Claude Code 动态工作流:让 AI 自动编写任务专用的编排脚本
Anthropic 工程师 Thariq Shihipar 介绍了 Claude Code 新增的动态工作流功能,允许 Claude 在运行时自动生成定制的 JavaScript 编排脚本来协调多个子智能体。文章详细阐述了为什么需要绕过单上下文窗口的局限性,如智能体惰性、自我偏好偏差和目标漂移,并给出了分类-执行、扇出-聚合、对抗验证、锦标赛等具体的编排模式。作者通过迁移重构、深度研究、大规模分类、根因分析等真实用例展示了该功能的适用场景,同时诚实地指出动态工作流会增加 token 消耗,并不适合常规编码任务。文中还提供了组合使用 /goal、/loop 命令以及设置 token 预算的操作性建议,适合希望突破单一智能体能力边界的一线工程师阅读。
Last week, we released dynamic workflows in Claude Code. Claude can now write its own harness on the fly, custom-built for the task at hand.
上周,我们在 Claude Code 中发布了动态工作流。Claude 现在能够即时编写自己的任务框架,为手头任务量身定制。
While the default Claude Code harness is built for coding, it is also useful for many other types of tasks because, as it turns out, many tasks resemble coding tasks. But there are certain classes of tasks where we have had to build custom harnesses on top of Claude Code to achieve peak performance such as Research, security analysis, agent teams, or Code Review.
Workflows allow you to dynamically create harnesses that enable Claude to solve all of those problems and more natively inside of Claude Code. You can also share and re-use these workflows with others.
默认的 Claude Code 框架虽为编程而设计,但许多其他类型的任务——实际上,很多任务都类似编程任务——同样适用。然而,某些任务类别需要我们在 Claude Code 之上构建自定义框架才能达到最佳性能,如研究、安全分析、代理团队或代码审查。
工作流让您能够动态创建框架,使 Claude 在 Claude Code 内部原生解决所有这些甚至更多问题。同时,您还可以与他人共享和重用这些工作流。
That said, best practices are still developing! Dynamic workflows often use more tokens, so think carefully about when and how to use them.
Here are some example prompts to get you thinking about the possibilities with workflows:
- "This test fails maybe 1 in 50 runs. Set up a workflow to reproduce it, form theories and adversarially test them in worktrees /goal don't stop until one theory works."
- "Using a workflow, go through my last 50 sessions and mine them for corrections I keep making and turn the recurring ones into CLAUDE.md rules"
- "Use a workflow to dig through #incidents in Slack for the past six months and find recurring root causes where nobody has filed a ticket."
- "Take my business plan and run a workflow where different agents tear it apart from an investor's, a customer's, and a competitor's perspective."
- "Here's a folder of 80 resumes, use a workflow to rank them for the backend role and double-check the top ten. Interview me using the AskUserQuestion tool for a rubric."
- "I need a name for this CLI tool. Use a workflow to brainstorm a bunch of options and run a tournament to pick the top 3."
- "Use a workflow to rename our User model to Account everywhere."
- "Go through my blog post draft and using a workflow verify every technical claim against the codebase, I don't want to ship anything wrong."
不过,最佳实践仍在形成中!动态工作流通常消耗更多 token,因此请谨慎考虑何时以及如何使用它们。
下面是一些示例提示词,帮助您思考工作流的可能性:
- “这个测试大约每 50 次运行失败 1 次。设置一个工作流来复现它,提出理论并开展对抗性测试,使用工作树 /goal,直到某个理论奏效为止。”
- “使用工作流,梳理我最近 50 次会话,发掘我不断犯的错误,把重复出现的问题转化为 CLAUDE.md 规则。”
- “使用工作流挖掘 Slack 中过去六个月的事故/incidents,找出无人提交工单的重复性根因。”
- “拿着我的商业计划书,运行一个工作流,让不同的代理从投资者、客户和竞争对手的角度分别剖析它。”
- “这里有一个包含 80 份简历的文件夹,使用工作流为后端岗位对它们进行排名,并复核前十名。用 AskUserQuestion 工具面试我,制定一个评分标准/rubric。”
- “我需要给这个 CLI 工具起个名字。使用工作流头脑风暴一堆选项,然后运行一个淘汰赛挑出前 3 名。”
- “使用工作流把我们的 User 模型重命名为 Account,改遍所有地方。”
- “检查我的博客草稿,使用工作流对照代码库验证每一条技术主张,我不想发布任何错误内容。”
Dynamic workflows execute a javascript file with a few special functions that help spawn and coordinate subagents:

Dynamic workflows also include standard JavaScript functions like JSON, Math, and Array, to help process data.
It's particularly useful to know that dynamic workflows can decide which models an agent uses and whether subagents are run in their own worktree, allowing Claude to choose the intelligence level and isolation needed.
If a workflow is interrupted, for example by user action or quitting the terminal, resuming the session will allow the workflow to pick up where it left off.
动态工作流执行一个包含若干特殊函数的 JavaScript 文件,这些函数用于生成和协调子代理:
动态工作流还包含标准 JavaScript 函数,如 JSON、Math 和 Array,以协助处理数据。
一个特别有用的特性是:动态工作流可以决定子代理使用哪个模型,以及子代理是否在自己的工作树中运行——这让 Claude 能按需选择智能水平和隔离程度。
如果工作流被中断(例如用户操作或退出终端),恢复会话后工作流会从断点处继续执行。
When you ask the default Claude Code harness to do a task, it needs to both plan and execute in the same context window. For many coding tasks, this is highly effective, but it can sometimes break down over long-running, massively parallel and/or highly structured adversarial tasks.
This is because the longer Claude works on a complex task in a single context window, the more it becomes susceptible to a few specific failure modes:
- Agentic laziness refers to when Claude stops before finishing a particularly complex, multi-part task and declares the job done after partial progress, for example addressing 20 of the 50 items in a security review.
- Self-preferential bias refers to Claude's tendency to prefer its own results or findings, especially when asked to verify or judge them against a rubric.
- Goal drift refers to the gradual loss of fidelity to the original objective across many turns, especially after compaction. Each summarization step is lossy, and details like edge-case requirements or "don't do X" constraints can get lost.
Creating a workflow helps combat these by orchestrating separate Claudes with their own context windows and focused, isolated goals.
当你让默认的 Claude Code 框架执行一个任务时,它需要在同一个上下文窗口中同时规划和执行。对于许多编码任务,这种方式非常高效,但在长时间运行、大规模并行或高度结构化的对抗性任务中,有时会失效。
这是因为 Claude 在单个上下文窗口中处理复杂任务的时间越长,就越容易陷入几种特定的失效模式:
- 代理懒惰/Agentic laziness:Claude 在完成特别复杂的多部分任务前就停下来,在部分进展后宣告任务完成——例如在安全审查中只处理了 50 项中的 20 项。
- 自我偏好偏差/Self-preferential bias:Claude 倾向于偏爱自己的结果或发现,尤其是在被要求根据评分标准验证或评判时。
- 目标漂移/Goal drift:在多轮交互中,尤其是压缩后,原始目标的忠实度逐渐丢失。每一次摘要步骤都有信息损失,像边缘案例需求或“不要做 X”这样的约束可能丢失。
创建工作流可以将多个独立的 Claude(各自拥有自己的上下文窗口和聚焦、隔离的目标)编排起来,从而应对这些问题。
You may have previously created a static workflow using the Claude Agent SDK or claude -p to coordinate multiple instances of Claude Code together.
But because static workflows need to work for all edge cases, they are usually more generic. With Claude Opus 4.8 and dynamic workflows, Claude is now intelligent enough to write a custom harness tailor-made for your use case.

你可能之前已经使用 Claude Agent SDK 或 claude -p 创建过静态工作流,以协调多个 Claude Code 实例。
但由于静态工作流需要应对所有边缘情况,它们通常更通用。借助 Claude Opus 4.8 和动态工作流,Claude 现在足够智能,可以为你的用例编写量身定制的自定义框架。
You can start using dynamic workflows just by asking Claude to make one, or by using the trigger word "ultracode" to ensure that Claude Code creates a workflow.
But building a mental model for how dynamic workflows work will help you understand when to use them and how you might nudge Claude via prompts.
There are a few common patterns that Claude might use and compose together when building workflows:

你只需让 Claude 创建一个工作流,或使用触发词“ultracode”确保 Claude Code 创建工作流,就可以开始使用动态工作流了。
不过,建立对动态工作流运作方式的心智模型,将帮助你理解何时使用它们以及如何通过提示词引导 Claude。
以下是 Claude 在构建工作流时可能使用和组合的几种常见模式:
Classify-and-act
Use a classifier agent to decide on the type of task, and then route to different agents or behavior based on the task. Or, use a classifier at the end to determine output.
分类并执行/Classify-and-act
使用一个分类代理来决定任务类型,然后根据任务路由到不同的代理或行为。或者,在最后使用一个分类器来决定输出。
Fan-out-and-synthesize
Split up a task into many smaller steps, run an agent on each step and then synthesize those results. This is particularly useful for when there are a large number of smaller steps, or when each step benefits from its own clean context window so they don't interfere or cross-contaminate. The synthesize step is a barrier—it waits for all the fan-out agents, then merges their structured outputs into one result.
扇出并综合/Fan-out-and-synthesize
将一个任务拆分成许多更小的步骤,在每个步骤上运行一个代理,然后综合这些结果。当有大量小步骤,或者每个步骤需要自己干净的上下文窗口以避免干扰或交叉污染时,这种模式特别有用。综合步骤是一个屏障——它等待所有扇出代理完成,然后将它们的结构化输出合并成一个结果。
Adversarial verification
For each spawned agent, run a separate spawned agent to adversarially verify its output against a rubric or criteria.
对抗验证/Adversarial verification
对于每个派生的代理,运行一个独立的派生代理来根据评分标准或标准对其输出进行对抗性验证。
Generate-and-filter
Generate a number of ideas on a topic and then filter them by a rubric or by verification, dedupe duplicates and return only the highest quality, tested ideas.
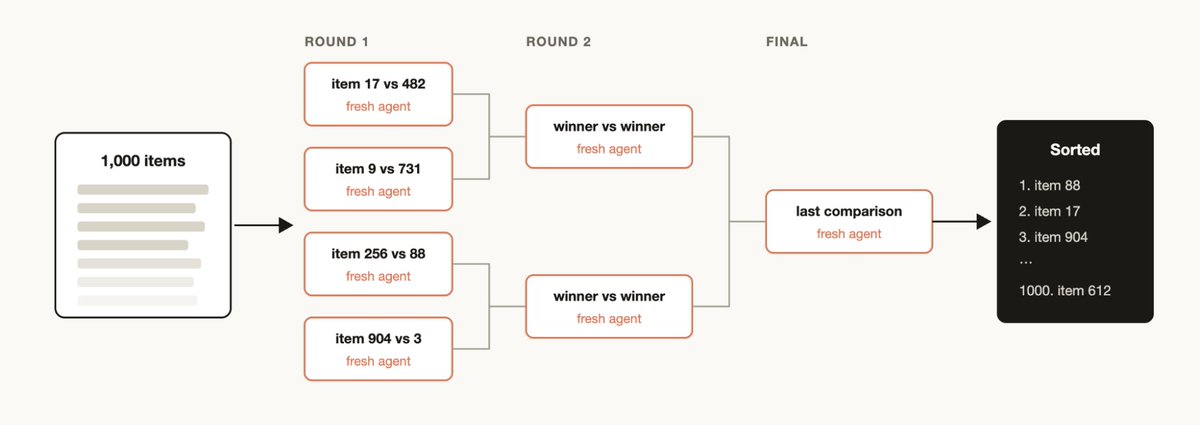
Tournament
Instead of dividing the work, have agents compete on it. Spawn N agents that each attempt the same task using different approaches. Prompts or models then judge the results in a pairwise fashion using a judging agent until you have a winner.
生成并过滤/Generate-and-filter
针对某个主题生成一系列想法,然后通过评分标准或验证进行过滤,去重后只返回最高质量、经过检验的想法。
淘汰赛/Tournament
不是分工,而是让代理相互竞争。派生 N 个代理,每个代理使用不同方法尝试同一任务。然后通过提示词或模型,使用评判代理以两两比较的方式评判结果,直到产生一个胜者。
Loop until done
For tasks with an unknown amount of work, loop spawning agents until a stop condition is met (no new findings, or no more errors in the logs) instead of a fixed number of passes.
循环至完成/Loop until done
对于工作量未知的任务,循环派生代理,直到满足停止条件(没有新发现,或日志中没有更多错误),而不是固定轮数。
Bun was rewritten from Zig to Rust using workflows. You can read more about how that was done in Jarred's X thread.
The key is to break down the task into a series of steps that need to be operated on for example callsites, failing tests, modules, etc. Spin off a subagent for every fix in a worktree to make the fix, then have another agent adversarially review, and merge them. Consider telling the agent not to use resource intensive commands so that you can maximally parallelize without running out of resources on your machine.
Bun 就是使用工作流从 Zig 重写为 Rust 的。你可以在 Jarred 的 X 帖中了解更多详情。
关键在于将任务分解为一系列需要处理的操作对象,例如调用点、失败的测试、模块等。为工作树中的每个修复派生一个子代理来执行修复,然后让另一个代理进行对抗性审查,最后合并。考虑告诉代理不要使用资源密集型命令,这样你就可以在机器资源不耗尽的情况下最大化并行处理。
We published a deep research skill (/deep-research) inside Claude Code that uses dynamic workflows. Specifically, it fans-out web searches, fetches sources, adversarially verifies their claims, and synthesizes a cited report.
But you may do this sort of research for more than just web searches. For example, asking Claude to compile a status report from context in Slack or to research how a feature works by exploring a codebase in-depth.
我们在 Claude Code 中发布了一个深度研究技能(/deep-research),它使用了动态工作流。具体来说,它扇出网页搜索、获取来源、对抗性验证其主张,并综合出一份带引用的报告。
但这类研究不仅仅局限于网页搜索。例如,可以让 Claude 从 Slack 的上下文中整理状态报告,或通过深入探索代码库来研究某个功能的工作原理。
On the other hand, if you have a report where you want to check and source every factual claim that it references you may want to generate a workflow which has one agent identify all of the factual claims and then spin off a subagent to check each one in-detail. You could also have a verification agent check the source subagent to make sure its source is high quality.

You may have a list of items that you want to sort by some qualitative measurement that you believe that Claude Code is good at evaluating, for example: support tickets sorted by severity of the bug. But if you try to sort 1000+ rows in one prompt, quality degrades and it won't fit in context. Instead run a tournament, a pipeline of pairwise-comparison agents (comparative judgment is more reliable than absolute scoring), or bucket-rank in parallel then merge. Each comparison is its own agent, so the deterministic loop holds the bracket and only the running order stays in context.
另一方面,如果你有一份报告,需要核实其中每个事实性主张的来源,你可以生成一个工作流:由一个代理识别所有事实性主张,然后派生子代理逐一详细检查。你也可以让一个验证代理检查来源子代理,确保其来源质量。
你可能有一个条目列表,希望根据 Claude Code 擅长的某种定性度量进行排序,例如按 bug 严重性对支持工单排序。但是,如果试图在一个提示中排序 1000 多行,质量会下降且无法容纳在上下文中。相反,可以运行淘汰赛、两两比较代理的流水线(比较判断比绝对评分更可靠),或并行分桶排名然后合并。每个比较都有自己的代理,因此确定性循环维护着赛程表,只有运行顺序保持在上下文中。
If you have a particular set of rules that you find Claude misses or struggles with, even when put into the CLAUDE.mds, create a workflow with a list of rules that must be checked by verifier agents—one verifier per rule. Creating a skeptic persona subagent to review the rules to make sure they are in line will help avoid too many false positives.
The reverse direction works too: mine your recent sessions and code review comments for corrections you keep making, cluster them with parallel agents, adversarially verify each candidate (would this rule have prevented a real mistake?), and then distill the survivors back into a CLAUDE.md.

Debugging works best when you come up with several independent hypotheses and test them, but if you're only using one context window, Claude can run into self-preferential bias.
A workflow can structurally prevent this by spinning up agents to generate hypotheses from disjoint evidence. For example, separate agents for logs, files, and data. Each hypothesis can then face a panel of verifiers and refuters.
This isn't just for code. Workflows can be used for sales (why did sales drop in March?), data engineering (why did this pipeline fail?), or any post-mortem exercise.
调试的最佳方式是提出几个独立假设并进行测试,但如果只使用一个上下文窗口,Claude 可能会陷入自我偏好偏差。
工作流可以通过从不相交的证据中派生代理来生成假设,从而在结构上防止这种情况。例如,为日志、文件和数据分别设置独立的代理。每个假设随后可以面对一个由验证者和反驳者组成的评审组。
这不仅适用于代码。工作流还可用于销售(为什么三月份销售额下降?)、数据工程(为什么这个流水线失败了?)或任何事后复盘。
Every team has a support queue, bug reports, or some other backlog that cannot be fully processed by humans.
A triage workflow classifies each item, dedupes against what's already tracked, and takes action. This could mean attempting the fix or escalating to a human user.
A useful pattern for triage workflows is quarantine. This involves barring the agents that read untrusted public content from taking high-privilege actions, which are instead done by the agents in charge of acting on the information.
Pair triage workflows with /loop to have Claude do this continuously.

Workflows can be useful when exploring different approaches to a solution, especially when it is taste based, like design or naming, and would benefit from a rubric.
Try asking Claude to explore a bunch of solutions, and give a review agent a rubric for what a good solution looks like. The task is complete when the review agent feels like it has met the criteria. Solutions can also be ordered or selected via a tournament based on the rubric.
每个团队都有支持队列、bug 报告或其他人类无法完全处理的积压工作。
分类/triage 工作流对每个条目进行分类,与已跟踪的条目去重,然后采取行动。这可能意味着尝试修复或上报给人类用户。
分类工作流的一个有用模式是隔离。这包括禁止读取不受信任公共内容的代理执行高权限操作,这些操作由负责根据信息采取行动的代理执行。
将分类工作流与 /loop 配对,让 Claude 持续执行。
在探索不同解决方案时,工作流也很有用,特别是当解决方案基于品味(如设计或命名)并可从评分标准中受益时。
尝试让 Claude 探索多种解决方案,并为审查代理提供一个好解决方案的评分标准。当审查代理认为满足标准时,任务完成。解决方案也可以通过基于评分标准的淘汰赛进行排序或选择。
You can run lightweight evals for particular tasks by spinning off separate agents in a worktree and then spinning off comparison agents to compare and grade the specific outputs against a rubric. For example, evaluating and then refining a skill you've created against a particular criteria.
Create a classifier agent tuned to your tasks that decides which model to use. This can be helpful when your task will involve many tool calls and conducting research prior to execution can identify the best model for the job.
For example, the best model for the task "explain how the auth module works" depends on how many files in the auth module there are and the shape of the codebase. A classifier agent can do this research and then route to Sonnet or Opus based on the expected complexity of the task.
你可以通过在工作树中派生独立的代理,然后派生比较代理来针对特定任务运行轻量级评估:对比特定输出并根据评分标准进行评分。例如,评估然后根据特定标准优化你创建的技能。
创建一个针对你的任务调优的分类器代理,用于决定使用哪个模型。当你的任务涉及大量工具调用,并且在执行前进行研究可以识别最适合该工作的模型时,这会很有帮助。
例如,“解释认证模块如何工作”这个任务的最佳模型取决于认证模块有多少文件以及代码库的结构。一个分类器代理可以进行这项研究,然后根据预期的任务复杂度路由到 Sonnet 或 Opus。
Workflows are new. While there are many use cases where it will create outsized results, they are not needed for every task and may end up using significantly more tokens.
It's best to use workflows creatively to push Claude Code in ways that you haven't previously. For regular coding tasks, try and ask yourself does it really need more compute? For example, most traditional coding tasks do not need a panel of 5 reviewers.
工作流是新鲜事物。虽然在许多用例中它会带来超乎寻常的结果,但并非每个任务都需要它,而且可能会消耗显著更多的 token。
最好创造性地使用工作流,以前所未有的方式推动 Claude Code。对于常规编码任务,试着问自己:它真的需要更多算力吗?例如,大多数传统编码任务并不需要一个 5 人评审团。
Prompting
Detailed prompting, using the specific techniques we described above, for dynamic workflows creates the best results.
Workflows are not just for large tasks. You can prompt the model to use a "quick workflow." For example, you can create a quick adversarial review of an assumption.
Combine with /goal and /loop
When using workflows that can be repeated, for example triage, research, or verification, pair them with /loop to be run at regular intervals, and /goal to set a hard completion requirement.
Token usage budgets
You can set explicit token usage budgets for dynamic workflows to limit how many tokens a task uses. You can prompt it with a budget like: "use 10k tokens," which will set the cap.
Saving and sharing dynamic workflows
You can save workflows by pressing "s" in the workflow menu. You can check these into ~/.claude/workflows or distribute them via a skill.

To share them via a skill, put your JavaScript workflow files in the skill and folder and reference them in the SKILL.MD. To allow for more flexibility, you may want to prompt Claude to think of the workflows in the skill as a template instead of a script that needs to be run verbatim.

提示词技巧
使用上述具体技术为动态工作流编写详细的提示词,能产生最佳效果。
工作流不仅限于大任务。你可以提示模型使用“快速工作流”。例如,你可以为某个假设创建一个快速的对抗性审查。
与 /goal 和 /loop 结合
在使用可重复的工作流时(例如分类、研究或验证),将它们与 /loop 配对以定期运行,并用 /goal 设置硬性完成要求。
Token 预算
你可以为动态工作流设置显式的 token 使用预算,以限制任务消耗的 token 数量。你可以用类似“使用 10k tokens”的预算来提示,这将会设定上限。
保存和分享动态工作流
你可以在工作流菜单中按“s”键保存工作流。你可以将这些文件 check in 到 ~/.claude/workflows 目录,或通过技能/skill 分发。
要通过技能共享,请将你的 JavaScript 工作流文件放入技能文件夹,并在 SKILL.MD 中引用它们。为了获得更大的灵活性,你可能希望提示 Claude 将技能中的工作流视为模板,而不是需要逐字运行的脚本。
Workflows are a helpful new way to extend Claude Code. I encourage you to think of this as a starting point, there's still much to discover in how to use them best. Let us know what you find.
Thariq Shihipar and Sid Bidasaria (@sidbid) are members of technical staff at Anthropic, working on Claude Code.
工作流是扩展 Claude Code 的一种有用的新方法。我鼓励你把这看作一个起点,关于如何最好地使用它们,还有许多有待发现。让我们知道你发现了什么。
Thariq Shihipar 和 Sid Bidasaria(@sidbid)是 Anthropic 的技术员工,负责 Claude Code 工作。