caveat here is that task correctness is a necessary criterion, but it doesn't measure code quality and readability, which are hard to assess automatically.
PS: I tried to analyze why Claude Code uses more tokens, and it seems that the difference mainly comes from input tokens rather than output tokens. In other words, Claude is not writing twice as much. The logs suggest that Claude is repeatedly feeding more context back into the model across turns, including previous messages, tool calls, command outputs, and file contents. For example, one Claude run used about 578k input tokens but only about 4.5k output tokens across 25 turns. So the likely explanation is that Claude's harness accumulates or accounts for a larger prompt-side history during multi-step agent runs.
然而,这里有一个重要的提醒:任务正确性是一个必要标准,但它不衡量代码质量和可读性,而这些是很难自动评估的。 附注:我试图分析为什么 Claude Code 使用更多的令牌。看起来差异主要来自输入令牌,而非输出令牌。换句话说,Claude 并没有写出两倍的内容。日志表明,Claude 在多次交互中反复向模型喂入更多的上下文,包括先前消息、工具调用、命令输出和文件内容。例如,一次 Claude 运行在 25 轮交互中使用了大约 57.8 万输入令牌,但仅产生了大约 4500 输出令牌。所以可能的解释是,Claude 的框架在多步代理运行期间累积或考虑了更大的提示侧历史记录。
So far, all the setups we discussed assumed that we were running the local LLM on the same machine as the coding harness.
However, what if we developed some trust in the coding agent harness and want to use it on our main Mac while the model itself is hosted on a different machine, e.g., a DGX Spark?
In my opinion, the best (or most convenient) setup is an SSH tunnel from the Mac to the DGX.
First, I suggest quitting Ollama on the Mac or changing the 11434 to something else below.
Assuming we quit the Ollama app on the Mac, check that the following returns an empty output to indicate that Ollama is not available:
Then run the following command on that Mac in a terminal window on the Mac side:
That command means that we open an SSH connection to DGX-Spark as user rasbt, which you need to adjust to whatever your username and machine name are. Then, the command forwards the Mac's local port 11434 to 127.0.0.1:11434 on the DGX because of -L 11434:127.0.0.1:11434. Note that this is the Ollama address.
The terminal running ssh -N -L ... will look like it is hanging. That is normal. Keep it open while you use Qwen Code, Codex, or Claude Code. Press Ctrl-C to stop the tunnel.
So after it is running, use this on your Mac to see if the Mac can indeed access the ollama models from the DGX:
If that returns the DGX models, your Mac tools can use the DGX Ollama server as if it were local.
Then, just use Qwen Code and Codex just like above.
For Claude via ollama launch claude, the key is that the Mac-side ollama command must see the tunneled endpoint. If needed:
到目前为止,我们讨论的所有设置都假设我们在与编码框架同一台机器上运行本地 LLM。
但是,如果我们对某个编码代理框架建立了一些信任,并希望在主 Mac 上使用它,而模型本身托管在另一台机器上(例如 DGX Spark),该怎么办?
在我看来,最好的(也是最方便的)设置是从 Mac 到 DGX 的 SSH 隧道。
首先,我建议在 Mac 上退出 Ollama,或者将下面的 11434 端口改为其他。
假设我们在 Mac 上退出了 Ollama 应用,请检查以下命令是否返回空输出,以表明 Ollama 不可用:
然后,在 Mac 的终端窗口中运行以下命令:
该命令的意思是,我们以用户 rasbt 的身份打开一个到 DGX-Spark 的 SSH 连接(你需要将其调整为你自己的用户名和机器名)。然后,该命令通过 -L 11434:127.0.0.1:11434 将 Mac 的本地端口 11434 转发到 DGX 上的 127.0.0.1:11434。请注意,这是 Ollama 的地址。
运行 ssh -N -L ... 的终端看起来像是挂起了。这是正常的。在使用 Qwen Code、Codex 或 Claude Code 时保持它打开。按 Ctrl-C 停止隧道。
因此,在它运行之后,在你的 Mac 上使用以下命令检查 Mac 是否确实能够访问 DGX 上的 Ollama 模型:
如果返回了 DGX 上的模型列表,那么你的 Mac 工具就可以像使用本地一样使用 DGX 的 Ollama 服务器。
然后,就像上面一样使用 Qwen Code 和 Codex。
对于通过 ollama launch claude 使用 Claude,关键在于 Mac 端的 ollama 命令必须能够看到隧道化的端点。如果需要:
We focused on Qwen Code, Codex, and Claude Code because they are the most direct fit for coding-agent workflows. OpenClaw and Hermes are also capable, but they are broader agent harnesses. They are better suited when you want one agent to coordinate across tools, apps, browsers, terminals, and longer-running workflows.
For coding work, I recommend starting with Qwen Code, Codex, or Claude Code first (and there are also many other interesting coding harnesses like OpenCode, Cline, Pi, and Noumena Code). And I would treat OpenClaw and Hermes as interesting follow-up options for things beyond coding rather than the first baseline for this local coding-agent setup.
我们重点关注了 Qwen Code、Codex 和 Claude Code,因为它们最适合编码代理工作流。OpenClaw 和 Hermes 也很有能力,但它们是更广泛的代理框架。当你希望一个代理能够协调工具、应用、浏览器、终端以及更长时间运行的工作流时,它们更合适。 对于编码工作,我建议首先从 Qwen Code、Codex 或 Claude Code 开始(此外还有很多其他有趣的编码框架,如 OpenCode、Cline、Pi 和 Noumena Code)。我会将 OpenClaw 和 Hermes 视为超越编码范围的有趣后续选项,而不是这个本地编码代理设置的首个基准。
This was a long article with lots of information and configuration. If there are a few main takeaways, I'd say that it's not the mechanistic setup pipeline but rather the considerations when running coding agents locally. That is, the most important part is not getting one specific tool installed, but understanding the model-serving layer, the agent harness, the permission model, and how to evaluate whether the setup actually solves coding tasks reliably.
Of course, GPT 5.5 and Opus 4.8 are currently better than smaller open-weight models that run on a Mac or DGX Spark. But the newer Mixture-of-Experts models in the 30-35B range (such as Qwen3.6, North Mini Code, and Nemotron 3 Nano) are all very, very capable and really sufficient for a lot of tasks. And yes, they run with the same token speed as GPT 5.5 through a Pro subscription, so it should not necessarily slow down your workflows.
The main consideration when setting up local agents, besides the model itself, is also which harness we want to use. The common perception is that models are usually optimized more for a specific harness than others (e.g., Qwen3.6 may work better in Qwen Code than Claude Code, for example). Based on the small agent assessment, this may not necessarily be true, though (this is only a very small benchmark, so take it with a big grain of salt). So, if you are more comfortable with a different harness that you have a lot of muscle memory with, like Codex and Claude Code, maybe it's not a bad idea to just stick the model into that one and give it a try!
这是一篇很长的文章,包含了大量信息和配置。如果要说几个主要收获,我认为重点不是机械的设置流程,而是在本地运行编码代理时需要考虑的各种因素。也就是说,最重要的不是安装某个特定的工具,而是理解模型服务层、代理框架、权限模型,以及如何评估这个设置是否真的能可靠地解决编码任务。 当然,GPT 5.5 和 Opus 4.8 目前比在 Mac 或 DGX Spark 上运行的较小的开放权重模型更好。但是 30–35B 范围内较新的混合专家/混合专家(Mixture-of-Experts)模型(例如 Qwen3.6、North Mini Code 和 Nemotron 3 Nano)都非常非常强大,并且对于许多任务来说确实足够用了。没错,它们的运行令牌速度与通过 Pro 订阅的 GPT 5.5 相当,因此未必会拖慢你的工作流。 设置本地代理时,除了模型本身之外,主要的考虑因素还包括我们想要使用哪个框架。普遍的看法是,模型通常针对某个特定框架的优化程度要高于其他框架(例如,Qwen3.6 在 Qwen Code 中的表现可能比在 Claude Code 中更好)。然而,根据这个小型代理评估,这未必是事实(这只是一个非常小的基准测试,所以请持保留态度)。因此,如果你对另一个你已经形成肌肉记忆的框架(如 Codex 和 Claude Code)感觉更顺手,那么也许把模型塞进那个框架里试一试,并不是一个坏主意!
Anyways, I hope the article was useful, and it got you interested in doing some tinkering with open-weight models. They are becoming more capable by the day, and it's for some inexplicable reason just fun to run models locally.
If you want to try the benchmarks yourself, the code and small evaluation tasks used in this article are available here: https://github.com/rasbt/local-coding-agent-evals
Also, my Build a Reasoning Model (From Scratch) book has now gone to print and started shipping. I wanted to post a picture, but it will be 3 more days until it arrives.
If you liked my previous Build a Large Language Model (From Scratch) book, this is essentially a sequel implementing inference-time scaling techniques and reinforcement learning algorithms from scratch.
And if you want to support future long-form articles like this one, consider becoming a paid subscriber. It helps me keep writing these independent deep dives and sharing the accompanying code, figures, and experiments.
无论如何,希望这篇文章对你有用,并让你对摆弄开放权重模型产生了兴趣。它们正变得越来越强大,而且出于某种无法解释的原因,在本地运行模型就是很有趣。 如果你想自己尝试这些基准测试,本文使用的代码和小的评估任务都可以在这里找到:https://github.com/rasbt/local-coding-agent-evals 另外,我的《从零构建推理模型》一书现在已经付印并开始发货了。我本想放一张图片,但还要 3 天才到货。 如果你喜欢我之前写的《从零构建大语言模型》这本书,那么这本基本上是它的续作,从零实现推理时扩展技术和强化学习算法。 如果你想支持未来像这样长篇的文章,可以考虑成为付费订阅者。这能帮助我继续撰写这些独立的深入探索,并分享配套的代码、图表和实验。
Discussion about this post
Ready for more?
关于本文的讨论
准备好了解更多了吗?