Headless Tools:让智能体直接在浏览器和桌面应用里执行动作
这篇文章提出了一种名为 Headless Tools 的新机制,解决了智能体(Agent)无法直接操控用户端运行环境的问题。 作者指出,当前大多数 Agent 工具运行在服务端,可以调用 API,但无法访问浏览器、应用状态或设备能力(如剪贴板、定位、本地存储)。Headless Tools 将客户端能力(如 navigator.geolocation、IndexedDB、应用内导航)封装为模型可以调用的标准工具,模型感知不到工具实际执行的位置,服务端和客户端负责协调,使 Agent 能直接作用于用户所在的浏览器或桌面应用。文章提供了 TypeScript 代码示例,并展示了在 Slidev 演示框架和浏览器本地记忆中的具体应用。这一设计同时带来了隐私优势,因为敏感数据可以默认留在本地,无需发送到后端。本文适合需要构建深度集成前端应用的 Agent 系统的工程师阅读,特别是那些在 Figma 插件、富文本编辑器或桌面工具中嵌入 AI 能力的团队。
Today's agents are increasingly capable, but many of the capabilities users care about live in the client runtime rather than on the server. Browsers and applications own things like local state, user selections, device APIs, and application-specific actions that are often unavailable through backend systems. As a result, agents can reason about what should happen next but still struggle to act on the environment where the user is actually working.
One reason for this gap is that most agent tools execute on the server. When a model decides to use a tool, the agent runs it in-process or delegates it to an external service such as an MCP server, then feeds the result back into the reasoning loop. This works well for APIs, databases, and backend systems, but it has clear limitations:
- It cannot directly access browser-only or device-only APIs.
- It cannot act on frontend state that has never been synchronized to the server.
- It often forces privacy-sensitive data to leave the device.
- It introduces unnecessary round trips for actions that are inherently local.
如今的 Agent 越来越强大,但用户真正关心的许多能力都存在于客户端运行时,而非服务器端。浏览器和应用程序拥有本地状态、用户选择、设备 API 以及特定应用的操作,后端系统通常无法触及这些。因此,Agent 虽然能推理下一步该做什么,却难以在用户实际工作的环境中执行操作。
这种脱节的一个原因在于:多数 Agent 工具是在服务器端运行的。当模型决定使用某个工具时,Agent 会在进程内执行,或委托给外部服务(如 MCP 服务器),然后将结果送回推理循环。这对 API、数据库和后端系统来说行之有效,但存在明显的局限:
- 无法直接访问浏览器或设备特有的 API。
- 无法对从未同步到服务器的前端状态执行操作。
- 经常迫使隐私敏感的数据离开设备。
- 对本质上属于本地操作的行为引入了不必要的往返。
The browser is where many high-value agent actions actually happen: reading local application state, acting on the current UI, and using device capabilities without shipping that data to a backend first. Desktop apps expose the same pattern through local files, native integrations, and session-specific state. If your agent cannot reach that runtime, it stays good at backend workflows but weak at the interactions users actually experience.
Imagine you are building a sidecar agent for Figma, Google Slides, or a rich-text editor. The agent can reason about the user's request on the server, but the document model, selection state, and editing commands all live in the client. A server-side tool cannot insert text at the cursor, reformat the selected object, or jump to the active slide, because those actions belong to the application runtime, not the backend API. Today, teams usually bridge this with an ad-hoc UI bridge: serialize some client state to the server, get a response back, then imperatively patch the client. It works, but it is fragile, hard to compose, and invisible to the model's reasoning loop.
浏览器是许多高价值 Agent 操作实际发生的地方:读取本地应用状态、对当前 UI 执行操作、使用设备能力而无需先将数据发送到后端。桌面应用通过本地文件、原生集成和会话特定状态也展现出相同的模式。如果你的 Agent 无法触及那个运行时,它就只擅长后端工作流,而在用户实际体验的交互上表现薄弱。
假设你正在为 Figma、Google Slides 或富文本编辑器构建一个辅助 Agent。Agent 可以在服务器端推理用户的请求,但文档模型、选择状态和编辑命令全都存在于客户端。服务器端工具无法在光标处插入文本、重新格式化选中的对象或跳转到活动的幻灯片,因为这些操作属于应用运行时,而不是后端 API。如今,团队通常通过一个临时的 UI 桥来接合:将一些客户端状态序列化到服务器,获取响应,然后强制性地修补客户端。这种方式可行,但脆弱、难以组合,并且对模型的推理循环来说是透明的。
That is the problem headless tools solve in LangChain.
What headless tools change
A headless tool looks like any other tool to the model: it has a name, a description, and a set of expected inputs. The model decides when to call it, just like any other tool. The difference is what happens next.
Instead of the server running the tool itself, it sends the tool call to the client: the user's browser, desktop app, or whatever environment actually has the capability. The client runs the tool locally and sends the result back, and the agent picks up where it left off.

While this sounds like a small implementation detail at first, it actually changes what kinds of systems an agent can reliably control.
The model never needs to know where the tool runs. It sees a tool, decides to use it, and gets a result. But behind the scenes, the server and the client are coordinating: the server knows what the agent wants to do, and the client knows how to do it. That separation is the core idea.

You could wire this up manually, call navigator.geolocation.getCurrentPosition() from your React app and send the result to the agent. But then the model has no way to discover or decide when to invoke that capability. It lives outside the reasoning loop as an ad-hoc side channel. Headless tools put client-side actions inside the agent's reasoning loop, not alongside it.
这正是 LangChain 中 headless tools 所解决的问题。
Headless tools 改变了什么
对模型来说,headless tool 看起来和其他工具一模一样:有名称、描述和一组预期的输入。模型决定何时调用它,就像调用任何其他工具一样。不同之处在于接下来发生了什么。
服务器不再自己运行该工具,而是将工具调用发送给客户端——用户的浏览器、桌面应用或任何实际具备该能力的运行环境。客户端在本地运行工具并将结果发回,Agent 从断点处继续执行。
虽然这听起来起初只是一个实现细节的变化,但它实际上改变了 Agent 能够可靠控制的系统类型。
模型永远不需要知道工具在哪里运行。它看到一个工具,决定使用它,然后获得结果。但在背后,服务器和客户端正在协调:服务器知道 Agent 想做什么,客户端知道如何去做。这种分离是核心思想。
你也可以手动实现这个流程:从 React 应用调用 navigator.geolocation.getCurrentPosition(),然后将结果发送给 Agent。但这样一来,模型就无法发现或决定何时调用该能力——它位于推理循环之外,是一个临时的侧信道。Headless tools 则将客户端操作放入了 Agent 的推理循环内部,而不是与它并列。
Why this matters
The benefit is not just "browser access." Imagine an agent helping you work through a slide deck: it should be able to jump to the active slide, read local context, and update the presentation in place without shipping the whole session to a backend. Headless tools make that kind of interaction possible by exposing client-side capabilities as real tools inside the agent loop.
Some operations are impossible to emulate correctly on the backend. Geolocation is the obvious example — the browser owns permission prompts and device signals. Clipboard access, canvas rendering, file pickers, and live UI navigation all depend on the active client environment. A standard tool can approximate these through a backend service. A headless tool can call the real thing.

But headless tools are not just for browser APIs. They are a general mechanism for giving agents safe access to application-native actions. For example: slidev-agent , a plugin for the popular Slidev presentation framework, uses a headless tool to navigate to a specific slide in the user's active presentation. This is not a data retrieval problem or a server automation problem.
This pattern also changes privacy tradeoffs. Agent memory does not always belong in a centralized backend. With a headless tool backed by a browser storage like IndexedDB, memory can stay local by default — durable, low-latency, and naturally scoped to that user and browser — without turning recall into a server-side data management problem.
这为什么重要
好处不仅仅是“浏览器访问”。假设一个 Agent 正在帮你处理幻灯片集:它应该能跳转到当前活动的幻灯片、读取本地上下文并在原地更新演示文稿,而无需将整个会话发送到后端。Headless tools 通过将客户端能力作为真正的工具暴露在 Agent 循环内部,使这种交互成为可能。
有些操作在后端是无法正确模拟的。地理位置是最明显的例子——浏览器拥有权限提示和设备信号。剪贴板访问、画布渲染、文件选择器和实时 UI 导航都依赖于活动的客户端环境。标准的工具可以通过后端服务来近似实现,而 headless tool 可以调用真实的功能。
但 headless tools 并不仅限于浏览器 API。它们是一种通用机制,可以让 Agent 安全地访问应用程序原生操作。例如,slidev-agent(一个针对流行演示框架 Slidev 的插件)使用 headless tool 在用户当前演示文稿中导航到特定幻灯片。这不是一个数据检索问题,也不是一个服务器自动化问题。
这种模式也改变了隐私权衡。Agent 记忆并不总属于集中式后端。借助由 IndexedDB 等浏览器存储支持的 headless tool,记忆可以默认保持在本地——持久、低延迟、自然限定在该用户和浏览器范围内——而无需将召回变成一个服务器端的数据管理问题。
How it works in code
In TypeScript, the separation between definition and implementation is especially clean. You define the tool once, attach the implementation with .implement(...), and pass the implementation into the frontend streaming hook. The server and client share the same schema, but only the client loads the browser-specific execution logic.

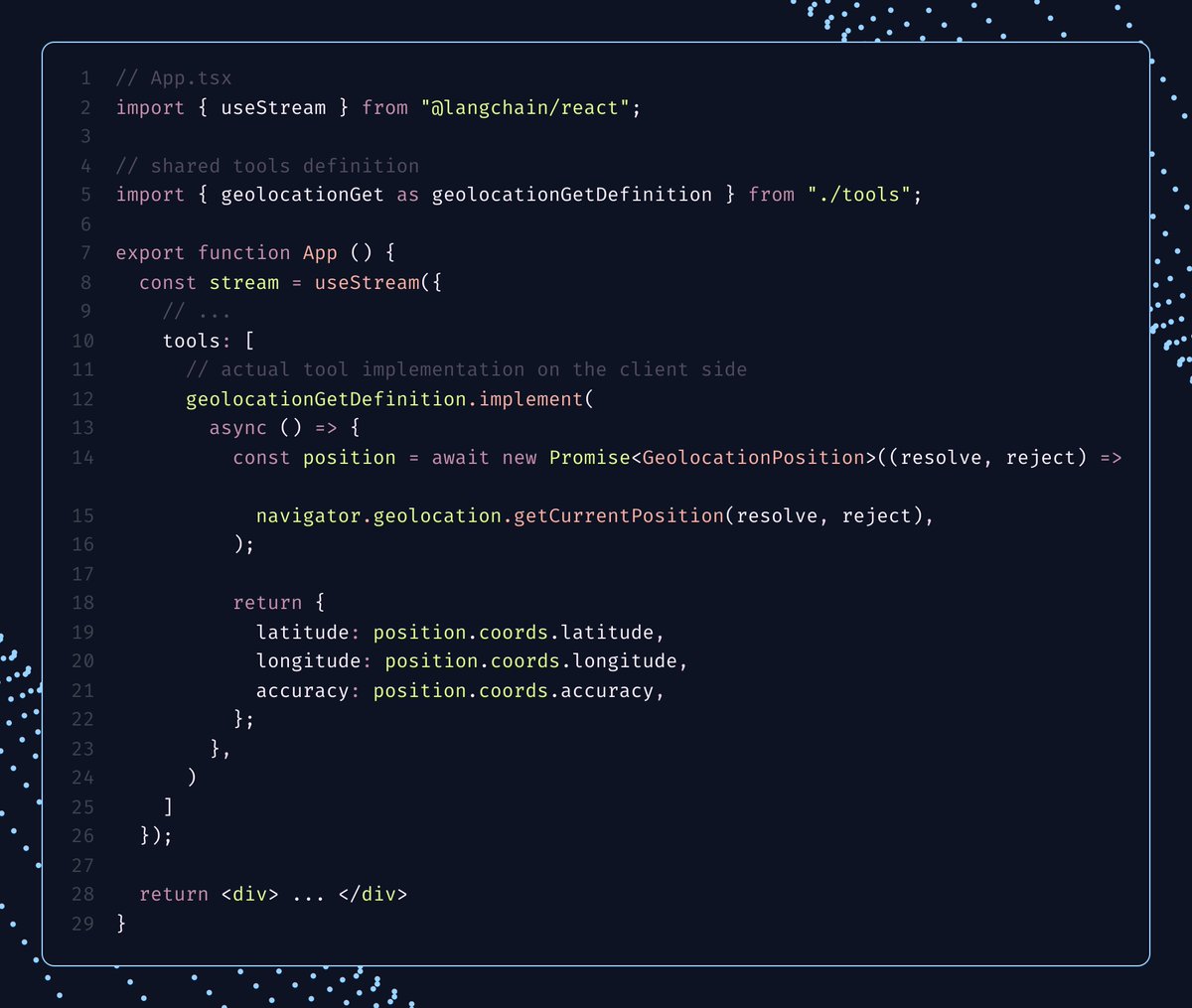
Check out a live demo in our LangChain docs, combining browser-local memory with geolocation and optional human approval.
代码中的实现方式
在 TypeScript 中,定义与实现的分离尤为清晰。你只需定义工具一次,通过 .implement(...) 附加实现,然后将实现传入前端的流式处理钩子。服务器和客户端共享同一套 schema,但只有客户端加载浏览器特定的执行逻辑。
请查看我们 LangChain 文档中的实时 demo,它结合了浏览器本地内存、地理位置以及可选的人工审批功能。
Summary
Standard tools gave agents access to backend systems. Headless tools give them access to where users actually work.
Users do not live on your backend. They live in browsers, apps, and devices, where many of the most valuable agent interactions happen. Headless tools make those interactions available while preserving typed schemas, explicit capabilities, structured outputs, and reviewability, allowing agents to use tools that are native to the user, not just convenient for the server.
Get started with headless tools in LangChain Python or LangChain JS.
Thanks to @huntlovell, @colifran, and @sydneyrunkle for their thoughtful review and feedback.
总结
标准工具让 Agent 能够访问后端系统。Headless tools 则让 Agent 能够触及用户实际工作的环境。
用户并不生活在你的后端里。他们生活在浏览器、应用和设备中,许多最有价值的 Agent 交互就发生在这里。Headless tools 在保留类型化 schema、显式能力、结构化输出和可审查性的同时,使这些交互可用,让 Agent 能够使用对用户而言原生的工具,而不仅仅是对服务器方便的工具。
从 LangChain Python 或 LangChain JS 开始使用 headless tools 吧。
感谢 @huntlovell、@colifran 和 @sydneyrunkle 深思熟虑的审阅和反馈。