Claude Managed Agents 推出「梦境」、成果评估与多智能体编排
Anthropic 在 Claude 托管代理中引入了「梦境」功能(研究预览),可跨会话审视记忆、提取模式并自我改进。同时推出成果评估(定义成功标准,由独立评估器评分,自动修正直至达标)和多智能体编排(主代理拆解任务,子代理并行处理)。文章提供了内部测试数据:成果评估在困难任务上提升 10 个百分点,docx/pptx 生成质量分别提升 8.4% 和 10.1%;并展示了 Harvey(法律工作完成率提升 6 倍)、Netflix(并行分析构建日志)、Spiral(用成果评估控制写作质量)、Wisedocs(文档审查提速 50%)等案例。适合关注 AI 代理自动化、质量控制和复杂任务分解的一线工程师。
Today we're launching dreaming in Claude Managed Agents as a research preview. Dreaming extends memory by reviewing past sessions to find patterns and help agents self-improve. We're also making outcomes, multiagent orchestration, and webhooks available to developers building with Managed Agents. Together, these updates make agents more capable at handling complex tasks with minimal steering.
今天,我们在 Claude 托管代理中推出「梦境」(研究预览),这是一种通过回顾过往会话、发现模式来扩展记忆、帮助代理自我改进的机制。同时,我们还将成果评估、多智能体编排和 webhook 开放给开发者使用。这些更新共同提升了代理处理复杂任务的自主能力。
Dreaming is a scheduled process that reviews your agent sessions and memory stores, extracts patterns, and curates memories so your agents improve over time. You decide how much control you want: dreaming can update memory automatically, or you can review changes before they land.
梦境是一个定时过程:审视代理的会话与记忆存储,提取模式并整理记忆,让代理持续改进。你可以选择控制粒度:梦境可自动更新记忆,也可在落地前由你审核。
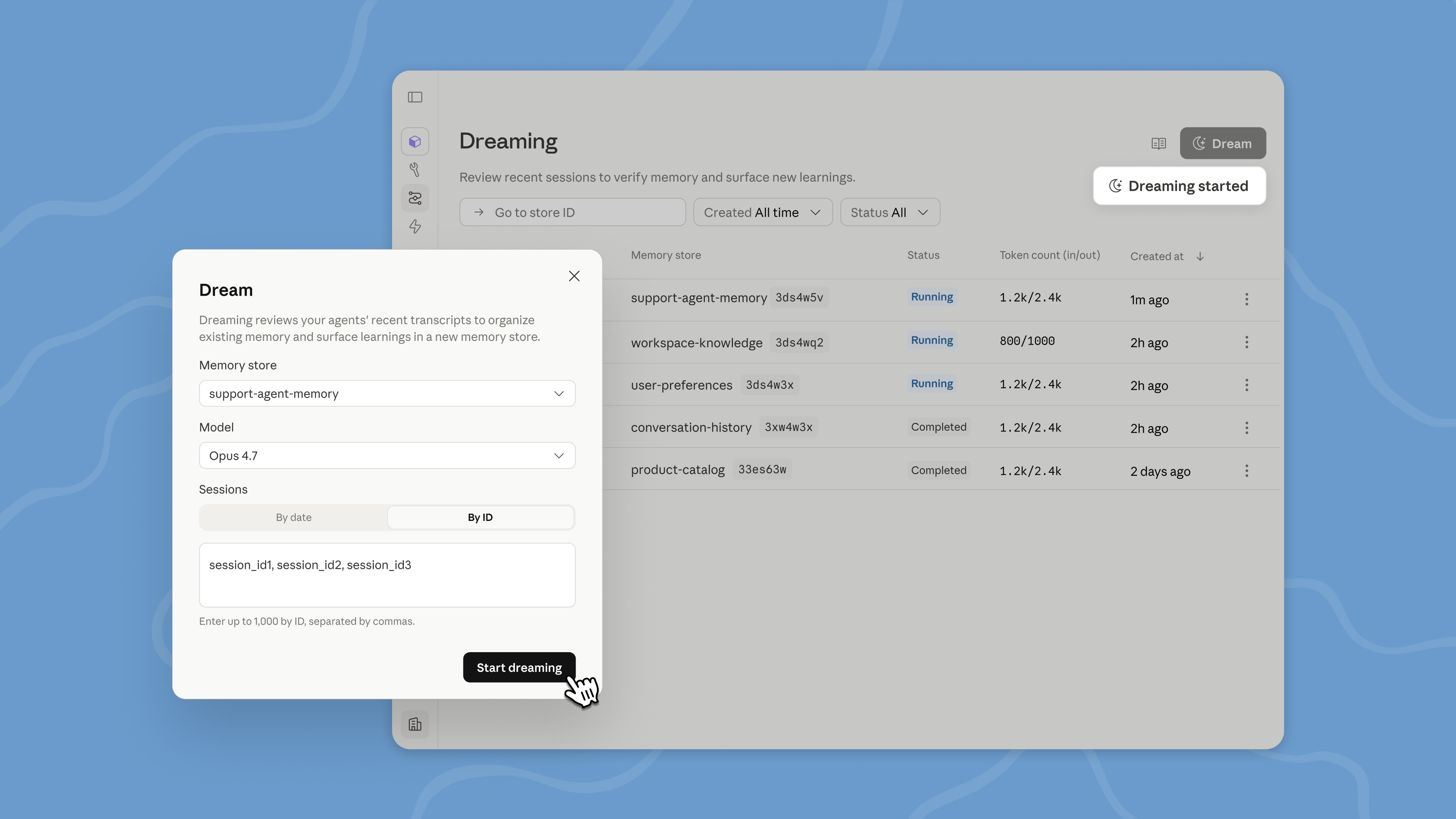
Dreaming surfaces patterns that a single agent can't see on its own, including recurring mistakes, workflows that agents converge on, and preferences shared across a team. It also restructures memory so it stays high-signal as it evolves. This is especially useful for long-running work and multiagent orchestration.
梦境能提取单个代理无法自行发现的模式:重复错误、代理趋同的工作流、团队共性偏好等。它还会对记忆进行重构,使其随时间保持高信息密度。这对长期任务和多智能体编排尤其有用。
Together, memory and dreaming form a robust memory system for self-improving agents. Memory lets each agent capture what it learns as it works. Dreaming refines that memory between sessions, pulling shared learnings across agents and keeping it up-to-date.
记忆与梦境共同构成了一个健壮的自改进记忆系统:记忆让每个代理记录工作中的经验,梦境则跨会话提炼共享知识并保持更新。
With outcomes, you write a rubric describing what success looks like and the agent works toward it. A separate grader evaluates the output against your criteria in its own context window, so it isn't influenced by the agent's reasoning. When something isn't right, the grader pinpoints what needs to change and the agent takes another pass.
成果评估允许你用一份评分标准定义成功,代理据此工作。独立的评估器在自己上下文中评估输出,不受代理推理影响。若结果不达标,评估器指出修改方向,代理再次尝试。
Agents do their best work when they know what "good" looks like. For example, a structural framework, a presentation standard, or a set of requirements that need to be met. With outcomes, agents can check their work against that bar and self-correct until the output is good enough, without a human needing to review each attempt.
当代理知道「好」的标准时表现最佳——例如结构框架、演示标准或需求清单。成果评估让代理自行比对标准并自纠正,无需人工逐次审核。
Outcomes is particularly useful for tasks that require attention to detail and exhaustive coverage. It also works for subjective quality, like whether copy matches a brand voice or a design follows visual guidelines. In testing, outcomes improved task success by up to 10 points over a standard prompting loop, with the largest gains on the hardest problems. Outcomes also improved file generation quality, with +8.4% task success on docx and +10.1% on pptx in our internal benchmarks.
成果评估对注重细节和全面覆盖的任务尤其有效,也适用于主观质量(如文案匹配品牌调性、设计遵循视觉规范)。测试中,成果评估相比标准提示循环将任务成功率提升了多达 10 个百分点,困难问题增益最大;内部基准中,docx 生成任务成功率 +8.4%,pptx +10.1%。
You can also now define an outcome, let the agent run, and get notified by a webhook when it's done.
你现在还可以设定成果,让代理运行,完成后通过 webhook 接收通知。
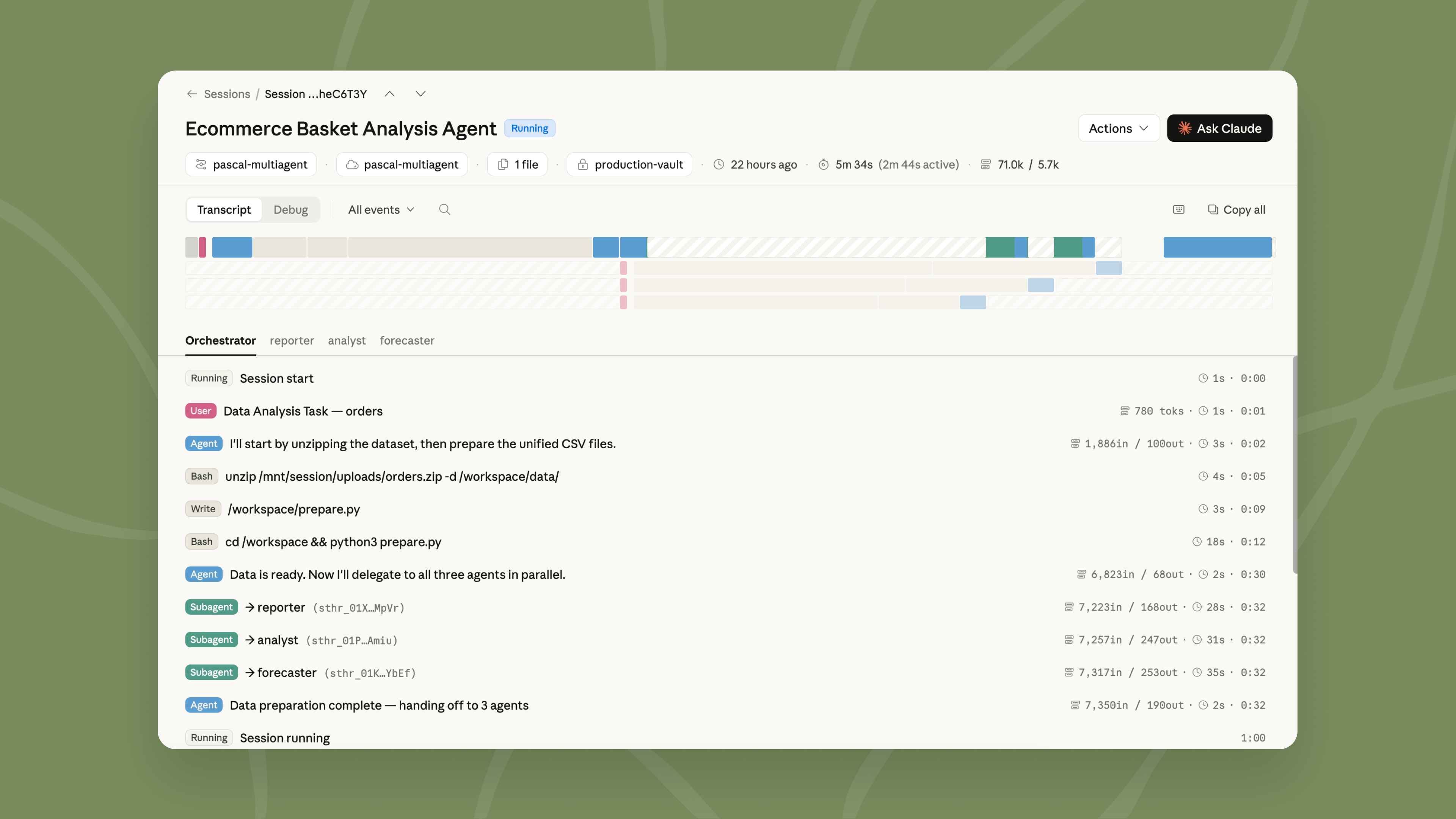
When there is too much work for a single agent to do well, multiagent orchestration lets a lead agent break the job into pieces and delegate each one to a specialist with its own model, prompt, and tools. For example, a lead agent can run an investigation while subagents fan out through deploy history, error logs, metrics, and support tickets.
当单个代理难以胜任大量工作时,多智能体编排允许主代理将任务拆解,委派给各自拥有独立模型、提示和工具的专家子代理。例如,主代理主持调查,子代理分头查阅部署历史、错误日志、指标和支持工单。
These specialists work in parallel on a shared filesystem and contribute to the lead agent's overall context. The lead agent can check back in with other agents mid-workflow because events are persistent and every agent remembers what it's done. You can also trace every step in the Claude Console: which agent did what, in what order, and why, giving you full visibility into how your task was delegated and executed.
子代理在共享文件系统上并行工作,结果汇入主代理上下文。由于事件持久化且每个代理都记忆自己的行动,主代理可在工作流中期再次调度其他代理。在 Claude 控制台中可追溯每一步:哪个代理做了什么、顺序及原因,清晰展示任务委派和执行全貌。
Harvey uses Managed Agents to coordinate complex legal work like long-form drafting and document creation. With dreaming, their agents remember what they learned between sessions, including filetype workarounds and tool-specific patterns. Completion rates went up ~6x in their tests.
Harvey 利用托管代理协调长文起草、文档创建等复杂法律任务。借助梦境,代理跨会话记忆学习内容,包括文件类型变通方法和工具特定模式。测试中完成率提升约 6 倍。
Netflix's platform team built an analysis agent that processes logs from hundreds of builds across different sources. With changes that affect thousands of applications, what matters is finding the issues that recur across many of them. Multiagent orchestration lets the agent analyze batches in parallel and surface only the patterns worth acting on.
Netflix 平台团队构建了一个分析代理,处理不同来源的数百次构建日志。面对影响数千应用的大规模变更,关键是发现重复出现的问题。多智能体编排让代理并行分析批次,仅提取值得处理的模式。
Spiral by Every is using multiagent orchestration and outcomes to power the writing agent behind their new API and CLI. The lead agent runs on Haiku: it fields incoming requests, poses quick follow-up questions when needed, then delegates the drafting to subagents running on Opus. When a user asks for multiple drafts, the subagents run in parallel. Writing quality is Spiral's core value, so they use outcomes to enforce it. Each draft is scored against a rubric of Every's editorial principles and the user's voice, both pulled from memory. Only drafts that clear the bar are returned.
Every 的 Spiral 使用多智能体编排和成果评估驱动其新 API 和 CLI 背后的写作代理。主代理运行在 Haiku 上:接收请求,必要时快速追问,随后把起草委派给在 Opus 上的子代理。若用户要求多份草稿,子代理并行工作。写作质量是 Spiral 的核心价值,因此他们用成果评估强制达标:每份草稿根据 Every 的编辑原则和用户风格(均从记忆提取)进行评分,仅通过门槛的草稿才返回。
Wisedocs built a document quality check agent on Managed Agents, using outcomes to grade each review against their internal guidelines. Reviews now run 50% faster, while staying aligned with their team's standards.
Wisedocs 在托管代理上构建了文档质量检查代理,用成果评估按内部准则对每次审查评分。审查速度提升 50%,同时符合团队标准。
Dreaming is available in research preview, outcomes, multiagent orchestration, and memory are available in public beta as part of Managed Agents. To get started with dreaming, request access here. Explore our documentation to learn more or visit the Claude Console to deploy your first agent.
梦境功能处于研究预览阶段;成果评估、多智能体编排和记忆功能已作为托管代理的公测版本可用。要开始使用梦境,请申请访问。查阅文档或访问 Claude 控制台部署你的第一个代理。