从写提示词到设计循环:Agent Loop 工程实战指南
AI 编码圈正从“写提示词让 agent 干活”转向“设计循环让 agent 自己干活”。本文是最接地气的实操版:什么是 agent loop,为什么它重要,生产环境里长什么样。作者拆解了 loop 的六个固定部件(触发、隔离、上下文固化、工具连接、独立评审、持久化状态),并用 PR babysitter(每15分钟检查PR,CI红则自动修复一次)和 Claude Code 的 /goal 命令作为具体例子。文章还讨论了 loop 的成本模型(迭代次数才是预算线,弱验证器是最贵的 bug)、何时不该用 loop(一次性修改、无明确通过条件的探索性工作)、以及常见的失败模式(验证负担转嫁给人、代码理解债累积、宽松检查导致无声漂移)。
A claim has been circulating in AI coding circles: stop prompting your coding agents and start designing loops that prompt them for you. As with everything new, this stuff gets repeated often and explained rarely. This is the practical version: what an agent loop is, why it matters, and what one looks like in production.
Below you can read some of my thoughts (written with the help of Claude) from some of the experiments, research, and conversations I’ve been having with some of our students, technical founders, AI engineers, and startups.
You might also find our recent live session on "Autonomous Long-Running Coding Agents" as a good starting point for all of this.
AI 编程圈里流传着一个说法:别再自己提示你的编程代理了,设计一个循环,让循环来帮你提示它。和所有新事物一样,这话被反复复述,却很少被解释清楚。这里是实用版本:什么是代理循环/agent loop,它为什么重要,以及它在生产环境中长什么样。
下面你可以读到我的一些思考(在 Claude 辅助下撰写),这些思考源于我的一些实验、研究,以及与我的一些学生、技术创始人、AI 工程师和初创公司的交流。
你可能会觉得我们最近的线上直播“自主长期运行的编程代理”是个不错的起点。
"You shouldn't be prompting coding agents anymore. You should be designing loops that prompt your agents."Peter Steinberger (@steipete), Jun 7 2026. 2.2M views. Original tweet
Boris Cherny, the creator of Claude Code, makes the same point from the other side.
"I don't prompt Claude anymore. I have loops that are running. They're the ones that are prompting Claude and figuring out what to do. My job is to write loops."Boris Cherny (@bcherny). Original tweet
The point is not that prompt engineering is dead. With loop engineering, the work moves up a level, from writing the code to writing the system that writes the code. Developers furthest along this path report months where they shipped hundreds of PRs without opening an IDE, with every line written by the agent.
“你不再应该亲自提示编程代理了。你应该设计一个循环,让循环来提示你的代理。” —— Peter Steinberger (@steipete),2026年6月7日,220万次观看。原始推文
Claude Code 的创造者 Boris Cherny 也从另一个角度呼应了这个观点。
“我不再提示 Claude 了。我有一些正在运行的循环。是它们在提示 Claude 并决定下一步做什么。我的工作是编写这些循环。” —— Boris Cherny (@bcherny)。原始推文
要点不在于提示工程/prompt engineering已死。通过循环工程,工作重心上移了一个层次:从编写代码,转变为编写生成代码的系统。走在这条路上最远的开发者反馈,他们数月间在不打开 IDE 的情况下交付了数百个 PR,每行代码都由代理编写。
A loop is a small program you write that does four things:
- prompts the coding agent for you,
- reads what it produced,
- decides whether it is done,
- and if not, prompts it again with the error or the next step.
You stop sitting inside the loop typing prompts; you write the loop, and the model becomes a subroutine it calls.

The shape is always the same: set a goal, act, check, feed the error back, and repeat until the check passes or the loop stops itself.
循环就是一段你编写的小程序,它做四件事:
- 替你提示编程代理,
- 读取它生成的内容,
- 判断任务是否完成,
- 如果没完成,则带着错误信息或下一步指示再次提示它。
你不再坐在循环里面手动输入提示;你编写这个循环,而模型则成为它调用的一个子程序。
结构始终如一:设定目标、执行、检查、反馈错误,然后重复,直到检查通过或循环自行停止。
Much of the disagreement is people using one word for five different ideas. Here is the progression, oldest to newest.

- ReAct (2022). The original research pattern: reason, act, observe, repeat.
- AutoGPT (2023). A self-prompting goal loop, notorious for not knowing when to stop.
- ralph loop. A deliberate context reset between iterations so the agent does not drown in its own history.
- /loop and /goal. Cadence and completion conditions are built into the agent, carrying the state across turns.
- orchestration. One author fans out many agents that read your GitHub, Slack, and chat, and decide what to build next.
许多争议源于人们用一个词指代了五种不同的概念。这是从最早到最新的演进过程。
- ReAct (2022)。最初的研究模式:推理、行动、观察、重复。
- AutoGPT (2023)。一种自我提示的目标循环,因不知道何时停止而臭名昭著。
- ralph 循环。在迭代之间有意识地重置上下文,以防代理被自己的历史记录淹没。
- /loop 和 /goal。将节奏和完成条件内置于代理中,在轮次间传递状态。
- 编排/orchestration。一个主控派出多个代理,读取你的 GitHub、Slack 和聊天记录,并决定接下来构建什么。
The progression explains what people mean by loop; this is what a loop is built from. The same six parts show up every time, and most now ship inside the coding tools instead of custom scripting you maintain yourself.

- A trigger. Something that starts the loop without you pressing go: a schedule, a webhook, a file change, a label landing on a PR. This is what separates a real loop from a single run you repeat by hand.
- Isolation. A private checkout per agent, usually a git worktree, so two agents running at once cannot overwrite each other's files. Once you run more than one, this stops being optional.
- Written-down context. The conventions, build steps, and project-specific rules are kept where the agent reads them on every run. Skip it, and the loop re-derives your project from scratch each pass and guesses at the gaps.
- Reach into your tools. Connectors to the issue tracker, CI, database, and chat, so the loop can open the PR, link the ticket, and post the result instead of printing a fix and waiting for you to carry it the rest of the way.
- A second agent checks. A separate worker who grades the output is held apart from the one who produced it, because a model reviewing its own work passes almost everything.
- State on disk. A markdown file, a board, or a queue: anything outside the conversation that records what is finished and what is next. The model forgets between runs; the file does not.
Assemble those six, and you have a good starting point for loop engineering. You used to hand-build everything; now most ship as built-in features, which is why the pattern has moved from a fringe technique into common use.
上面的演进解释了人们所说的“循环”具体指什么;而以下是构成循环的基本元素。每次构建都会出现相同的六个部分,如今大多数都已内置于编程工具中,不再需要你自行编写自定义脚本。
- 触发器/trigger。无需你手动启动就能开始循环的东西:一个计划任务、一个 webhook、一个文件变更、或是一个 PR 被标记。这是真正的循环与手动重复执行单次运行之间的区别。
- 隔离/isolation。每个代理使用独立的代码检出(通常是 git worktree),这样同时运行的两个代理便不会互相覆盖文件。一旦运行多于一个代理,这就是强制要求。
- 文档化的上下文/written-down context。将约定、构建步骤和项目特定规则保存在代理每次运行都能读取的地方。跳过这一步,循环每次都会从头重新推导你的项目,并对空白部分进行猜测。
- 工具集成/reach into your tools。连接到问题追踪器、CI、数据库和聊天的接口,让循环可以直接打开 PR、关联工单、发布结果,而不是打印一个修复方案等你手动完成后续工作。
- 检查代理/second agent checks。一个独立的工作器来评估输出,它不同于生成输出的代理,因为模型自我审查几乎会放行一切。
- 磁盘持久化状态/state on disk。一个 Markdown 文件、看板或队列:任何存在于对话之外,可以记录已完成和下一步事项的载体。模型会在两次运行之间遗忘;但文件不会。
组装好这六部分,你就有了循环工程的良好起点。过去你需要手动构建一切;但现在大部分功能都作为内置特性提供了,这就是该模式从边缘技术转向普遍应用的原因。
A concrete example you can build today:

- Trigger. Every 15 minutes.
- Scope. Open PRs labeled agent-watch.
- Action. If CI is red for a deterministic reason, attempt one fix. If the main moved, rebase once.
- Budget. One fix attempt per PR, five minutes, ten files changed.
- Stop condition. CI green, or budget exhausted, then stop and ping a human.
You return to merged PRs instead of a backlog of broken builds. The same shape covers most ops work:
- CI health. Every 30 minutes, pull failing runs and cluster them by signature, so ten red PRs with one root cause become one thing to look at.
- Deploy verification. After a push, hit your endpoints, confirm 200s and the expected content, and flag regressions before users do.
- Feedback clustering. Every 30 minutes, pull comments from your channels, group them into themes, and map each cluster to the file or doc that owns it.
一个今天就可以构建的具体示例:
- 触发器。每 15 分钟一次。
- 范围。标记为
agent-watch的待处理 PR。 - 动作。如果 CI 因确定原因变红,尝试修复一次。如果主分支有更新,执行一次变基/rebase。
- 预算。每个 PR 尝试一次修复,限时 5 分钟,最多修改 10 个文件。
- 停止条件。CI 变绿,或预算耗尽,然后停止并通知人工。
最终你将收获合并的 PR,而不是一堆损坏的构建。同样的模式也适用于大多数运维工作:
- CI 健康检查。每 30 分钟拉取失败的构建,并按签名分类,这样十个由同一个根因导致的红色 PR 可以归结为一个需要关注的问题。
- 部署验证。在推送后,访问你的端点,确认返回 200 状态码和预期内容,在用户之前发现回归。
- 反馈聚类。每 30 分钟拉取来自你各个渠道的评论,按主题分组,并将每组映射到相应的文件或文档。
The babysitter is a loop you wire up yourself; it also helps to see one that ships inside the agent. In Claude Code, the smallest complete loop is /goal: you hand it a verifiable end state, and it keeps taking turns until that state is true.
Here is an example of /goal used as an in-session command in Claude Code. You launch the session, then set the goal inside it:
$ claude # launch Claude Code
$ /goal tests in test/auth pass # set the goal inside the session
It is the same act, check, repeat shape from earlier, with the verifier built in.
At this point, it’s clear that a strong /goal reads less like a prompt and more like a contract. The good ones specify four things: the end state you want, the evidence that proves you reached it, the constraints the agent must not break getting there, and the budget of work it is allowed to spend. Leave any one of them vague, and the model fills the gap with the easiest reading: it stops early, takes a shortcut, or redefines success so the transcript looks done while the real system is broken.
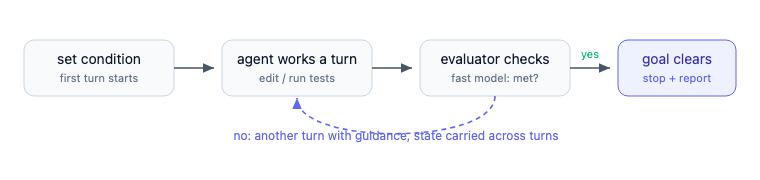
- Set the condition. Type /goal plus a checkable end state, for example,
/goal tests in test/auth pass. The first turn starts immediately. - The agent works a turn. It edits, runs the tests, and surfaces the results in the session.
- An evaluator checks. A fast model reads the transcript and decides whether it is met or not met, so the agent is not grading its own work.
- Loop or finish. Not met means another turn with guidance; met means the goal clears itself and the run stops.
State carries across turns, so it does not quit early or drop a constraint partway through. A few controls keep it reliable:
- Make the check measurable. A test result, an exit code, a file count, or an empty queue.
npm test exits 0is a goal; "make it better" is not. - Bound the run. Append something like "or stop after 20 turns" so a stuck loop halts instead of burning turns.
- Pair it with auto mode so that turns run unattended, and use /goal clear to abandon it early.
The evaluator step hides a useful subtlety: the checker does not have to be the same model as the coder. Once the loop has distinct roles (planner, executor, evaluator, vision reviewer), each can run on a different model, and choosing which model fills which role becomes an architecture decision rather than a single bet on one "best" coding agent. Some models plan better, some execute more cheaply, some judge a screenshot more accurately, and a good orchestrator lets you swap them per role instead of waiting for one vendor to win every category.
It works well for API migrations (move every call site until it compiles and tests pass), refactors (split a file until each module is under budget), issue backlogs (work a labeled queue until it is empty), and eval loops (tune a prompt until the score clears a threshold). /loop is the counterpart for work with no single finish line: instead of a completion condition it re-prompts on a schedule, which is how a loop like the PR babysitter keeps running.
“PR 保姆”是你自行搭建的循环;同时,了解一个内置于代理中的现成循环也很有帮助。在 Claude Code 中,最小的完整循环是 /goal:你给它一个可验证的最终状态,它会持续执行轮次,直到该状态变为真。
下面是在 Claude Code 中使用 /goal 作为会话内命令的一个示例。你启动一个会话,然后在其中设定目标:
$ claude # 启动 Claude Code
$ /goal tests in test/auth pass # 在会话中设定目标
这与前文提到的执行、检查、重复的结构相同,只是内置了验证器。
至此,一个明确的 /goal 更像是一份契约,而非一个提示。优秀的 /goal 会明确以下四点:你想要的最终状态、证明你已达成状态的证据、代理在达成过程中不得破坏的约束、以及允许其花费的工作预算。任其一个模糊不清,模型就会用最省事的理解来填补空白:它会提前停止、走捷径,或者重新定义“成功”,使得记录看起来完成了,而实际系统却是坏的。
- 设定条件。输入
/goal加上一个可检查的最终状态,例如/goal tests in test/auth pass。第一个轮次立即开始。 - 代理执行一个轮次。它编辑代码、运行测试,并在会话中呈现结果。
- 评估器检查。一个快速的模型读取会话记录,并判断目标是否达成,这样代理就不会自我评分。
- 循环或结束。未达成则进入带有指导的下一个轮次;已达成则目标自行清除,运行停止。
状态在轮次间传递,因此它不会提前退出或因中途丢失约束而停止。几个控制项使其保持可靠:
- 确保检查可度量。一个测试结果、退出码、文件计数或空队列。
npm test exits 0是一个目标;“让它更好”则不是。 - 设定运行边界。添加类似“或 20 轮后停止”的规则,以防止卡住的循环无休止地消耗轮次。
- 将其与自动模式配对,使轮次可以无人值守运行,并使用
/goal clear提前放弃。
评估器步骤隐藏了一个有用的微妙之处:检查模型不必与编程模型相同。一旦循环具有不同的角色(规划器、执行器、评估器、视觉审查员),每个角色都可以由不同的模型担任,而选择哪个模型担任哪个角色就成为一个架构决策,而不是押注于单一“最佳”编程代理。一些模型更擅长规划,一些执行成本更低,一些评估截图更准确,一个好的编排器让你可以为每个角色切换模型,而不是等待一家供应商在所有类别中胜出。
它在以下场景中表现良好:API 迁移(移动每个调用点直到编译通过且测试通过)、重构(拆分文件直到每个模块都在预算内)、问题积压(处理标记队列直到清空)和评估循环(调整提示直到分数超过阈值)。/loop 则是针对没有单一终结点的工作的对应物:它不是设定一个完成条件,而是按计划重新提示,这正是“PR 保姆”这类循环持续运行的方式。
A single /goal loop is one agent working toward one finish line. Running many unattended processes raises the stakes, because a loop is only as trustworthy as its ability to check its own work. Cherny's setup for running Opus autonomously for hours comes down to five steps:
- Auto-approve permissions so the agent does not stop to ask on every tool call.
- Use dynamic workflows (drop Ultracode into the prompt) to fan out across many agents instead of one serial thread.
- Use /goal or /loop to keep it going. /goal sets a completion condition, /loop re-prompts on a schedule, and both carry state, so it does not quit early.
- Run it in the cloud (desktop or mobile app) so the session survives when you close the laptop.
- Give it a way to self-verify end-to-end. Claude in Chrome for web, a simulator MCP for mobile, and a live server for backend. This is the step that makes the other four safe.
The full sequence:
claude --permission-mode auto # 1 · no approval prompts
ultracode orchestrate sub-agents to ship the feature # 2 · fan out
/goal all tests pass and the demo loads clean # 3 · keep going
→ cloud / desktop app # 4 · close the laptop
→ chrome ext · sim MCP · live server # 5 · self-verify, then halt
单个 /goal 循环是一个代理为一个目标工作。同时运行多个无人值守进程则提高了风险,因为循环的可信度完全取决于其自我检查的能力。Cherny 让 Opus 自主运行数小时的设置可归结为五个步骤:
- 自动批准权限,这样代理就不会在每次调用工具时停下来询问。
- 使用动态工作流(将 Ultracode 放入提示中)以扩展到多个代理,而不是一个串行线程。
- 使用
/goal或/loop保持运行。/goal设定完成条件,/loop按计划重新提示,两者都传递状态,因此不会提前退出。 - 在云端运行(桌面或移动应用),这样即使合上笔记本电脑,会话也不会中断。
- 为其提供端到端的自我验证方式。使用 Chrome 中的 Claude 进行 Web 验证,使用模拟器 MCP 进行移动端验证,使用实时服务器进行后端验证。这一步使得前四步变得安全。
完整序列:
claude --permission-mode auto # 1 · 无需审批提示
ultracode orchestrate sub-agents to ship the feature # 2 · 扩展到多个代理
/goal all tests pass and the demo loads clean # 3 · 持续运行
→ cloud / desktop app # 4 · 合上笔记本
→ chrome ext · sim MCP · live server # 5 · 自我验证后停止
Orchestration is easier to picture with a concrete tool. Peter Steinberger's crabfleet, an OpenClaw project billed as "mission control for agent runs," is a loop packaged as a product, and its shape maps onto everything above.
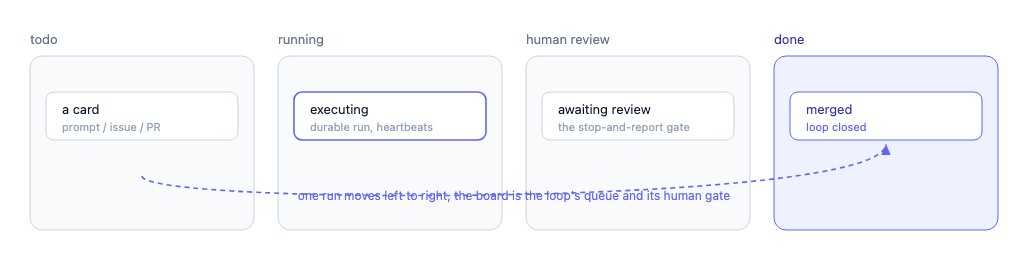
- Work as cards on a board. Tasks are entered as cards built from a prompt, a GitHub issue, or a PR, then move through todo, running, human review, and done. That board is the loop's queue and its stop-and-report step, made visible.
- Durable runs, not fire-and-forget. Each run is a tracked attempt with heartbeats, so it keeps going when you look away and survives a closed laptop. You take over only when the runtime advertises that it supports handoff.
- Agents that spawn agents. A run can start child sessions, send messages, read transcripts, and update its own summary from inside a sandbox: on-disk memory and fan-out in one place, one author and many agents.
It runs on disposable cloud sandboxes with browser-based terminals, which is what makes walking away from an unattended run safe. The point is not the specific tool but that the loop has hardened into infrastructure: a queue, durable execution, fan-out, and a human-review gate are now things you configure rather than hand-script every time.
编排系统借助具体工具更容易形象化。Peter Steinberger 的 crabfleet,一个自诩为“代理运行任务控制中心”的 OpenClaw 项目,就是将循环打包成产品的一个实例,其结构与上述所有概念完美对应。
- 工作项作为看板上的卡片。任务以卡片形式输入,可源自一个提示、一个 GitHub Issue 或一个 PR,随后在待办、运行中、人工审查和已完成状态间流转。这块看板既是循环的队列,也是其“停止并报告”的环节,且完全可视化。
- 持久运行,而非发射后不管。每次运行都是一个带有心跳信号的受追踪尝试,因此即使你移开视线或合上笔记本电脑,它也能继续运行。只有当运行时明确支持交接时,你才需要接手。
- 能生成代理的代理。一次运行可以在沙箱内启动子会话、发送消息、读取记录并更新自身的摘要:将磁盘内存和扇出集于一处,一个主控者,多个代理。
它运行在可丢弃的云端沙箱上,配有基于浏览器的终端,这使得你可以安全地离开无人值守的运行。重点不在于具体的工具,而在于循环已经固化为基础设施:队列、持久化执行、扇出和人工审查关卡,现在都变成你可以配置的东西,而不再是每次手动脚本。
For two years, the cost question in AI coding was simple: which model, and how many tokens. Inside a loop, that instinct points at the wrong layer. The spend is no longer a single call but how many times the loop goes around, so a loop that retries six times before it converges costs six times as much as one that lands on the first pass, on the same model.
That changes what is worth optimizing:
- Iterations are the budget line, not tokens. A cheaper model that loops twice as often is not cheaper, so track cost per finished task, not cost per call.
- A weak verifier is the most expensive bug you can ship. If the check that decides "done" is loose, the loop either stops early on broken work or grinds on work that was already fine, and both waste whole iterations. Tighten this before anything else.
- Failing fast is a cost control. A loop with no cap on consecutive failures does not eventually succeed; it eventually drains the account, so the stop condition protects the bill as much as the codebase.
You used to tune the prompt; now you tune the loop, because that is where the cost accumulates.
两年来,AI 编程的成本问题很简单:用哪个模型,以及多少 token。但在循环内部,这种直觉指向了错误的层面。开销不再是单次调用,而是循环跑了多少次。因此,一个需要重试六次才能收敛的循环,与一次成功的循环相比,在相同的模型上成本是六倍。
这改变了优化的价值点:
- 迭代次数是预算线,而不是 token。一个更便宜但循环次数翻倍的模型并不便宜,所以要追踪每个完成任务的平均成本,而非每次调用的成本。
- 一个弱的验证器是你可能部署的最昂贵的 bug。如果判断“完成”的检查很宽松,循环要么在损坏的代码上提前停止,要么在已经完好的代码上徒劳运转,两者都浪费了整个迭代周期。务必优先收紧这个环节。
- 快速失败也是成本控制。没有连续失败上限的循环最终不会成功;它最终会掏空你的账户。因此,停止条件在保护代码库的同时,也保护了你的账单。
过去你优化提示;现在你优化循环,因为这才是成本累积的地方。
Loops pay off when a task repeats, and a machine can tell when it is done. Outside that, a loop only automates churn. Skip it in these cases:
- One-shot edits. If you can finish it in a single pass, a loop is pure overhead.
- Unscoped or exploratory work. "Figure out why users are churning" has no pass condition, so the loop never converges.
- Anything without a cheap automated check. If the only verifier is your own eyes, you are still inside the loop. Build the check first, or do the task by hand.
循环在任务可重复且机器能判断完成条件时能发挥价值。除此之外,循环只是在自动化一种空转。在以下情况下跳过它:
- 一次性编辑。如果单次操作就能完成,循环纯粹是额外开销。
- 无范围或探索性工作。“找出用户流失的原因”没有通过条件,因此循环永远不会收敛。
- 任何缺乏廉价自动化检查的任务。如果唯一的验证者是自己的眼睛,那你依然身处于循环之中。先构建检查,或者手动完成该任务。
A loop that runs while you sleep also makes mistakes while you sleep, and the failure modes are predictable.
- The verification burden stays human. The loop writes faster than you can review, so if you stop reading the diffs, you have not removed the work, only deferred it.
- Comprehension gaps widen. Shipping code you did not write, faster than you can absorb it, erodes the model of your own system, and that debt comes due during the next incident.
- Silent drift on a loose check. A weak verifier lets wrong-but-passing work through on every iteration, so the loop looks productive while it digs a hole.
None of this is an argument against loops; it is why the engineer who designs the loop matters more, not less.
在你睡觉时运行的循环,也在你睡觉时犯错,这些故障模式是可以预测的。
- 验证负担依然落在人身上。循环写代码的速度比你审查的速度快。如果你停止阅读代码差异/diff,你并没有消除这份工作,只是将它推迟了。
- 理解鸿沟会加深。交付你未编写、且吸收速度跟不上其写入速度的代码,会侵蚀你对自身系统的理解模型,这笔债会在下一次事故中到期。
- 宽松检查导致的无声漂移。一个弱的验证器会在每次迭代中放行“虽然错误但能通过检查”的代码,因此循环看起来很有生产力,实则在挖坑。
这些都不是反对循环的理由;相反,它们恰恰说明了设计循环的工程师为何变得更加重要,而非相反。

- Pick one repeatable task. Babysitting PRs, fixing CI, verifying deploys: start with routine work.
- Scope it tight. "Fix the billing webhook validation, only touch app/api/billing and lib/billing," beats "fix the bug." A loose loop wanders.
- Give it a budget and a stop condition. Max attempts, max runtime, max files, max spend, max consecutive failures. A loop running unattended is also a loop making mistakes unattended.
- Add an independent verifier. A separate sub-agent grades the work, because the agent who wrote the code is the worst judge of whether it is done.
- Run it on a cadence. /loop for an interval, cron for a schedule, hooks at lifecycle points, or GitHub Actions so it survives a closed laptop.
- Keep memory on disk. The model forgets between runs, so state lives in markdown or a board, not in the context window.
The takeaway: the loop, not the model, is now the expensive and failure-prone part. Build it like someone who intends to stay the engineer responsible for the output, not just the person who starts the run.
If you see any errors or things that need further clarification, don’t be afraid to reach out.
- 选择一个可重复的任务。比如照看 PR、修复 CI、验证部署:从常规工作开始。
- 严格界定范围。“修复计费 webhook 验证,只改动
app/api/billing和lib/billing” 优于“修复那个 bug”。一个范围宽松的循环容易偏离方向。 - 设定预算和停止条件。最大尝试次数、最长运行时间、最多文件数、最大花费、最大连续失败次数。无人值守的循环也是无人值守地犯错。
- 添加独立的验证器。一个单独的子代理评估工作,因为编写代码的代理是判断任务是否完成的最差人选。
- 按节奏运行。使用
/loop设定间隔,使用 cron 制定计划,在生命周期点设置钩子,或使用 GitHub Actions,这样即使合上笔记本电脑也能继续运行。 - 在磁盘上保存记忆。模型会在两次运行之间遗忘,因此状态应存放在 Markdown 文件或看板中,而非上下文窗口里。
要点:现在昂贵且容易出问题的部分不再是模型,而是循环。构建它时,要像你依然是最终对产出负责的工程师那样,而不仅仅是启动运行的人。
如果你发现任何错误或需要进一步澄清的地方,请随时联系。