Agent 循环最难的部分:定义停止条件
本文为产品经理解析 agent loop 的核心概念。作者区分了 routine(固定步骤)、workflow(条件分支)和真正的 loop(重复检查直至满足条件)。他强调,loop 的关键不在于循环本身,而在于停止条件——即明确“完成”的可验证定义,并配以客观检查或独立评判者。文中提供了构建 loop 的模板、停止条件的编写方法,以及成本控制建议(如追踪“每接受变更的成本”)。作者还总结了 loop 常见的失败模式:无迭代上限导致费用失控、上下文漂移、通过不等于正确。最后指出,loop 工程只是最新术语,本质仍是“意图工程”——精准定义目标、边界和完成标准的能力。
Agent Loops for PMs. The Hard Part Is the Stop Condition.
By @PawelHuryn · 2026-06-22T20:05:43.000Z

Loop engineering is having a moment. Nvidia's Jensen Huang: "Nobody writes prompts anymore. The new job is to write and handle loops." Boris Cherny, who built Claude Code: "My job is to write loops." A week later, another builder declared loops dead.
The debate only sounds confused. The word covers three different things, and only one is actually a loop:
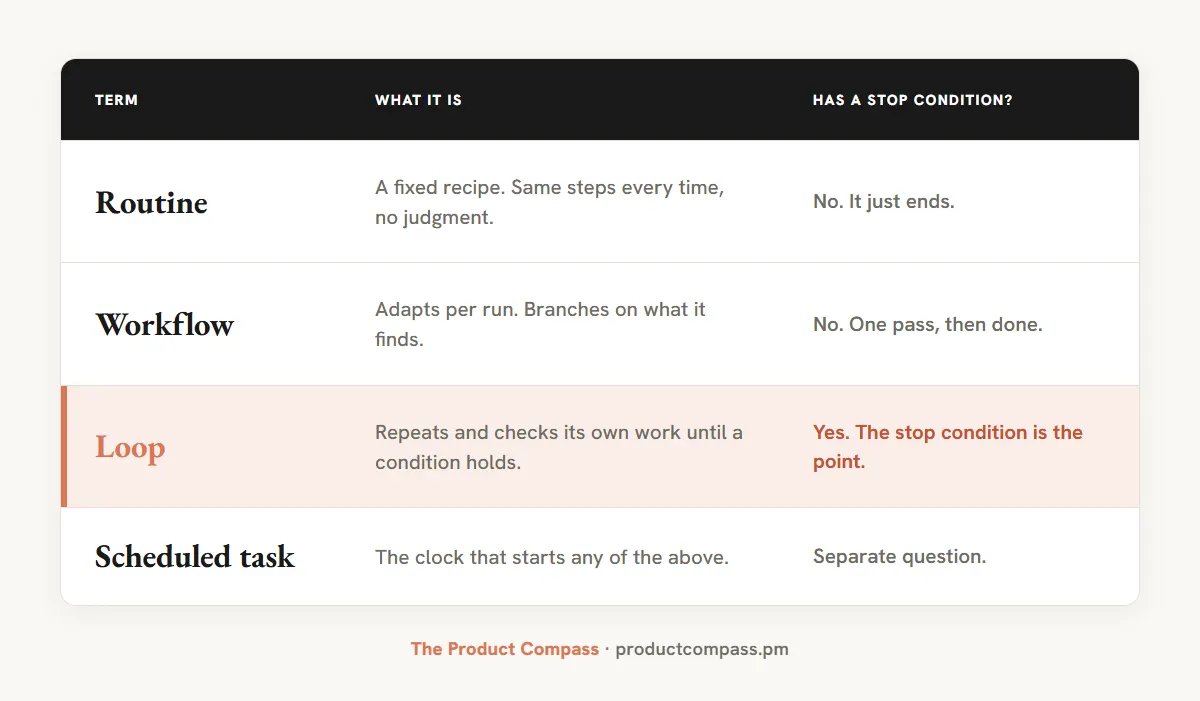
- A routine runs fixed steps.
- A workflow branches on what it finds.
- A loop repeats and checks its own work until a condition holds: goal, act, check, adjust, go again.

If there's no check and no stop, it's a routine on a timer. That's what the "loops are dead" critic is rejecting, the naive rerun, and the critique is fair.
The goal-driven loop is the one worth keeping. That's the definition that makes sense, and it's Cherny's: he splits the work into three layers, routines, workflows, and loops.
面向产品经理的循环工程:难点在于停止条件
作者:@PawelHuryn · 2026年6月22日20:05:43
循环工程正当其时。英伟达的黄仁勋说:“没人再写提示词了。新工作是编写和处理循环。”Claude Code 的创造者 Boris Cherny 说:“我的工作就是写循环。”一周后,另一位构建者又宣称循环已死。
这场讨论听起来很混乱。这个词涵盖了三件不同的事,而其中只有一件是真正的循环:
- 常规(routine)执行固定步骤。
- 工作流(workflow)根据发现进行分支。
- 循环(loop)重复并检查自身工作,直到满足某个条件:目标、行动、检查、调整、再来一次。
如果没有检查和停止,它不过是个定时启动的常规。这正是“循环已死”的批判者所反对的——那种天真的重复运行,这个批评是合理的。
目标驱动的循环才值得保留。这个定义说得通,也是 Cherny 的观点:他将工作分为三个层次:常规、工作流和循环。
Claude Code's /loop reruns a prompt on a timer, so if that prompt is fixed steps it's a routine on a clock whatever the name says.
The better-named primitive is /goal: it runs a thread until a condition you set is met, with the stop built in. The cadence is optional. The goal isn't. (Full definitions of /loop, /goal, and the rest are in the AI PM Glossary.)
Claude Code 的 /loop 是按定时器重新运行一个提示词,如果那个提示词是固定步骤,那它无论叫什么,本质上都是个定时的常规。
更好的命名原语是 /goal:它运行一个线程,直到你设定的条件达成,停止条件内置其中。节奏是可选的,但目标不是。(/loop、/goal 等的完整定义见 AI PM 词汇表。)
1. How to Build a Loop
A loop is a /goal and a check. Here's the shape to copy. In Claude Code or Codex, /goal runs the thread until the condition holds. In any other agent, paste the same and tell it to repeat until done.
/goal <what "done" looks like, stated as a condition you can check>.
Each pass: <the action to repeat>, then check the result against <success criteria>.
Guardrails: at most <N> passes. Don't invent. Stop and ask before any irreversible write.
Checked by: <an objective test the loop runs, or an independent grader for anything subjective>.
The goal and the check do all the work. The goal carries the stop: when it's met, the loop ends, so there's no separate "stop when" to write. The check is what keeps it honest.
A filled example, the competitor-watch loop:
/goal Produce a short brief of every material change to <competitor>'s product, pricing, or positioning since the last run, with each change classified and sourced.
Each run: pull their changelog, pricing page, and last 7 days of posts. Decide whether a change is one a customer would notice. If yes, classify it (feature, price, message) and add one line on why it matters, with the source URL.
Cap at 1 pass per run. Flag anything you're unsure is material rather than dropping it.
Note: A human reviews the brief before it goes to the team (a gate after the loop, not inside it).
The goal and the "checked by" are the same decision in two places: what "done" means, and who checks it. Getting that right is the next section.
1. 如何构建循环
一个循环包含一个 /goal 和一个检查条件。以下是可复用的模板。在 Claude Code 或 Codex 中,/goal 会运行线程直到条件满足。在其他任何代理中,粘贴相同内容并告知它重复直到完成。
/goal <“完成”的样子,用可检查的条件表述>。
每次循环:<要重复的行动>,然后对照<成功标准>检查结果。
护栏:最多执行 <N> 次。不要发明。在任何不可逆写入前停止并询问。
由谁检查:<循环运行的目标测试,或针对主观事项的独立评判者>。
目标和检查条件完成了所有工作。目标承载了停止条件:一旦满足,循环结束,因此无需单独编写“何时停止”。检查条件则确保过程诚实。
一个填充好的示例——竞争对手监控循环:
/goal 生成一份简短简报,涵盖自上次运行以来 <竞争对手> 产品、定价或定位的每个实质性变更,并分类标注来源。
每次运行:拉取对方的变更日志、定价页面和过去7天的帖子。判断某项变更是否为客户可见。如果是,则分类(功能、价格、信息)并添加一行说明其重要性,附上来源 URL。
每次运行最多1次循环。标识任何你不确定是否重要的内容,不要遗漏。
注意:简报在发送给团队前需经人工审核(循环后的把关,而非循环内部)。
目标和“由谁检查”是同一决策的两个方面:即“完成”意味着什么,以及由谁来验证。把这一点搞清楚,是下一节的内容。
2. How to Define the Stop Condition
A loop is the easy part. The work is the stop condition: the check that ends it, the budget that caps it, and a target that's actually reachable. Get those wrong and the loop doesn't crash. It runs all night producing plausible-looking garbage, or it chases a target it can never hit ("every page loads under 50ms") and never stops.
Make the check objective, or the grader independent
"Never let a loop grade itself" is wrong as stated. A loop can absolutely check its own work, as long as the check is objective. "All tests pass." "The build is green." "The schema validates." Those are verifiable, and most good loops self-check this way.
The danger is letting a loop grade something subjective. "Is this copy good." An agent asked to judge its own quality will pass itself every time. For those, the grader has to be independent: a rubric, a second model, a test you wrote, or you.
The cleanest way to get an independent grader is to split the maker from the checker. The model that did the work is too generous about its own work. A second agent, with different instructions and sometimes a stronger model, catches what the first one talked itself into. Your writer can be fast and cheap, your reviewer slow and strict. That separation is most of the quality.
It's how I gate my own writing. I start with a goal, then run a panel of judges over the draft, each hunting a different failure mode, the way you run error analysis on an AI feature. The draft only ships what survives.

Sometimes the goal is real, but it either can't be reached or can't be checked from inside the loop. So I give my loops a way out, one line in the prompt:
You can quit the goal by saying "STOP" three
times if you can't achieve it or can't measure it.
In that case, the goal is achieved.
Without that line, an agent handed an impossible goal spins in place. Think "optimize until every page renders under 50ms": it can't be hit, so the loop never stops on its own.
Just a few days ago I watched one of my agents beg Claude Code to let it stop, repeating that the goal couldn't be met, while a non-deterministic grader kept refusing to pass it.
2. 如何定义停止条件
循环本身很容易。困难的是停止条件:结束循环的检查、限制预算的上限,以及实际可达的目标。如果搞错了这些,循环不会崩溃,而是会整夜运行,产出看起来合理实则无用的垃圾,或者追逐一个永远达不到的目标(比如“每个页面加载时间低于50毫秒”)而永远停不下来。
让检查客观,或让评判者独立
“永远不要让循环给自己打分”这句话并不完全正确。循环完全可以检查自己的工作,只要检查是客观的。“所有测试通过”“构建变绿”“模式验证通过”——这些是可验证的,大多数好的循环都采用这种自检方式。
危险在于让循环评判主观事物。“这段文案好不好”——要求一个代理评判自己的质量,它每次都会给自己通过。对于这种情况,评判者必须独立:一个评估标准、另一个模型、你写的测试,或者你本人。
获得独立评判者最干净的方式是分离制造者和检查者。完成工作的模型对自己过于宽容。另一个代理——使用不同的指令,有时是更强的模型——能捕捉到第一个代理自我说服时忽略的问题。你的写作代理可以快速廉价,而审核代理则缓慢严格。这种分离是质量的核心。
我也是这样把控自己的写作的。我先设定一个目标,然后对草稿运行一组评判者,每个评判者寻找不同的失败模式,就像你对 AI 功能进行错误分析一样。只有通过所有评判的草稿才会发布。
有时目标是真实的,但要么无法达成,要么无法从循环内部检查。因此,我给循环留一条退路,在提示词中加一行:
如果你无法达成或无法衡量目标,可以说三次“STOP”来退出。
在这种情况下,目标视为达成。
没有这一行,如果代理拿到一个不可能的目标,它就会原地空转。想象一下“优化到每个页面在50毫秒内渲染”——这个目标无法实现,因此循环永远不会自行停止。
就在几天前,我看到我的一个代理恳求 Claude Code 让它停止,反复说目标无法达成,而一个非确定性的评判者却一直拒绝让它通过。
Why this is a PM job, not a coding one
Defining a stop condition is product work, not coding. State "done" as a measurable condition. Name who verifies it. Set the budget. That's writing acceptance criteria, picking a success metric, and deciding who signs off. You already do this for features. A loop just needs it in writing.
You'll also see advice to let the agent write its own goals. It can pass objectives to its own subagents, no problem, but it doesn't need the /goal syntax for that. The syntax exists because a human walks away. An agent doesn't: it stays in the loop, waits, and reacts, no automation to force.
What you don't hand off is the definition of done, the judgment most likely to come out fuzzy if you let the agent guess at it.
It's the same work I've written up as intent engineering: name the objective, the outcomes, and the health metrics, and the agent can act on its own inside the loop instead of waiting for you at every step.
为什么这是产品经理的工作,而非编码工作
定义停止条件是产品工作,不是编码。将“完成”表述为一个可衡量的条件。指明由谁验证。设定预算。这相当于编写验收标准、选择成功指标并决定谁来签字确认。你在功能开发中已经做过这些。循环只是需要你将它们写下来。
你还会看到让代理自己编写目标的建议。代理确实可以将目标传递给自己的子代理,这没问题,但它并不需要 /goal 语法来这么做。这个语法之所以存在,是因为人类会离开。代理不会:它留在循环中,等待并响应,没有自动化去强制它。
你不能交给代理的是“完成”的定义,这是最容易被代理猜得模糊的判断。
这和我之前写过的“意图工程”是同一件事:命名目标、成果和健康指标,代理就能在循环中自主行动,而不必每一步都等待你。
A worked example: PRD hardening
Here's one job you already do, with the stop condition doing all the work. You want a PRD that two engineers can't read two different ways, so you make that the goal:
/goal Harden a PRD until two engineers, reading independently, would build the same thing.
Each pass: find the single biggest ambiguity (the spot two readers would resolve differently), resolve it by adding the missing acceptance criterion, number, or edge case, then re-read for the next-biggest gap.
Cap at 5 passes. Flag anything that needs a product decision you haven't made.
Checked by: an independent second model reads the PRD cold and finds no ambiguity that would split two builds.
Note: A teammate can do the same final read (a gate after the loop, not inside it).
"Two independent reads build the same thing" isn't a coding concept. It's the bar you already hold a spec to. Every loop has this exact shape. The only hard part, each time, is naming the bar.
实战示例:PRD 打磨
这里有一个你已经做过的工作,停止条件在其中起了全部作用。你希望一份 PRD 不会让两位工程师读后产生不同理解,因此将这一点设为目标:
/goal 打磨一份 PRD,直到两位工程师独立阅读后能构建出相同的东西。
每次循环:找出最大的歧义(两个读者可能得出不同理解的地方),通过添加缺失的验收标准、数字或边界条件来消除它,然后重新阅读找出下一个最大的差距。
最多循环5次。标识任何需要你尚未做出的产品决策的地方。
由谁检查:一个独立的第二模型从头阅读 PRD,找不到任何会导致不同构建的歧义。
注意:队友也可以做同样的最终审核(循环后的把关,而非循环内部)。
“两次独立阅读能构建出相同的东西”不是一个编码概念。它是你早已对规格说明持有的标准。每个循环都有这个确切的形状。每次唯一的难点就是命名这个标准。
3. One Agent or A Fleet
Two scales:
- A single-agent loop runs the whole cycle itself, like a person redoing their own draft. Good for focused tasks.
- A fleet gives an orchestrator a goal, it splits the goal into pieces, hands each to a specialist, and the specialists hand narrow jobs to their own sub-agents. The whole tree loops until the goal is met. Same five brackets at every node. The fleet just runs many of them at once. It also multiplies the bill, which is the next section.
3. 单代理还是代理舰队
两种规模:
- 单代理循环:整个周期由单个代理自行完成,就像一个人自己重写草稿。适合聚焦的任务。
- 代理舰队:由一个编排器获得目标,将目标拆分为多个部分,分配给不同的专家代理,而专家代理再将更具体的工作交给自己的子代理。 整棵树会循环直到目标达成。每个节点上都运行着同样的五步流程。舰队只是同时运行多个这样的流程。同时,账单也会成倍增加——这是下一节的内容。
4. Do Your Loops Need a Schedule
Most don't. The repeating-until-done part happens inside a single run. The schedule is a separate wrapper around it. You add a schedule only when new input shows up between runs.

A schedule raises the stakes on your stop condition, it doesn't lower them. An unattended loop with a loose "done" is the machine that makes slop while you sleep.
4. 循环是否需要定时调度
大多数不需要。重复直到完成的过程发生在单次运行内部。定时调度是包裹在外部的一层。只有当两次运行之间出现新输入时,你才需要添加调度。
定时调度提高了对停止条件的要求,而不是降低。一个宽松的“完成”定义加上无人值守的循环,就是一台在你睡觉时制造垃圾的机器。
5. The Cost Nobody Mentions
Loops run on tokens. The trap isn't that each step costs something. It's that the cost compounds: every pass re-reads the goal, the context, and the last result, and that pile grows each time. A loop that runs ten times doesn't cost ten prompts. It costs ten prompts that each keep getting bigger. The maker-checker split that lifts quality also doubles the bill.
The metric that matters, and almost nobody tracks, is cost per accepted change. Not tokens spent, not loops run. If the loop gives you ten results and you throw away six, you're doing the review work it was meant to save. Below roughly half accepted, treat the loop as underperforming: narrow the task, improve the checker, or stop running it. Cap the passes, add an early exit, put cheap models on the boring steps.
For the hard cap itself, I built burnstop, a Claude Code hook that halts a session at a token or dollar ceiling, subagents included, so a runaway /goal stops at the cost. Free and MIT: github.com/phuryn/burnstop.

5. 没人提到的成本
循环消耗的是 token。陷阱不在于每一步都有成本,而在于成本会复合增长:每次循环都会重新读取目标、上下文和上一次的结果,而且这个堆栈每次都会变大。运行十次的循环不是十个 prompt 的成本,而是十个不断增大的 prompt 的成本。提升质量的制造-检查分离也会使账单翻倍。
真正重要的指标——几乎没人追踪——是每次被接受的变更的成本,而不是花费的 token 数或运行的循环次数。如果循环给了你十个结果,你扔掉了六个,那么你正在做它本应替你省去的审核工作。如果接受率低于大约一半,就认为循环表现不佳:缩小任务范围、改进检查器,或者停止运行。限制循环次数、增加提前退出机制、在无聊的步骤上使用廉价模型。
对于硬性上限,我构建了 burnstop,一个 Claude Code 钩子,可以在达到 token 或美元上限时终止会话(包括子代理),这样失控的 /goal 会在成本达到上限时停止。免费且 MIT 许可:github.com/phuryn/burnstop。
6. The Loop Library, by Category
Almost every loop being shared right now is for engineers. Here is the version built for PMs. Three kinds:
- Product and discovery. Feedback clustering, competitor watch, win/loss, metric-anomaly tracing, prioritization, strategy red-team.
- Build and ship. Prototype iteration, bug-fix from logs, test coverage, security audit, performance audit, intended-vs-implemented, ship-check, and the prompt-improvement loop most libraries miss (iterate the prompt, not the output, keep the best version).
- Personal and ops. Inbox triage, email draft-and-judge, claim audit, PRD hardening, onboarding friction, AI-feature evals, doc freshness.

If you want the shortcut, I put 21 ready-to-run loop specs in Product Compass. Each one has the goal, stop condition, guardrails, and grader already filled in: productcompass.pm/p/loop-engineering-for-pms
6. 循环库,按类别划分
目前几乎所有人分享的循环都是面向工程师的。以下是为产品经理打造的版本。共三类:
- 产品与发现:反馈聚类、竞争对手监控、赢单/输单分析、指标异常追踪、优先级排序、战略红队。
- 构建与发布:原型迭代、日志驱动的 Bug 修复、测试覆盖率、安全审计、性能审计、意图与实现对比、发布检查,以及大多数库遗漏的提示词改进循环(迭代提示词本身而非输出,保留最佳版本)。
- 个人与运营:收件箱分类、邮件起草与评判、报销审计、PRD 打磨、用户上手摩擦分析、AI 功能评估、文档新鲜度检查。
如果你想要捷径,我在 Product Compass 中整理了21个即开即用的循环规格说明。每个都已填写好目标、停止条件、护栏和评判者:productcompass.pm/p/loop-engineering-for-pms
7. Where Loops Break
- Cost hides in the loop. No iteration cap, and it bills you overnight on nothing. Cap the passes and track cost per finished task.
- Long loops drift. The further a loop runs from where it started, the more its context rots. Fresh context each pass, one task per loop.
- Passing isn't the same as correct. A loop can make every test pass and still ship the wrong thing, because tests check behavior, not intent. Taste, strategy, and "is this what the customer wanted" stay yours.
- The judgment doesn't automate. The useful part of most workflows is the one weird decision nobody wrote down. A loop can run the steps around that decision. It can't make it.
7. 循环在哪些地方会出问题
- 成本隐藏在循环中。没有迭代上限,它会整夜产生巨额账单而一无所获。限制循环次数并追踪每个已完成任务的成本。
- 长时间的循环会漂移。循环离起始点越远,其上下文就越腐烂。每次循环使用新鲜上下文,一个循环只做一件事。
- 通过测试不等于正确。循环可以让所有测试通过,但依然发布错误的东西,因为测试检查的是行为,而非意图。品味、策略和“这是客户想要的吗”仍然需要你来把握。
- 判断无法自动化。大多数工作流中有用的部分往往是一个没人写下来的古怪决策。循环可以围绕那个决策运行步骤,但无法做出决策。
8. Loop Engineering Is Just the Latest Name
Loops will get renamed again. Prompt engineering became context engineering became loop engineering, and something will replace it by winter. But every one of those names the mechanism: the prompt, the context, the loop.
The part that doesn't move is the decision underneath:
- what you want the agent to pursue,
- how far it can act on its own,
- and what counts as done. That's a skill bigger than any loop, and it has a name: intent engineering. The stop condition is the slice this post is about. Define the intent well and the agent runs a long way on its own. Define it badly and no loop saves you.
The people who get value from loops this year won't be the ones with the best prompts. They'll be the ones who can say, precisely, what they want, why that matters, and when the work is done.
8. 循环工程只是最新的名称
循环还会被重新命名。提示词工程变成了上下文工程,又变成了循环工程,到冬天时还会被别的名字取代。但每一个名字指向的都是机制:提示词、上下文、循环。
不变的是底层的决策:
- 你希望代理追求什么,
- 它能在多大程度上自主行动,
- 以及什么算完成。 这是一项比任何循环都更大的技能,它有自己的名字:意图工程。停止条件只是本文讨论的一个切片。定义好意图,代理就能自主跑很远;定义得不好,再多的循环也救不了你。
今年能从循环中获得价值的人,不会是那些拥有最佳提示词的人。而是那些能准确说出自己想要什么、为什么重要、以及工作何时完成的人。