微代理:在模型API层内协作,超越前沿模型
vLLM Semantic Router 提出了一个不同寻常的视角:路由器不只是请求分发器,更是模型能力的放大器。其核心思想是将多个模型的协作封装在同一个模型 API 调用内,用户看到的仍然是一个普通模型端点(vllm-sr/auto),但背后路由器可以根据任务自动选择协作模式——从成本感知的串行升级(Confidence)、并行聚合(Ratings),到多轮推理合成(ReMoM)、分歧发现(Fusion),乃至带资源预算的微代理工作流(Workflows)。这些模式都是可控、可配、可观测的运行时,而非应用层胶水代码。评测显示,在 LiveCodeBench、GPQA-Diamond、Humanity's Last Exam 三个硬基准上,这套闭源模型协作方案(VSR Closed)分别达到 92.6%、96.0%、50.0%,持平或超过了 Fugu Ultra、GPT-5.5 等单一前沿模型。这篇博文的价值在于,它首次把“多模型协作”从产品端或应用端下沉到了 serving 基础设施层,并且坚持以一个模型身份暴露,极大降低了接入成本。适合正在构建推理路由、多模型策略或成本优化方案的工程师阅读。
Everyone is watching for the next frontier model.
The more interesting layer may be the one in front of it.
Routers are becoming the control plane for AI inference. Their first role was practical: route the right request to the right model. That already matters because production AI is no longer a one-model world.
A router can cut cost by deciding when a request deserves a frontier model and when an open-source or local model is enough. It can make safety policy executable by sending sensitive domains to stricter models, stricter filters, or stronger review paths. It can coordinate cloud and edge, keeping private or low-latency intent local while escalating harder work to the cloud.
每个人都在等待下一代前沿模型。
但更有趣的层次可能就在模型的前面。
路由器正在成为 AI 推理的控制平面。它们的第一个角色很务实:将正确的请求路由到正确的模型。这一点已经很关键,因为生产环境中的 AI 不再是单一模型的世界。
路由器可以决定一个请求是否值得动用前沿模型,而用开源或本地模型是否足够,从而降低成本。它可以将敏感领域发送到更严格的模型、过滤器或审核路径,从而让安全策略变得可执行。它还可以协调云端和边缘,将私有或低延迟的意图留在本地,而将更困难的工作升级到云端。
Those are important jobs.
But the next router job is more interesting:
A router can make the model better.
Not by changing weights. Not by asking every application to build a bespoke agent graph. By turning one model API call into a bounded collaboration inside the serving layer.
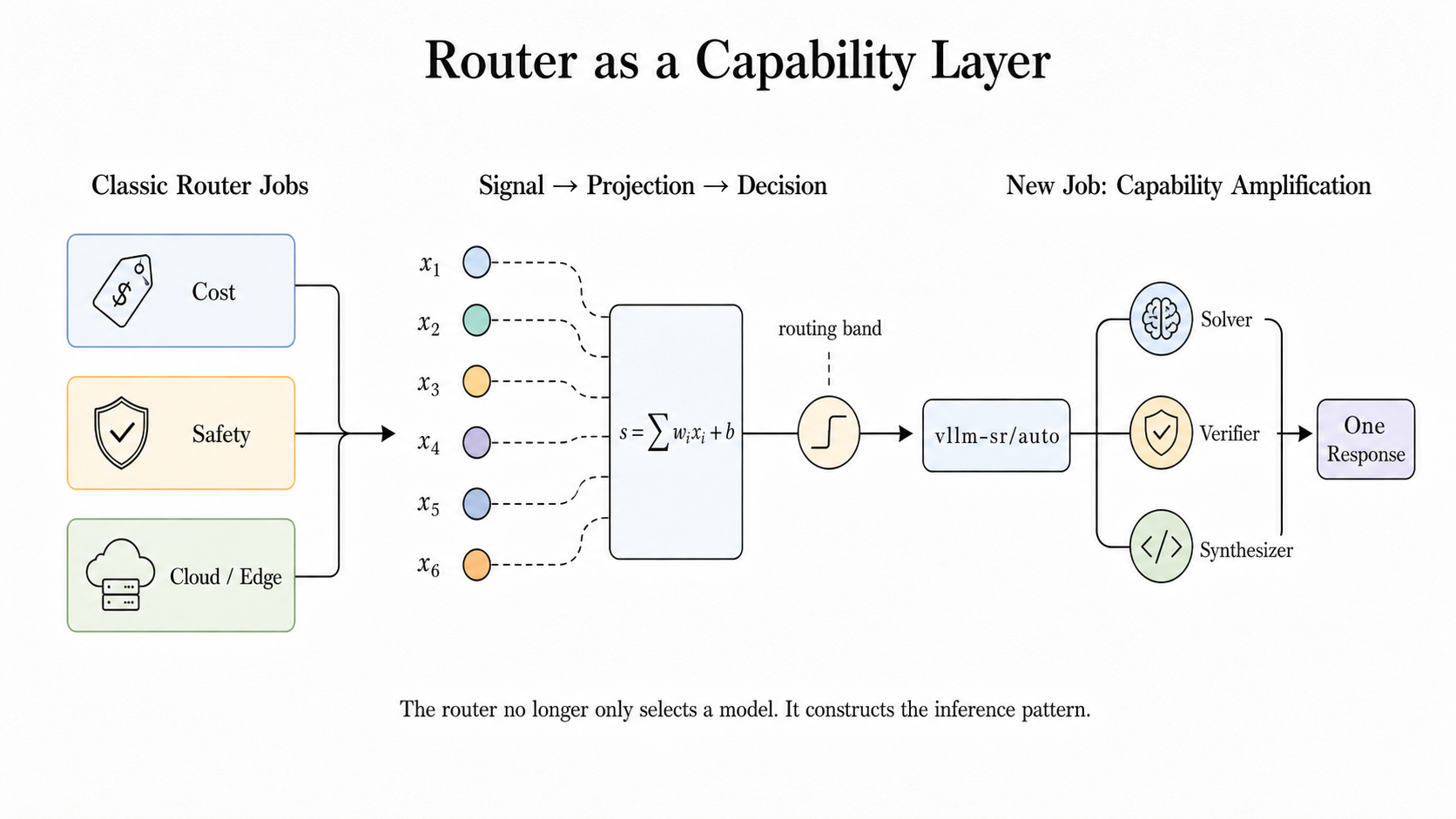
Figure 1: The router is moving from model selection to capability construction.
这些都是重要的工作。
但路由的下一个任务更有趣:
路由器可以让模型变得更好。
不是通过改变权重。也不是要求每个应用都构建定制的 agent 图。而是通过将一次模型 API 调用转化为服务层内部一个有边界的协作。
图 1:路由器正从模型选择转向能力构建。
This is why Sakana Fugu landed so loudly: it made a commercial product out of a simple but powerful idea, that a "model" can be a surface, and behind that surface can be a team. The research around this idea, including the Fugu technical report and coordination papers such as Conductor and Trinity, gives useful language for thinking about orchestration.
But the vLLM Semantic Router vision is different in where it puts the abstraction. Collaboration should not live only inside one commercial endpoint or one application-specific agent graph. It should become an open serving primitive.
vLLM Semantic Router brings that idea into the open serving layer. The user still calls one model:
{
"model": "vllm-sr/auto",
"messages": [{"role": "user", "content": "..."}]
}
Behind that stable model identity, the router can select a recipe, fan out to workers, collect a quorum, verify disagreement, synthesize a final answer, repair the output contract, and return one normal OpenAI-compatible response.
The point is not to expose complexity.
The point is to make collaboration feel like a model.
这就是 Sakana Fugu 引起轰动的原因:它将一个简单而强大的想法做成了商业产品——即一个“模型”可以是一个表面,而在这个表面背后可以是一个团队。围绕这个想法的研究,包括 Fugu 技术报告以及 Conductor 和 Trinity 等协调类论文,为思考编排提供了有用的语言。
但 vLLM Semantic Router 的愿景在抽象层次上有所不同。协作不应该只存在于一个商业端点或一个应用特定的 agent 图中。它应该成为一个开放的服务原语。
vLLM Semantic Router 将这个想法带入了开放的服务层。用户仍然只调用一个模型:
{
"model": "vllm-sr/auto",
"messages": [{"role": "user", "content": "..."}]
}
在这个稳定的模型身份背后,路由器可以选择一个配方,向工作节点分发任务,收集法定人数,验证分歧,综合最终答案,修复输出契约(contract),并返回一个正常的、兼容 OpenAI 的响应。
关键不在于暴露复杂性。
关键在于让协作感觉起来就像个模型。
The Looper Is the Runtime
In vLLM Semantic Router, the looper is the execution runtime for bounded micro-agents.
A request enters the router as an ordinary chat completion. The router extracts signals, projects them into task-shape or risk bands, matches a decision, and then chooses an algorithm. That algorithm may be a normal single-model route, or it may be a looper route.
Today, the main looper patterns are:
Confidence: a sequential escalation loop. It tries a cheaper candidate first, measures confidence, and escalates only when the score is too low.
Ratings: a bounded fan-out loop. It runs multiple candidates under a hard concurrency cap and aggregates them with rating-aware weights.
ReMoM: repeated mixture-of-model reasoning. It fans out breadth samples, waits for enough successful responses, and runs a final synthesis round.
Fusion: a panel-judge-final pattern. Independent model responses become evidence for a judge and finalizer.
Workflows: a micro-agent workflow runtime. It supports static roles or a dynamic planner, executes bounded worker steps, and synthesizes a final response.
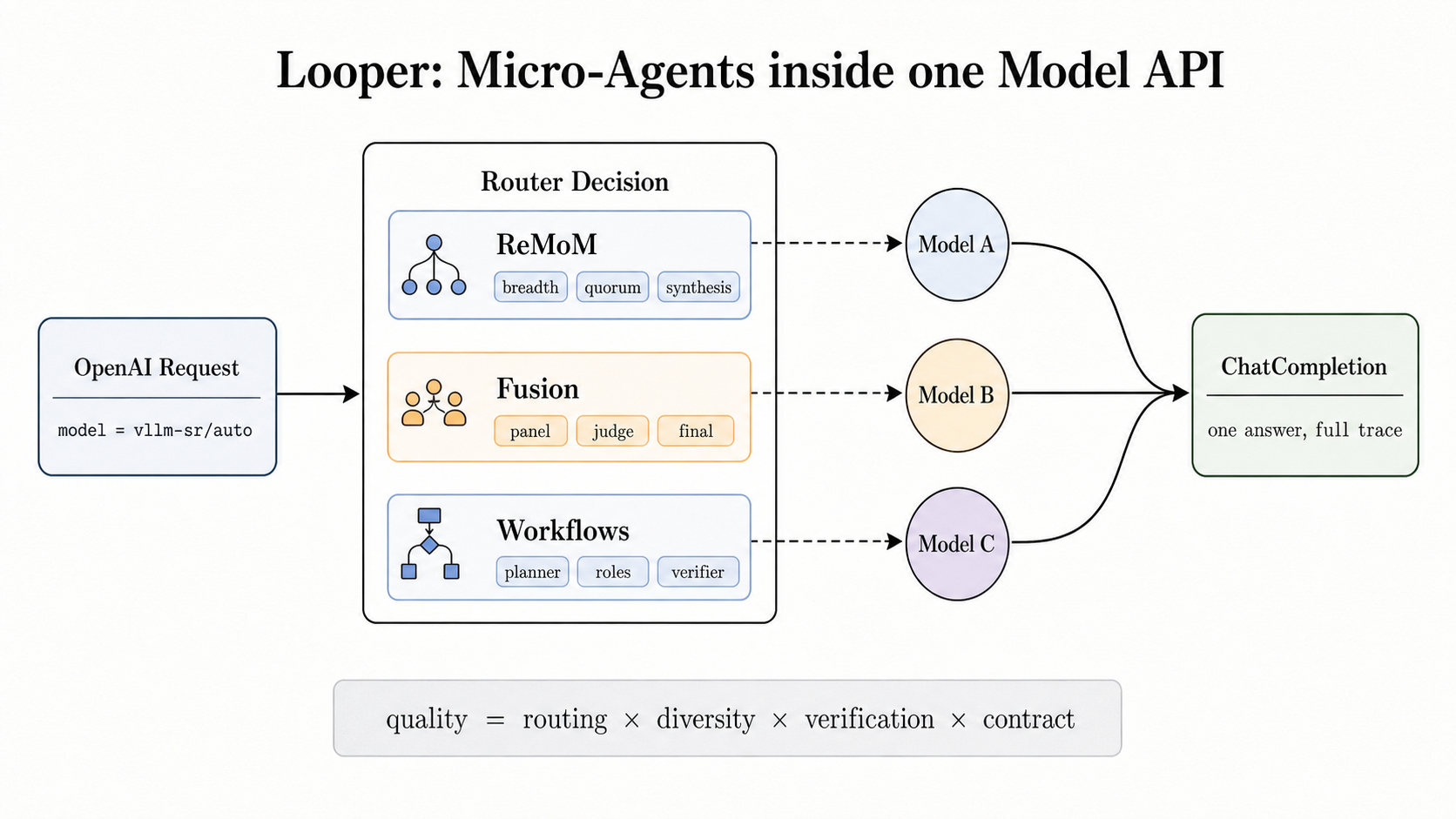
Figure 2: Looper algorithms run inside the router while preserving the model API surface.
The implementation details matter. A looper is not a slogan for "ask more models." It is a small runtime with budget, topology, trace, and failure policy.
Looper 是运行时
在 vLLM Semantic Router 中,looper 是有限范围微代理(bounded micro-agents)的执行运行时。
一个请求以普通的聊天补全形式进入路由器。路由器提取信号,将其投射到任务形状(task-shape)或风险区间中,匹配决策,然后选择一个算法。该算法可以是常规的单模型路径,也可以是 looper 路径。
目前,主要的 looper 模式有:
Confidence(置信度):一个顺序升级循环。它先尝试更便宜的候选模型,测量置信度,仅在得分过低时进行升级。
Ratings(评分):一个有界扇出循环。它在硬并发上限下运行多个候选模型,并使用评分感知权重进行聚合。
ReMoM(重复混合模型推理):扇出广度样本,等待足够多的成功响应,然后进行最终的合成轮次。
Fusion(融合):一种“专家组-裁判-终审”模式。独立的模型响应成为裁判和终审者的证据。
Workflows(工作流):一个微代理工作流运行时。它支持静态角色或动态规划器,执行有界的工作节点步骤,并综合最终响应。
图 2:Looper 算法在路由器内部运行,同时保持模型 API 表面不变。
实现细节至关重要。Looper 不是“多问几个模型”的口号。它是一个带有预算、拓扑结构、追踪和故障策略的轻量运行时。
Confidence: spend escalation only on hard cases
Confidence is the cost-aware loop. It starts with a smaller or cheaper candidate, then evaluates whether the answer is confident enough to stop. The confidence signal can come from token-level log probability, logprob margin, a hybrid score, self-verification, or an AutoMix-style entailment verifier.
If the score passes the threshold, the router returns immediately. If the score is too low, the route escalates to the next candidate. The important part is not that escalation exists. It is that escalation becomes explicit router policy: thresholds, failure behavior, and stopping conditions are visible and tunable.
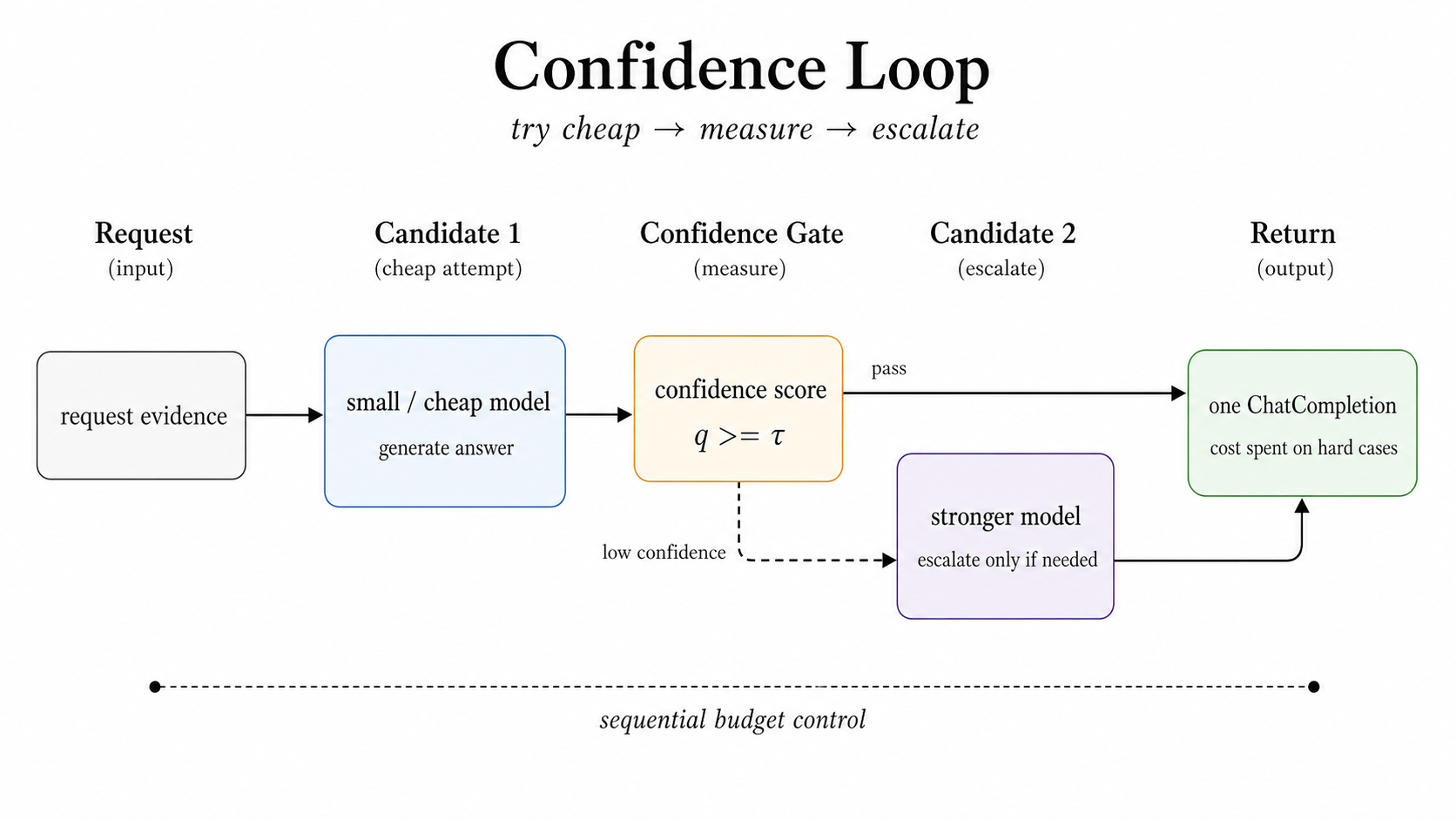
Figure 3: Confidence turns escalation into a measured stopping policy.
Confidence:仅在困难案例上花费升级成本
Confidence 是成本感知的循环。它从一个较小或较便宜的候选模型开始,然后评估答案是否足够确信以至于可以停止。置信度信号可以来自 token 级别的对数概率、对数概率边际、混合分数、自我验证或 AutoMix 风格的蕴含验证器。
如果分数超过阈值,路由器立即返回。如果分数过低,路由升级到下一个候选模型。重要的不是存在升级机制,而是升级变成了明确的路由器策略:阈值、失败行为和停止条件都是可见且可调的。
图 3:Confidence 将升级转变为一种可测量的停止策略。
Ratings: parallel quality under a hard cap
Ratings is the controlled ensemble loop. It launches several candidates in parallel, but only up to a configured max_concurrent cap. That makes it useful when a route should benefit from multiple model views without turning every request into an unbounded fan-out.
The router collects successful responses, applies rating-aware aggregation, and handles failures according to the route policy. In practice, Ratings is a good fit for A/B-style evaluation, ensemble strategies, and routes where the operator already has meaningful per-candidate quality signals.
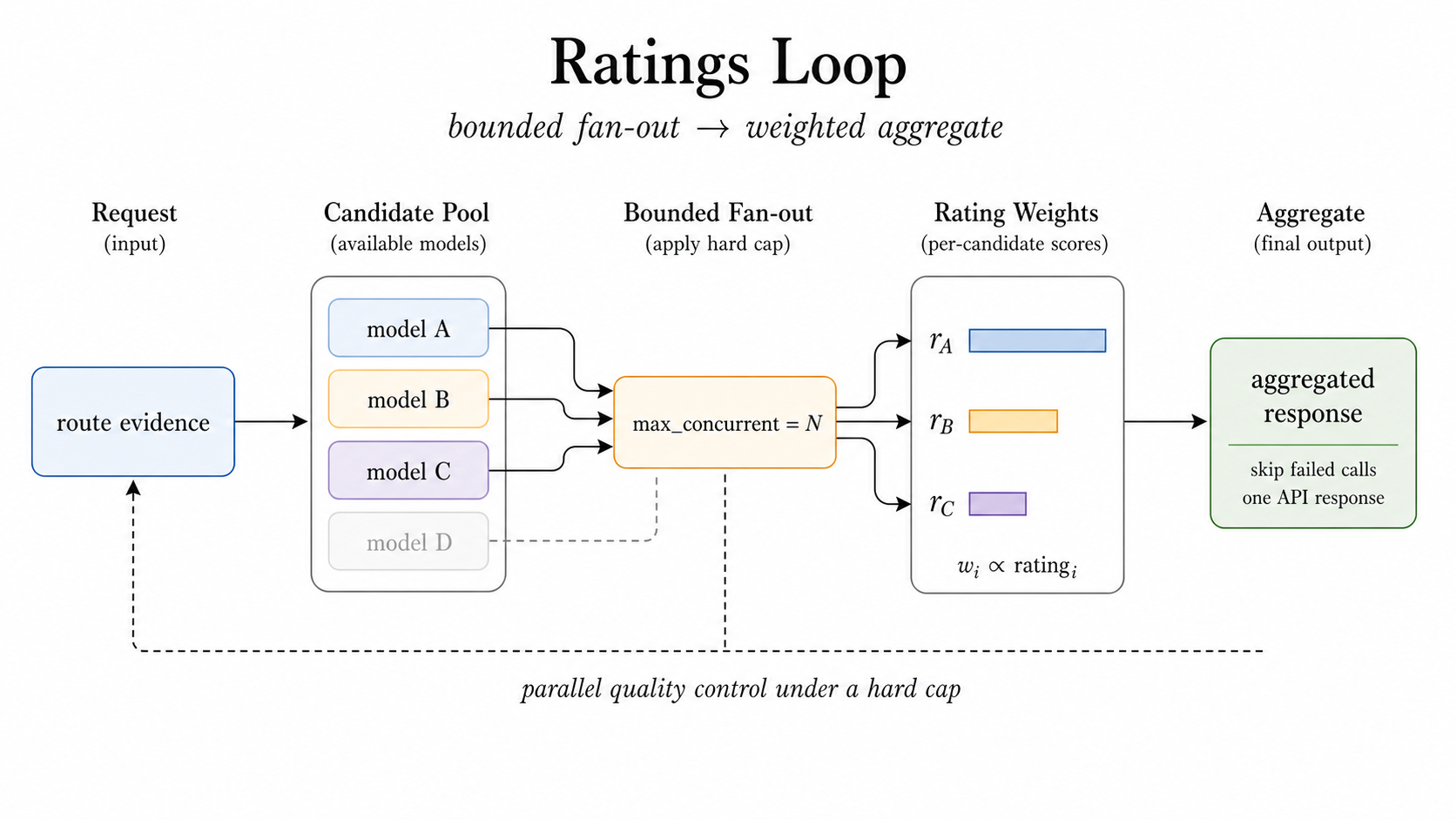
Figure 4: Ratings keeps multi-candidate execution bounded and rating-aware.
Ratings:硬上限下的并行质量评估
Ratings 是受控的集成循环。它并行启动多个候选模型,但受限于配置的 max_concurrent(最大并发数)上限。这使得它在需要从多个模型视角获益,但又不想让每个请求都变成无限制扇出时非常有用。
路由器收集成功的响应,应用评分感知的聚合,并根据路由策略处理失败情况。在实践中,Ratings 非常适合 A/B 风格的评估、集成策略,以及操作者已经拥有有意义的每个候选模型质量信号的路由场景。
图 4:Ratings 保持多候选执行的有界性和评分感知。
ReMoM: breadth with a contract
ReMoM is useful when the task has high reasoning variance and the answer format must survive the collaboration. It fans out multiple reasoning attempts, waits for a minimum-success quorum, then asks a synthesis model to merge evidence into the required output contract.
If synthesis fails but earlier workers produced valid evidence, the route does not have to collapse into an API error. It can fall back to the best valid evidence and still return a normal response.
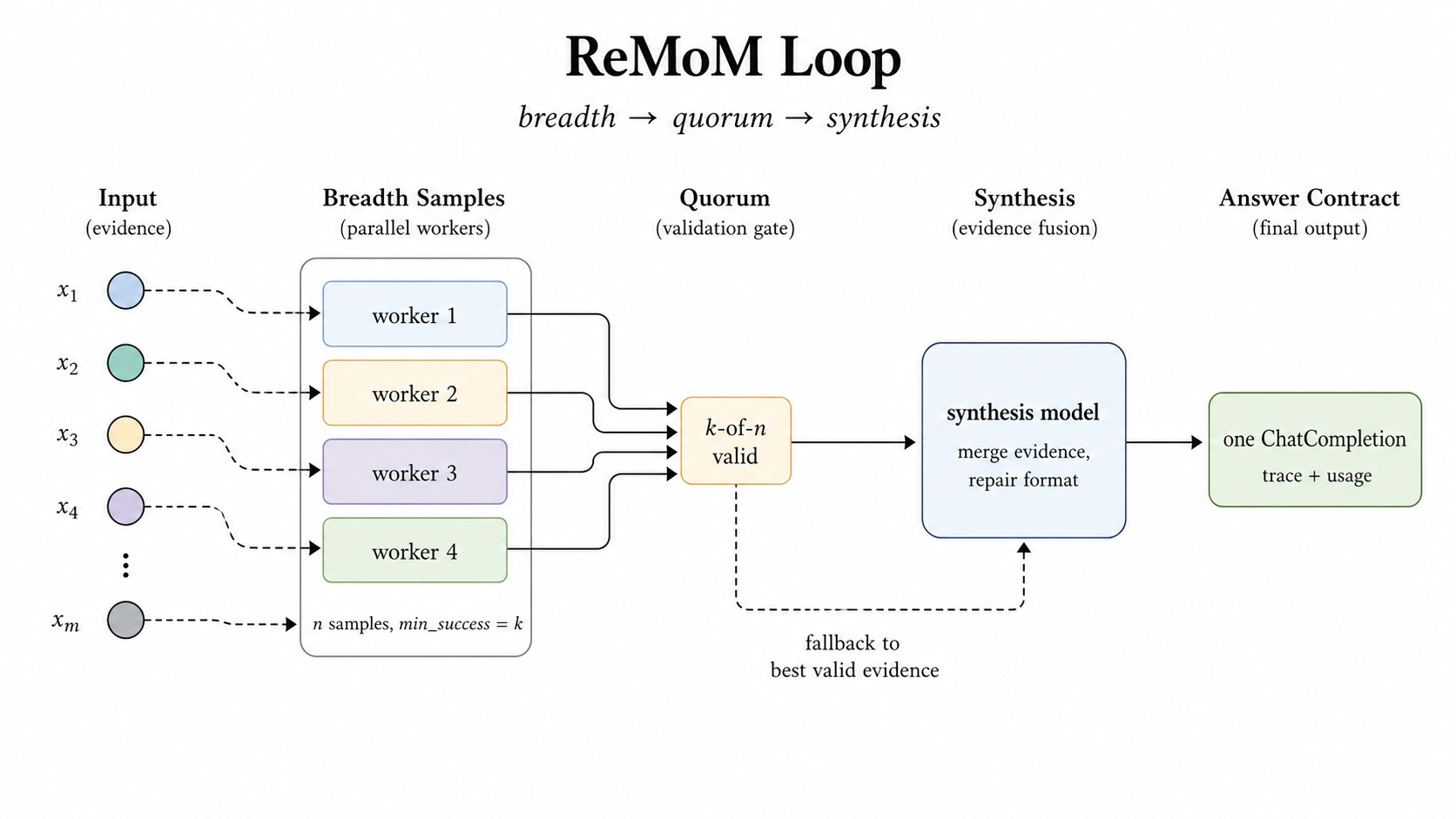
Figure 5: ReMoM treats breadth, quorum, synthesis, and fallback as serving-time controls.
ReMoM:带契约的广度推理
当任务具有很高的推理差异性,且答案格式必须在协作中保持不变时,ReMoM 非常有用。它会扇出多个推理尝试,等待达到最小成功法定人数,然后要求一个合成模型将证据合并到所需的输出契约中。
如果合成失败,但早期的工作节点产生了有效的证据,路由不必崩溃成 API 错误。它可以回退到最佳有效证据,并仍然返回一个正常的响应。
图 5:ReMoM 将广度、法定人数、合成和回退视为服务时间的控制项。
Fusion: disagreement as signal
Fusion starts from a different bet. Sometimes the useful object is not the average answer; it is the structure of disagreement. Independent panel answers become evidence. The judge sees agreement, contradiction, and unique insight, then the finalizer returns one answer with the trace collapsed behind the API.
That makes Fusion especially useful when there are plausible competing paths: hard multiple-choice reasoning, long-form expert judgment, or exact-answer tasks where a single confident response can be brittle.
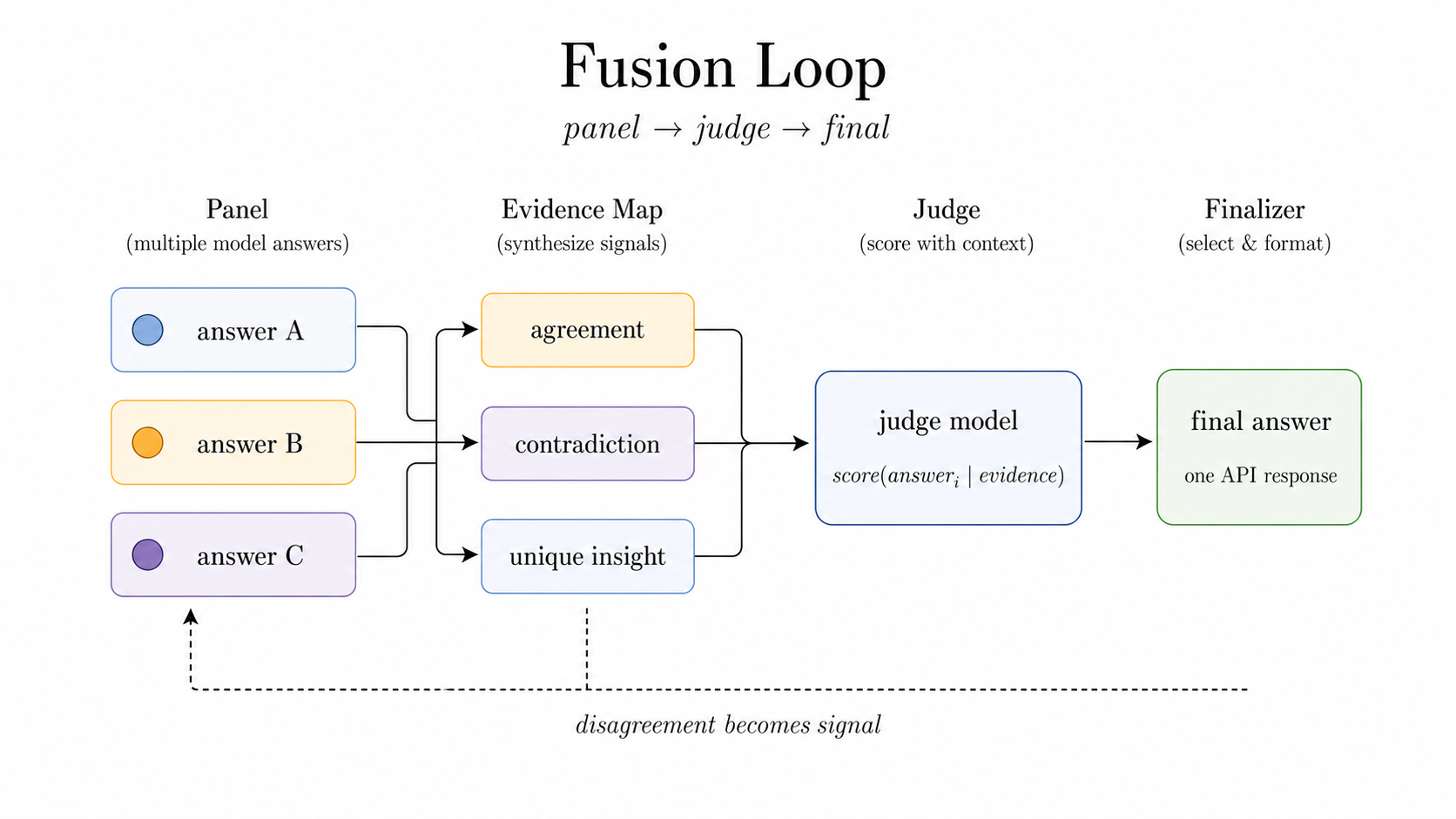
Figure 6: Fusion does not hide disagreement. It turns disagreement into evidence.
Fusion:将分歧转化为信号
Fusion 从一个不同的假设开始。有时有用的不是平均答案,而是分歧的结构。独立的专家组答案成为证据。裁判看到一致、矛盾以及独特的见解,然后终审者返回一个答案,追踪信息被压缩到 API 背后。
这使得 Fusion 在存在合理竞争路径时特别有用:困难的多选推理、长格式专家判断,或单个自信响应可能过于脆弱的精确答案任务。
图 6:Fusion 不隐藏分歧。它将分歧转化为证据。
Workflows: roles under a budget
Workflows is the most agentic pattern, and also the one that needs the strictest boundaries. The planner can only choose allowed worker models. The plan is validated. Steps are bounded by max steps, max parallelism, timeouts, and error policy. The final response still has to satisfy the output contract.
For SWE-style tasks, that means the router can express a planner, patcher, verifier, and finalizer without letting the application own a bespoke agent stack. For production serving, that distinction is critical: the loop is powerful, but it is still governed by infrastructure.
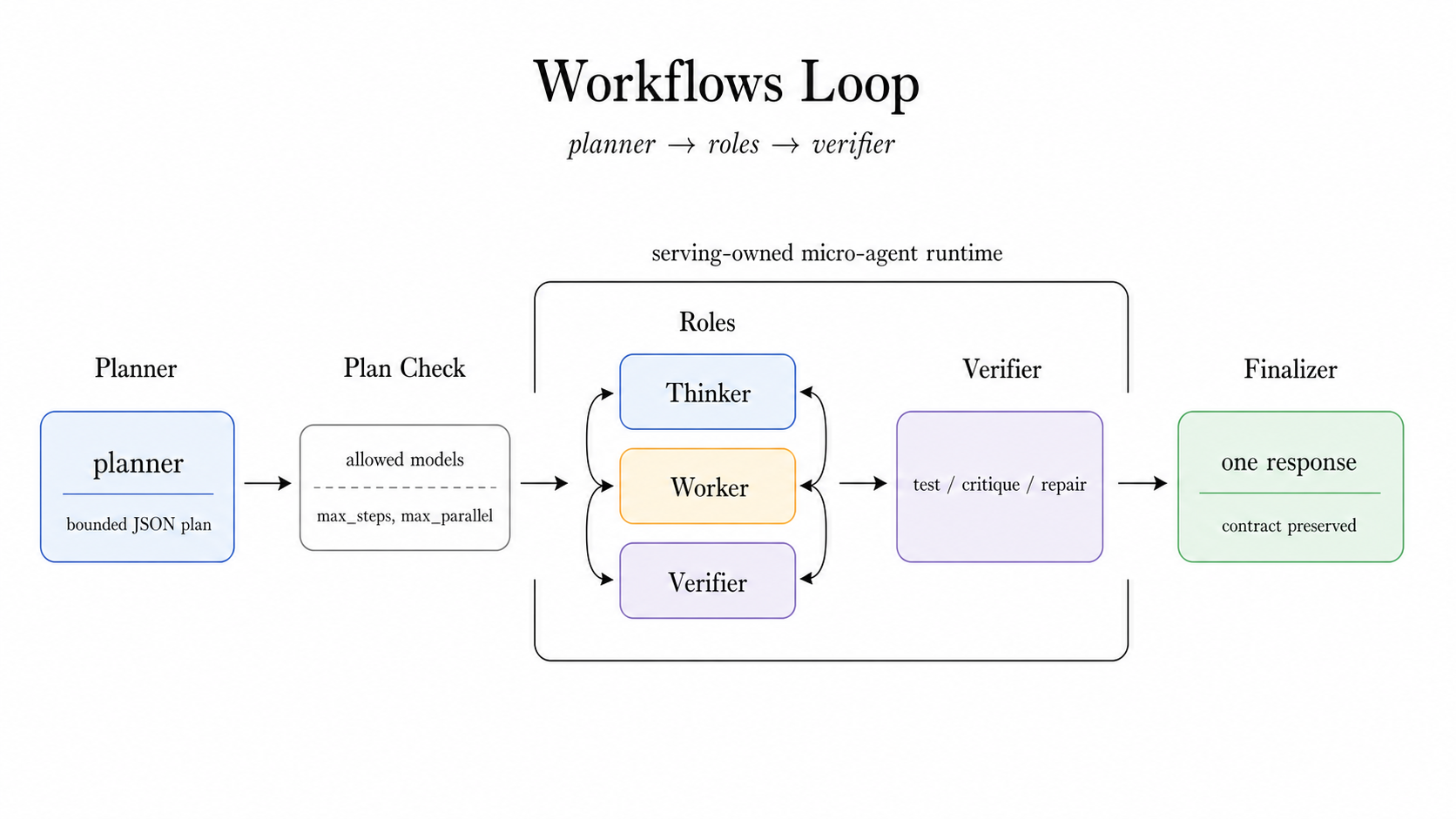
Figure 7: Workflows gives the router a bounded role system, not an unbounded autonomous agent.
Workflows:预算内的角色系统
Workflows 是最具 agent 性的模式,也是需要最严格边界约束的模式。规划器只能选择允许的工作节点模型。计划会被验证。步骤受限于最大步骤数、最大并行度、超时和错误策略。最终响应仍需满足输出契约。
对于 SWE 风格的任务,这意味着路由器可以表达规划器、修补器、验证器和终审者,而无需让应用拥有一个定制的 agent 栈。对于生产服务来说,这种区别至关重要:循环虽然强大,但仍受基础设施的管控。
图 7:Workflows 赋予了路由器一个有界的角色系统,而非无界的自主 Agent。
Auto recipes: one model name, many loops
The public surface remains one model name: vllm-sr/auto. Internally, the router can use signals and projections to choose the right loop for the request. Difficulty, risk, contract pressure, latency, and cost are not comments in a prompt. They are routing facts that can select Confidence, Ratings, ReMoM, Fusion, Workflows, or a fallback path.
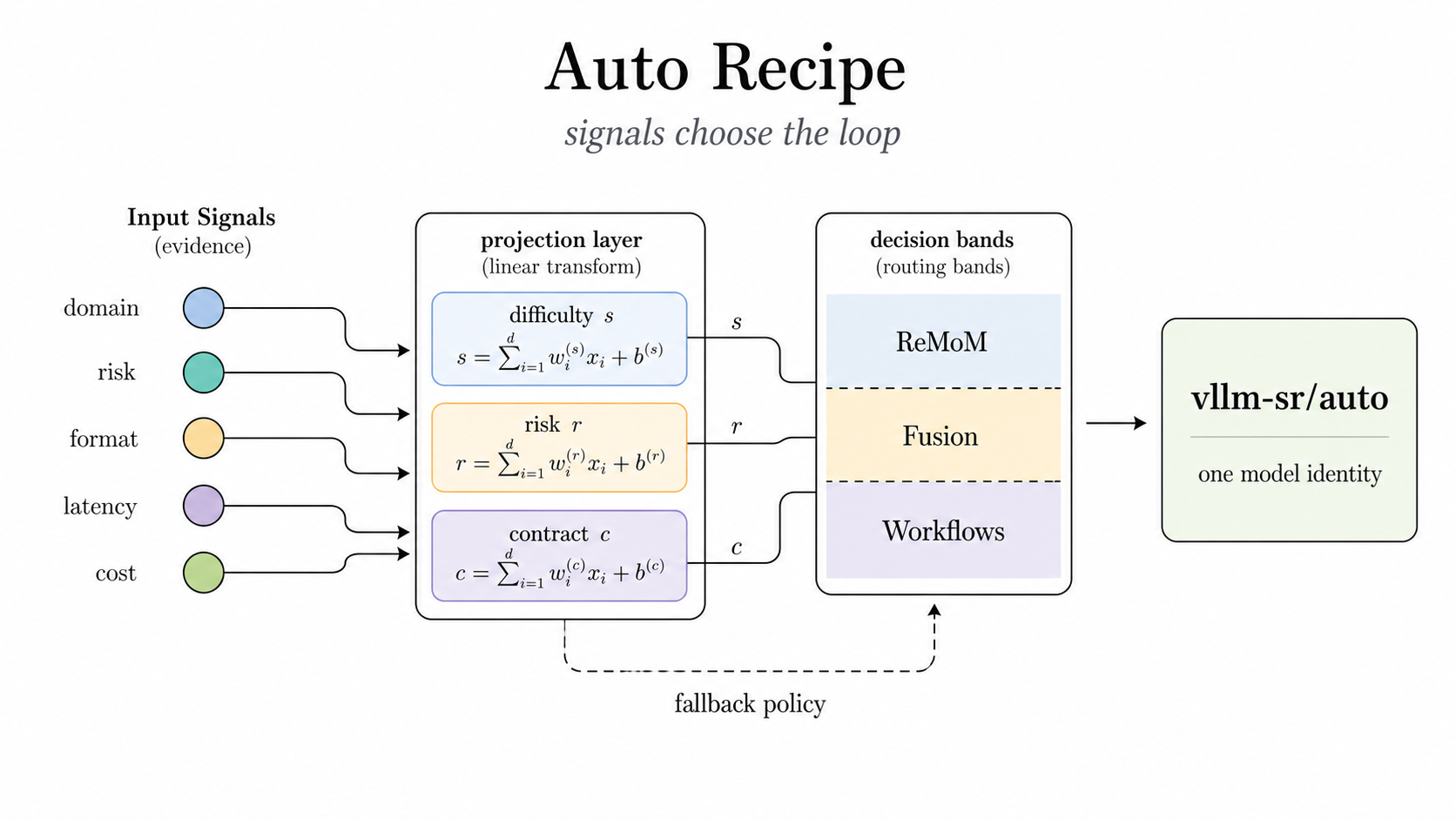
Figure 8: Auto recipes let signals choose the collaboration pattern while preserving one model identity.
This is the difference between "agent as app logic" and "micro-agent as serving runtime." The router controls the budget, policy, topology, trace, and failure mode.
Auto Recipes:一个模型名,多种循环
对外暴露的仍然是一个模型名称:vllm-sr/auto。在内部,路由器可以使用信号和投影为请求选择合适的循环。难度、风险、契约压力、延迟和成本不是提示词中的注释。它们是路由事实,可以选择 Confidence、Ratings、ReMoM、Fusion、Workflows 或回退路径。
图 8:Auto recipes 允许信号选择协作模式,同时保持一个模型身份。
这就是“Agent 作为应用逻辑”与“微代理作为服务运行时”的区别。路由器控制着预算、策略、拓扑、追踪和故障模式。
Recipes Beat One Universal Loop
The most important lesson from our eval work is not that one algorithm always wins.
It is the opposite:
The best loop is task-shaped.
GPQA-Diamond wants strict multiple-choice answer preservation. LiveCodeBench wants runnable code and hidden-test robustness. Humanity's Last Exam wants disagreement resolution and exact-answer formatting. SWE-style tasks need a planner, patcher, verifier, and finalizer.
That is why vllm-sr/auto should not mean "always run the biggest loop." It should mean: select the recipe that fits this task.
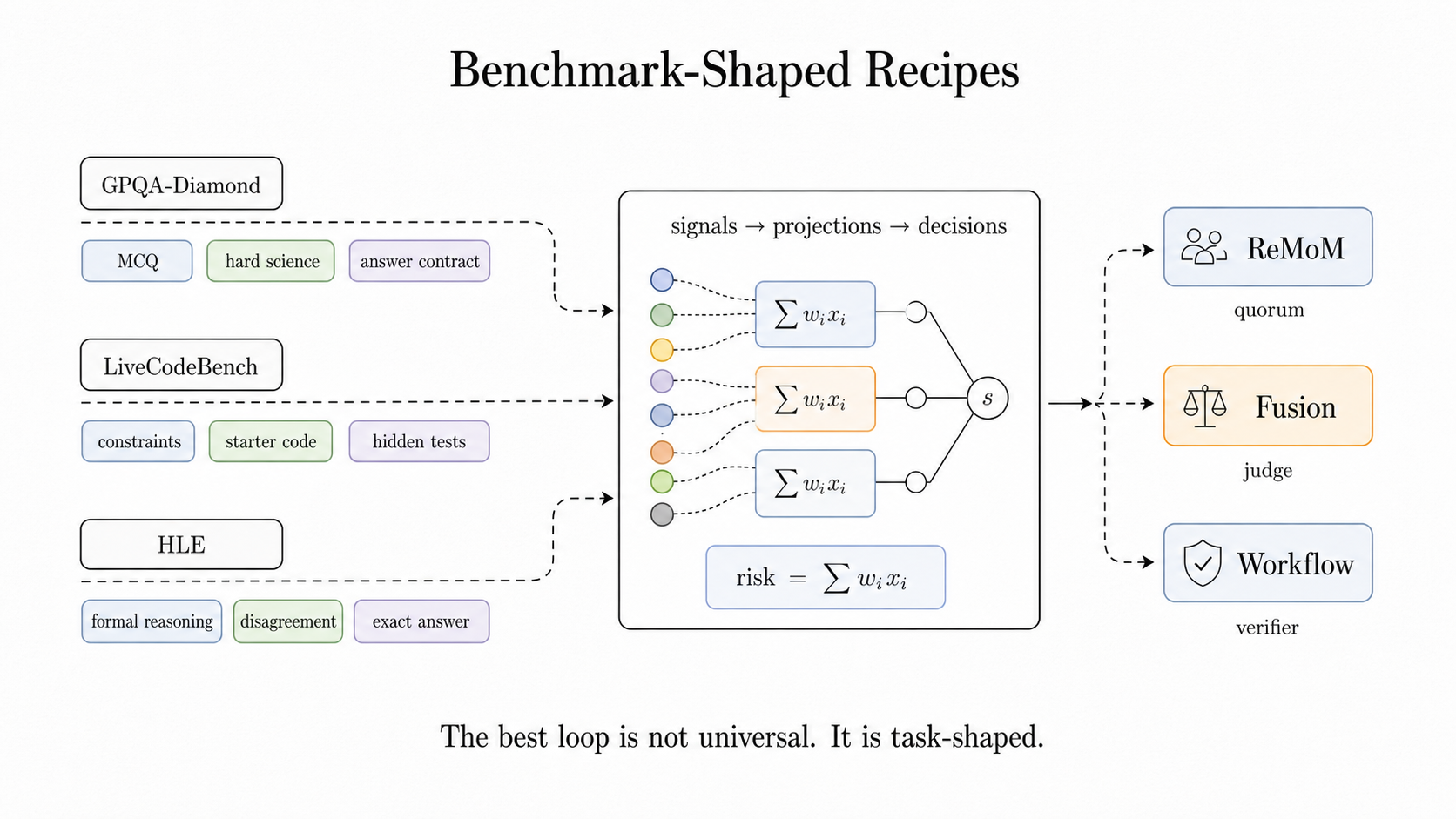
Figure 9: Signals and projections let the router choose a benchmark-shaped collaboration pattern.
最佳循环是与任务匹配的
从我们的评估工作中得到的最重要教训,并不是某个算法总是胜出。
恰恰相反:
最佳的循环是与任务形状相匹配的。
GPQA-Diamond 要求严格保持多项选择题的答案格式。LiveCodeBench 要求可运行代码和隐藏测试的鲁棒性。Humanity's Last Exam 需要解决分歧并格式化精确答案。SWE 风格的任务则需要规划器、修补器、验证器和终审者。
这就是 vllm-sr/auto 不应该意味着“总是运行最大的循环”的原因。它的意思应该是:选择适合此任务的配方。
图 9:信号和投影让路由器选择与基准测试形状匹配的协作模式。
In our recipes, that shape is explicit:
GPQA-Diamond routes hard science multiple-choice prompts into a ReMoM recipe with strict ANSWER: X preservation.
LiveCodeBench looks for constraints, starter code, standard input, float tolerance, timeout risk, and hidden-test risk before selecting a code-shaped loop.
HLE detects formal reasoning, disagreement risk, long context, and exact answer pressure before choosing between deeper ReMoM, smaller Fusion, or a fallback path.
This is why router-side collaboration is more than prompt engineering. The prompt is only one part. The recipe also defines model pool, model roles, reasoning effort, concurrency, quorum, timeout, synthesis model, fallback policy, output contract, and observability labels.
在我们的配方中,这种形状是明确的:
GPQA-Diamond 将困难的科学多选题提示路由到 ReMoM 配方,并严格保留“ANSWER: X”格式。
LiveCodeBench 在选择适合代码的循环之前,会检查约束条件、起始代码、标准输入、浮点数容差、超时风险和隐藏测试风险。
HLE 会检测形式化推理、分歧风险、长上下文和精确答案压力,然后在更深的 ReMoM、较小的 Fusion 或回退路径之间进行选择。
这就是为什么路由器侧的协作不仅仅是提示工程。提示只是其中的一部分。配方还定义了模型池、模型角色、推理努力程度、并发数、法定人数、超时、合成模型、回退策略、输出契约和可观测性标签。
The Scorecard Is a Proof, Not the Whole Story
We evaluated the current closed-model recipe across three hard benchmarks. The numbers are useful because they show that the idea is not only aesthetic.
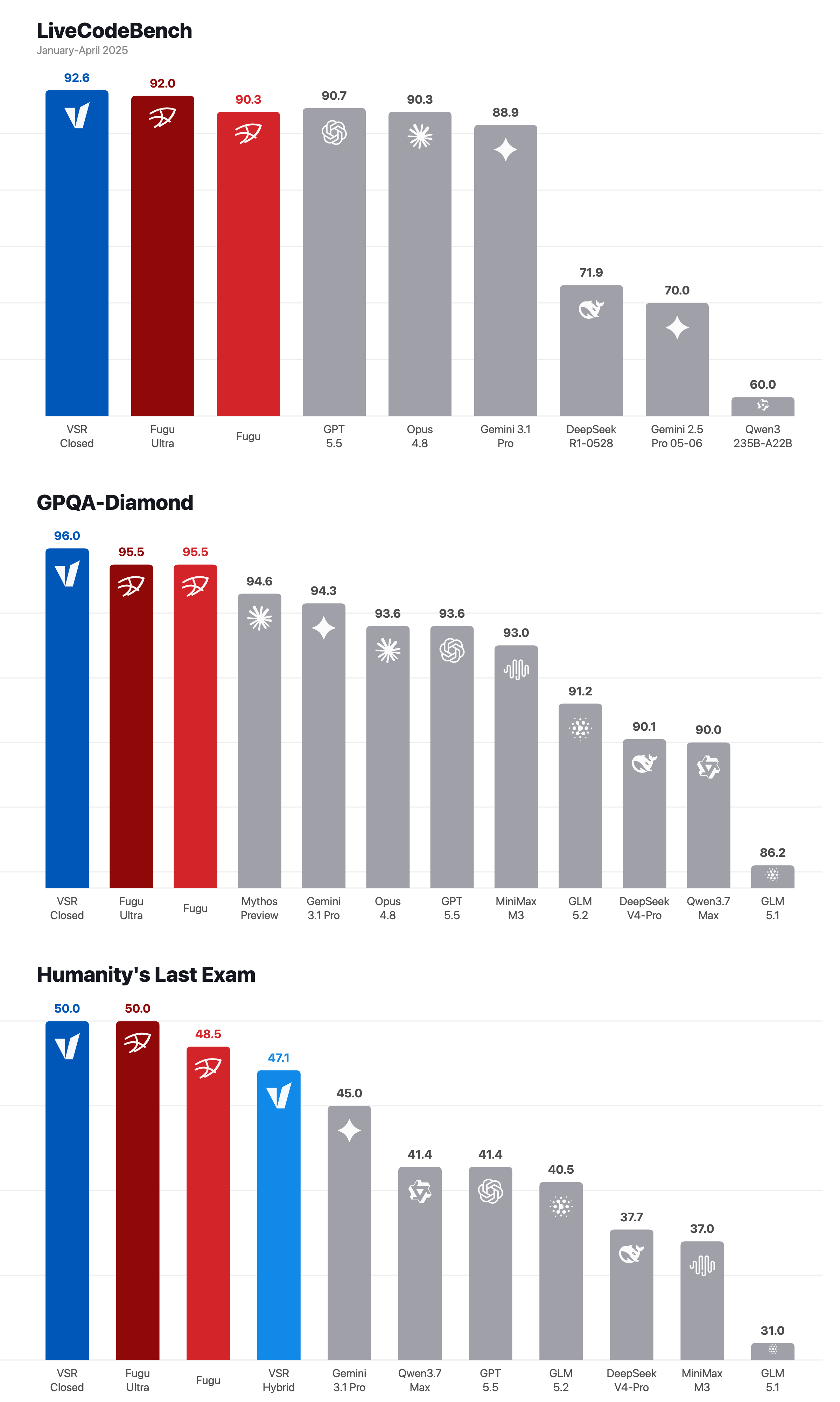
Figure 10: VSR Closed and VSR Hybrid scorecard view across LiveCodeBench, GPQA-Diamond, and Humanity's Last Exam.
In this scorecard, VSR Closed means the recipe uses only closed-model backends. VSR Hybrid means the recipe mixes open and closed models, using the stronger closed models where the recipe needs higher-risk judging, repair, synthesis, or fallback.
| Benchmark | VSR scorecard row | Score | Reference rows |
|---|---|---|---|
| LiveCodeBench, January-April 2025 | VSR Closed | 92.6 | Fugu Ultra 92.0, Fugu 90.3, GPT-5.5 90.7, Opus 4.8 90.3 |
| GPQA-Diamond | VSR Closed | 96.0 | Fugu Ultra 95.5, Fugu 95.5, Gemini 3.1 Pro 94.3, GPT-5.5 93.6 |
| Humanity's Last Exam | VSR Closed | 50.0 | Fugu Ultra 50.0, Fugu 48.5, Gemini 3.1 Pro 45.0 |
| Humanity's Last Exam | VSR Hybrid | 47.1 | GLM-5.2 40.5, Qwen3.7 Max 41.4, GPT-5.5 41.4 |
The scorecard should be read carefully. It is not a claim that every request should always use every closed model. That would be the wrong product.
The claim is that router-owned collaboration can create a stronger model identity than the individual calls beneath it. It can beat or match frontier single-model baselines while preserving one API surface.
That is the real product shape:
Users see one model name.
Operators control the recipe.
The system can improve without changing the client integration.
Open and closed models can participate under the same serving abstraction.
记分卡是证明,而非完整故事
我们跨三个困难基准测试评估了当前的闭源模型配方。这些数字很有用,因为它们表明这个想法不仅仅是美学上的。
图 10:VSR Closed 和 VSR Hybrid 在 LiveCodeBench、GPQA-Diamond 和 Humanity's Last Exam 上的记分卡视图。
在此记分卡中,VSR Closed 表示配方仅使用闭源模型后端。VSR Hybrid 表示配方混合使用开源和闭源模型,在配方需要更高风险的评判、修复、合成或回退时使用更强的闭源模型。
| 基准测试 | VSR 记分卡行 | 分数 | 参考行 |
|---|---|---|---|
| LiveCodeBench, 2025 年 1 月-4 月 | VSR Closed | 92.6 | Fugu Ultra 92.0, Fugu 90.3, GPT-5.5 90.7, Opus 4.8 90.3 |
| GPQA-Diamond | VSR Closed | 96.0 | Fugu Ultra 95.5, Fugu 95.5, Gemini 3.1 Pro 94.3, GPT-5.5 93.6 |
| Humanity's Last Exam | VSR Closed | 50.0 | Fugu Ultra 50.0, Fugu 48.5, Gemini 3.1 Pro 45.0 |
| Humanity's Last Exam | VSR Hybrid | 47.1 | GLM-5.2 40.5, Qwen3.7 Max 41.4, GPT-5.5 41.4 |
应该仔细阅读这张记分卡。它并非声称每个请求都应该始终使用所有闭源模型。那将是错误的产品。
其主张是:路由器拥有的协作可以创造出比其底层单个调用更强大的模型身份。它能够超越或匹配前沿单模型基准,同时保持一个 API 表面。
这才是真正的产品形态:
用户看到一个模型名称。
操作者控制配方。
系统可以在不改变客户端集成的情况下进行改进。
开源和闭源模型可以在同一个服务抽象下参与。
What This Means for Model Serving
The old serving stack was passive. It accepted a model name and sent the request to a backend.
The next serving stack is active. It asks:
What evidence do we have about this request?
What quality, cost, latency, and safety band does it fall into?
Is one model enough?
If not, what collaboration pattern should run?
Which answer contract must be preserved?
What should happen if one provider is slow or wrong?
How do we expose one clean response while keeping the full trace?
That is not application glue. That is infrastructure.
Micro-agents belong in the router because the router already owns the things micro-agents need: model aliases, provider policy, credentials, cost metadata, signals, decisions, retries, timeouts, traces, and OpenAI-compatible response semantics.
这对模型服务意味着什么
旧的服务栈是被动的。它接受一个模型名称,然后将请求发送到后端。
下一代服务栈是主动的。它会问:
关于这个请求,我们有什么证据?
它属于哪个质量、成本、延迟和安全区间?
一个模型够用吗?
如果不够,应该运行哪种协作模式?
必须保留哪个答案契约?
如果某个提供商很慢或出错,应该怎么办?
我们如何在不丢失完整追踪的情况下,暴露一个整洁的响应?
这不是应用胶水代码。这是基础设施。
微代理应该属于路由器,因为路由器已经拥有了微代理所需的一切:模型别名、提供商策略、凭证、成本元数据、信号、决策、重试、超时、追踪和兼容 OpenAI 的响应语义。
The Takeaway
The word "frontier model" is starting to mean two things.
One is a checkpoint.
The other is a system boundary.
The recent orchestration wave made the direction visible. vLLM Semantic Router is the bet that this capability should be programmable, observable, and open at the serving layer.
The next model race will still involve better models. But it will also involve better routers: routers that know when to save money, when to enforce safety, when to stay on the edge, when to go to the cloud, and when to turn one request into a small, disciplined team.
That is the promise of micro-agents inside the Model API.
要旨
“前沿模型”这个词开始有两层含义。
一层是一个检查点(checkpoint)。
另一层是一个系统边界。
最近的编排浪潮让这个方向变得可见。vLLM Semantic Router 押注于这种能力在服务层应该是可编程、可观察且开放的。
下一轮模型竞赛仍然会涉及更好的模型。但它也会涉及更好的路由器:那些知道何时省钱、何时执行安全策略、何时留在边缘、何时上云,以及何时将一个请求转化为一个有纪律的小团队的路由器。
这就是微代理在模型 API 内部的承诺。
Acknowledgements
We thank researchers from MBZUAI, McGill University, Mila, and Agentic Intelligence Lab, especially Prof. Xue Liu and Dr. Bowei He, for research collaboration and discussions around router-side model collaboration.
Individual Contributors: Huamin Chen, Yincheng Ren.
We also thank AMD's Andy Luo and Haichen Zhang for AMD GPU evaluation support.
致谢
我们感谢来自 MBZUAI、麦吉尔大学、Mila 和 Agentic Intelligence Lab 的研究人员,特别是 Xue Liu 教授和 Bowei He 博士,感谢他们在路由器端模型协作方面的研究合作与讨论。
个人贡献者:Huamin Chen、Yincheng Ren。
我们还感谢 AMD 的 Andy Luo 和 Haichen Zhang 在 AMD GPU 评估方面提供的支持。