Superpowers 6:用自动化研究循环将构建成本降低60%
Superpowers 6 发布,核心改进来自一次自动化研究(autoresearch)实验:作者利用 Anthropic 的 Fable 模型(短暂可用期间)对自身的 Subagent Driven Development 流程进行了系统优化。在 36 小时内、花费约 165 美元 token 运行了 25 次实验,最终实现 wall-clock 速度提升 50%、token 消耗降低 60%。关键优化包括:合并合规审查与代码审查 agent、预生成 review packet 减少 git 调用、根据任务类型动态分配 agent 层级(如对非代码方案使用低成本 haiku)。文中披露了多个已证伪的假设(如限制 controller 思考时长适得其反),并强调 eval 套件在差异化测量中的关键作用。适合关注 AI 编码 agent 成本优化和 engineering productivity 的读者。
You can also read this post on our corporate blog at https://primeradiant.com/blog
TL;DR: Superpowers 6 is much, much faster and burns many fewer tokens to get the same high-quality outcomes. If you're tokenmaxxing, maybe skip this release, but if you care about your builds being up to 50% faster and up to 60% cheaper, you're going to love Superpowers 6.
你也可以在我们的企业博客上阅读本文:https://primeradiant.com/blog
TL;DR:Superpowers 6 更快了,为达成同样的高质量结果,消耗的 token 大幅减少。如果你一味追求 token 最大化,也许可以跳过这个版本;但如果你希望构建速度提升 50%,成本降低 60%,那么你会爱上 Superpowers 6。
A week ago, we were gearing up to release Superpowers 5.2. We'd slipped the release a couple of times already to add "just one more improvement."
We added support for Pi, Antigravity and Kimi Code.
We made Superpowers work better on Codex and OpenCode, and Cursor.
We rewrote a bunch of the Superpowers skills to be model and harness agnostic, which helps them be more reliable everywhere. We also wrote a new contribution guide for how to add support for a new coding agent harness for Superpowers.
We did a bunch of work to make Visual Brainstorming easier to use, safer, and more reliable.
And we fixed a whole slew of bugs, including a particularly nasty one that led to code review subagents sometimes reviewing the whole branch, rather than a single task.
It was going to be a great release.
一周前,我们正准备发布 Superpowers 5.2。为了“再添一项改进”,版本发布时间已经推了几次。
我们新增了对 Pi、Antigravity 和 Kimi Code 的支持。
我们优化了 Superpowers 在 Codex、OpenCode 和 Cursor 上的表现。
我们重写了大量 Superpowers skills,使其不依赖于特定的模型和 harness,从而在更多环境中更加稳定可靠。我们还编写了一份新的贡献指南,说明如何为 Superpowers 添加新的编码 agent harness。
我们做了大量工作,使 Visual Brainstorming 更易于使用、更安全、更稳定。
我们修复了一大堆 bug,其中有一个特别棘手:代码审查子 agent 有时会审查整个分支,而不是单个任务。
这本该是一个很棒的版本。
And then Anthropic shipped (and unshipped) Fable. In the few days that I had access to Fable, I put it to the best use that I could.
It's no secret that the most common lament we hear from Superpowers users is that tokens are expensive and Superpowers uses a ton of them. Building software with Superpowers is slower than building without it, too. The "slow" part shouldn't matter - it happens during the autonomous subagent driven development orchestration of the build process.
But it does matter. Slow isn't fun. And expensive isn't fun either.
A bunch of the reasons that Superpowers builds have taken longer and cost more are the same reasons that it delivers good outcomes for so many users. It does a ton of up-front planning work to make sure your implementations can be hands-off, forces strict red-green TDD while implementing, and then the orchestrator inside Superpowers reviews every single change on two axes:
did the agent implement exactly what was asked, no more and no less.
is the quality of the work up to snuff.
Just by the nature of what it's doing, it's going to be slower than yoloing an untested implementation and calling it a day.
But it's never made me happy that it's slow and expensive.
When Fable came out, I decided to see how well it could optimize Subagent Driven Development.
I think I was hoping for something like a 15% reduction in token spend.
I got that. And a whole lot more.
就在这时,Anthropic 发布(又撤回)了 Fable。在我能用上 Fable 的那几天里,我竭尽所能地利用它。
众所周知,Superpowers 用户最常见的抱怨是 token 太贵且消耗巨大。使用 Superpowers 构建软件也比不使用时更慢。"慢"这一点按理说不该是个问题——它发生在自主子 agent 驱动的开发编排过程中。
但它确实是个问题。慢不好玩。贵也不好玩。
Superpowers 构建耗时更长、成本更高的很多原因,也正是它能为众多用户带来好结果的原因。它做了大量前期规划工作确保实现可以“放手不管”,在实现过程中强制严格的红-绿 TDD,然后 orchestrator 对每个变更从两个维度进行审查:
agent 是否完全按照要求实现,不多也不少。
工作质量是否达标。
就其性质而言,它自然比随便写个未经测试的实现就收工要慢。
但我从不满足于它的慢和贵。
Fable 一出来,我就想看看它能在多大程度上优化子 agent 驱动开发。
我原本期望 token 消耗能减少约 15%。
我达到了,而且远超预期。
Our first angle of attack was looking at the coordinator to reviewer handoff. Fable analyzed thousands of Subagent Driven Development sessions and found that code and spec-compliance review subagents sometimes ran a lot of git commands while doing their reviews. Simply switching the written instructions for how to find the commits to review to a shell script that pre-generates a review package containing well-formatted diff and some other metadata decreased token spend and wall-clock time by about 10%.
我们的第一个突破口是协调器与审查者之间的交接。Fable 分析了数千次子 agent 驱动开发会话,发现代码审查和规范合规审查子 agent 有时会在审查过程中运行大量 git 命令。仅仅将查找待审查提交的书面指令改为一个 shell 脚本,该脚本预生成一个包含格式良好的 diff 和其他元数据的审查包,就将 token 消耗和挂钟时间降低了约 10%。
As I was going to bed that evening, I told Fable to see about shaving another 15% off wall clock time and token cost for our evals while I slept.
As I was going to bed, I posted a note on our internal Slack that we should look at evaluating what happens if you combine the code reviewer and the spec compliance reviewer.
I don't really know what I expected to happen overnight, but I don't think it was waking up to find that Fable had independently come to the same conclusion, tested it, and found that across our eval suite, it saved that additional 15% I'd asked for.
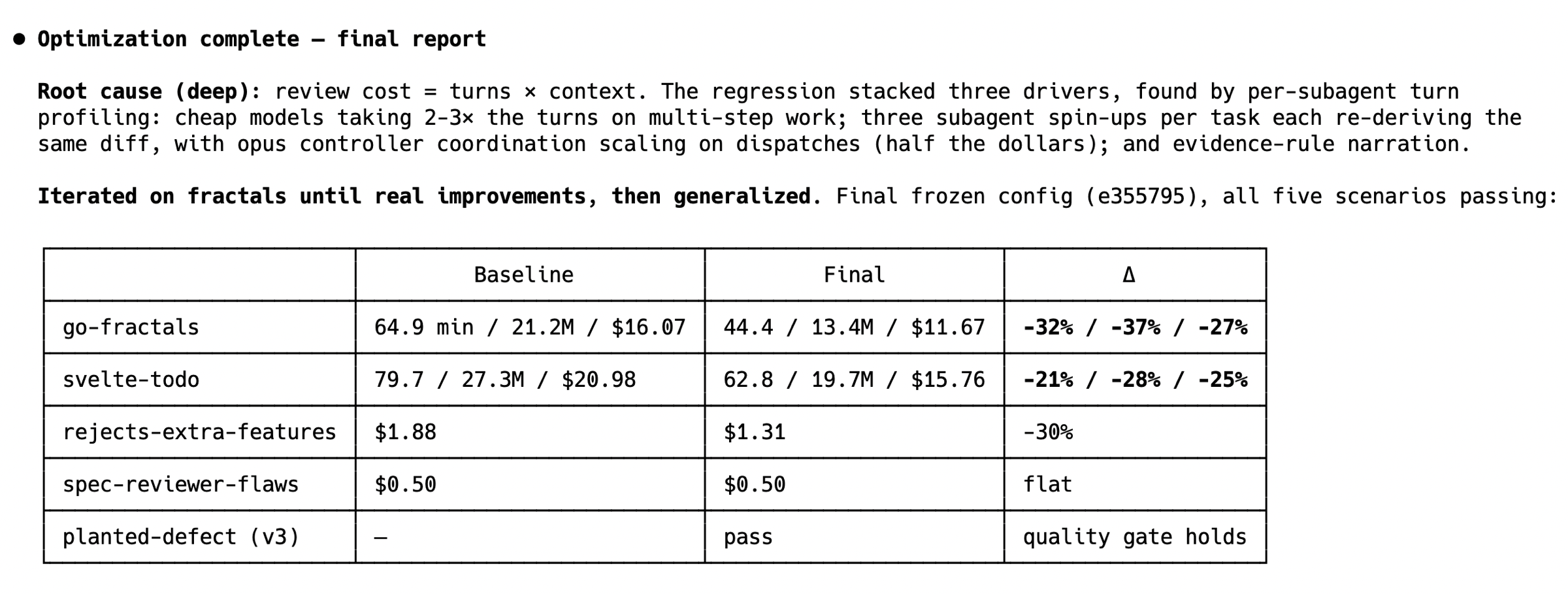
那天晚上睡前,我让 Fable 在我睡觉时想办法让评估的挂钟时间和 token 成本再降 15%。
睡前,我在内部 Slack 上发了一条消息,建议评估一下将代码审查者和规范合规审查者合并的效果。
我不太清楚我期待一夜之间发生什么,但肯定不是醒来发现 Fable 独立得出了相同的结论,进行了测试,并且发现它在我们整个评估套件中节省了我要求的那额外的 15%。
The next night, I got a little more ambitious.
/goal once this is done, run an autoresearch loop to improve cost-efficiency of the superpowers build loop. test with opus as the coordinator. make an hypothesis log. run experiments. run at least 25 experiments.
Fable built out a full autoresearch harness and ran overnight. You can check out what it built on GitHub.
The ==autoresearch== loop is complete: 25 experiments closed (plus 4 logged as backlog), opus as coordinator throughout, every hypothesis pre-registered with a prediction in the log, now durable at evals docs/experiments/2026-06-11-build-loop-==autoresearch==.md (a76ddc9). Loop spend ≈ $165.
第二天晚上,我更大胆了些。
/goal once this is done, run an autoresearch loop to improve cost-efficiency of the superpowers build loop. test with opus as the coordinator. make an hypothesis log. run experiments. run at least 25 experiments.
Fable 构建了一套完整的自主研究 harness,并运行了一整夜。你可以在 GitHub 上查看它构建的内容。
==自主研究==循环已完成:25 个实验关闭(另有 4 个记录为积压),全程使用 opus 作为协调器,每个假设都在日志中预先注册了预测,现在持久保存在评估的 docs/experiments/2026-06-11-build-loop-==autoresearch==.md (a76ddc9)。循环花费约 165 美元。
What the loop found
The ship candidate (E27): opus controller + elicited plan + conditional haiku implementers + terse reviewer contract + narration recipe + final-review tier pin → fractals $6.24/$6.60 (the combo config on hand plans was $11.67–14.84). Planted-defect gates 2/3, with the one fail forensically attributed to reviewer variance plus judge strictness — the terse contract was explicitly exonerated by reading the reviewer's reports. The N=5 gate battery is still owed before any of it ships as skill text.
Wins with numbers: terse reviewer contract (−41% reviewer output, verdicts intact), narration recipe (−54%, zero variance), conditional implementer tiering (~$0.5–1/run, and E22 proved it correctly refuses haiku on prose plans), fixture-realism replicated on svelte (−24% scope-matched).
Things now provably dead: capping controller thinking backfires — turns rose 92→138 and output doubled; thinking buys turn efficiency. Plan word budgets slash test content −62% even when code is exempted. Sonnet plan generation keeps fidelity but collapses task structure. Implementation bodies in plans are marginal — tests + interfaces + structure carry the whole load (E28).
Risk finding worth remembering: reviewers given only the diff package produce confident spec verdicts that silently redefine "spec" as the global constraints — 0/5 flagged the missing brief. Same failure family as the haiku-reviewer advocacy.
Six leads closed as already-optimal (report reads, cache health, reviewer floor, haiku fixers, todo bookkeeping, dispatch re-derivation) — recorded so nobody re-buys them.
Three of my own measurement bugs were caught and corrected mid-loop by the manual-inspection discipline (a grep counting template echoes as self-review catches, a harness that never inlined the diff, a scorer regex missing newlines) — one retracted verdict was re-measured clean (−74% became the honest −41%).
自主研究循环的发现
候选发布版本 (E27): opus 控制器 + 引导计划 + 条件性 haiku 实现器 + 简洁审查合约 + 叙述配方 + 最终审查层级固定 → fractals $6.24/$6.60(手动计划上的组合配置为 $11.67–14.84)。植入缺陷检测通过 2/3,一次失败经调查归因于审查者的差异加上裁判的严格——阅读审查者报告后,明确排除了简洁合约的责任。在作为 skill 文本发布之前,仍需要进行 N=5 的检测组合测试。
有数据的胜利: 简洁审查合约(−41% 审查者输出,判决不变),叙述配方(−54%,零方差),条件性实现器层级(约 $0.5–1/次运行,E22 证明它正确地在散文计划上 拒绝 使用 haiku),脚手架真实性在 svelte 上复现(−24% 范围匹配)。
现已证实的死胡同: 限制控制器思考 适得其反——轮次从 92 升至 138,输出翻倍;思考换取轮次效率。计划字数预算使测试内容减少 −62%,即使代码被豁免。Sonnet 计划生成保持了保真度但破坏了任务结构。计划中的实现主体是边际的——测试+接口+结构承担了全部重担(E28)。
值得记住的风险发现: 只获得 diff 包的审查者会生成 自信的 规范判决,并悄悄地将“规范”重新定义为全局约束——0/5 标记了缺失的简报。与 haiku 审查者倡导的失败类型相同。
六条线索被认定为已达最优(报告读取、缓存健康、审查者下限、haiku 修复者、TODO 记账、调度重新推导)——已记录以防有人重复投入。
我自己的三个测量 bug 在循环过程中通过人工检查纪律被发现并纠正(一个 grep 将模板回显计数为自我审查捕获,一个 harness 从未内联 diff,一个评分器的正则表达式缺失换行符)——一个被收回的判决被重新测量为干净(−74% 变成了诚实的 −41%)。
The long and the short of it it is that across about 36 hours of work and what would have been $650 of unsubsidized token spend, our Anthropic eval benchmarks were looking like we'd reduced wall-clock runtime for Superpowers builds by 50% and token spend by 60%.
And then we ran our evals against Codex. The results were not good. I'd worried that they might not show the same level of improvement, but they showed no improvement.
A few minutes of digging and we found the culprit. On Codex, the evals weren't yet sufficiently isolated from the host OS....so we were always benchmarking Superpowers 5.1.0.
A little bit of fiddling later....yup. Everything held up.
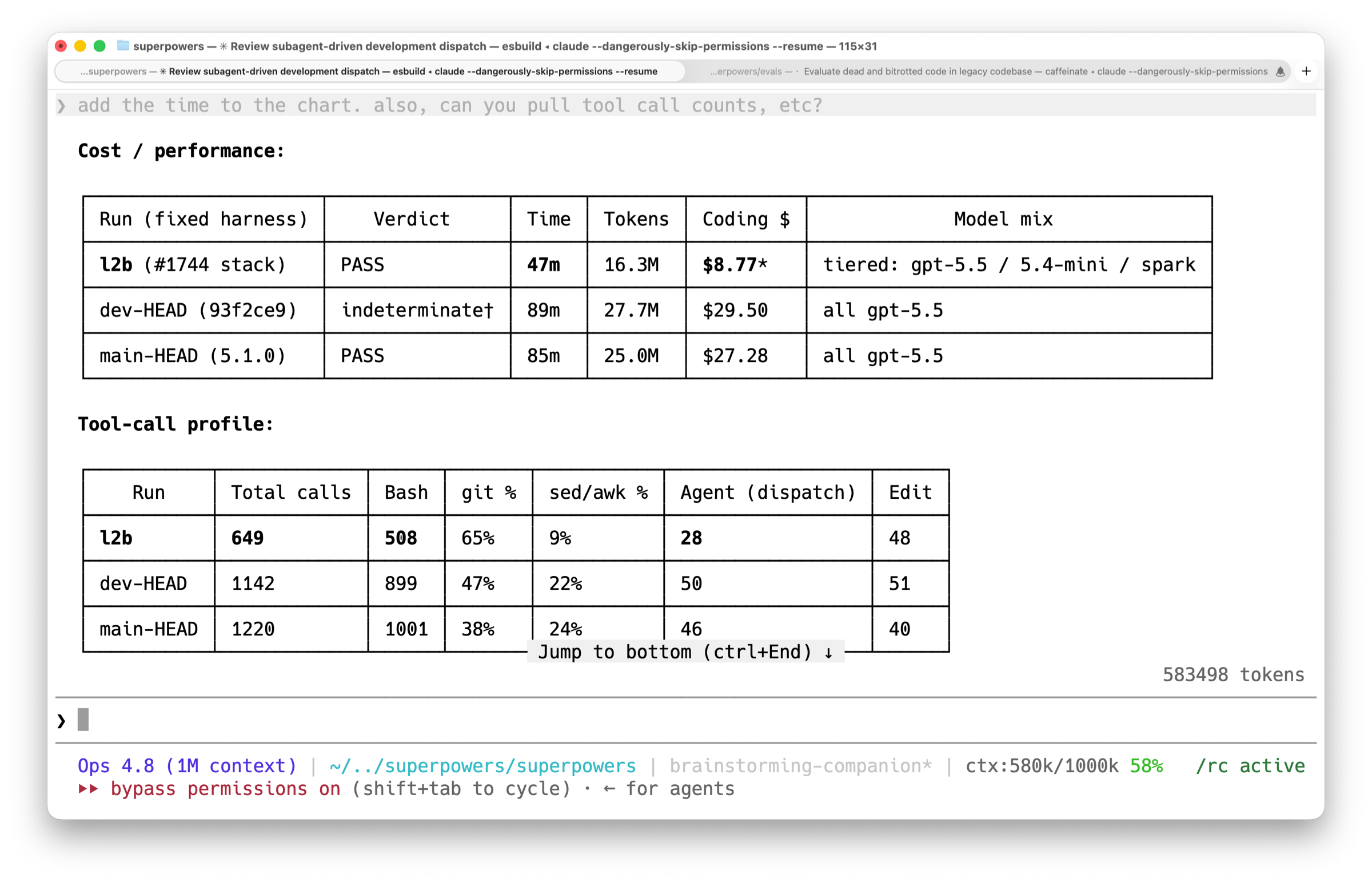
The biggest improvements came from combining the spec compliance and code quality review agents, pre-baking the review "packet" handed to the reviewers so they rarely need to run git, and changing the guidance we give to the orchestrator about what kind of agent you need for a given task.
简而言之,经过大约 36 小时的工作和原本需要 650 美元未补贴 token 消耗,我们的 Anthropic 评估基准显示,Superpowers 构建的挂钟运行时间减少了 50%,token 消耗减少了 60%。
然后我们在 Codex 上运行了评估。结果并不理想。我担心过它们可能不会显示出同样程度的改进,但结果是没有任何改进。
几分钟的排查后,我们找到了罪魁祸首。在 Codex 上,评估还没有与宿主操作系统充分隔离……所以我们一直在对 Superpowers 5.1.0 进行基准测试。
稍微调整后……没错,一切如预期。
最大的改进来自:合并规范合规审查 agent 和代码质量审查 agent,预生成交给审查者的审查“包”(因此他们很少需要运行 git),以及调整我们给 orchestrator 的指导——针对给定任务需要何种 agent。
We've been working hard on our evals suite for Superpowers and without it, it would have been impossible to measure and test the changes we made. It is still relatively young, but it has meant that we're able to make and test changes to Superpowers across a variety of supported harnesses and to quantify what those changes do across a growing set of coding agents. You can find it at https://github.com/prime-radiant-inc/superpowers-evals
We're very proud of the improvements that we (and our robot buddies) have made in Superpowers 6. We think you're going to love the new version.
You can install it right now from https://github.com/obra/superpowers. It'll start to percolate into the first party plugin marketplaces over the next couple of days.
PS: We're hiring! If you know someone who should be working on Superpowers full time, please share the posting with them: https://primeradiant.com/jobs/superpowers-community-engineer/
我们一直在努力开发 Superpowers 的评估套件,没有它,就不可能测量和测试我们做出的改变。虽然它还相对年轻,但它已经让我们能够跨多种支持的 harness 对 Superpowers 进行修改和测试,并量化这些改动在一组不断增长的编码 agent 上的效果。你可以在 https://github.com/prime-radiant-inc/superpowers-evals 找到它。
我们为(我们和我们的机器人伙伴们)在 Superpowers 6 中实现的改进感到非常自豪。我们相信你会喜欢这个新版本。
你现在就可以从 https://github.com/obra/superpowers 安装它。它将在未来几天内渗透到第一方插件市场中。
PS:我们正在招聘!如果你认识应该全职从事 Superpowers 工作的人,请将职位信息分享给他们:https://primeradiant.com/jobs/superpowers-community-engineer/