AI 重塑软件生命周期:从编写代码到评判代码的转变
这篇由 Google 工程师撰写的白皮书提炼,核心观点是:AI Agent 的真正价值不在于模型本身,而在于其“载体”(Harness)——即指令、工具、沙箱、编排逻辑和可观测性组成的系统,模型约占 10%,载体占 90%。上下文工程是决定成本的关键,需要区分静态上下文(每次加载,昂贵但可靠)和动态上下文(按需加载,便宜但需谨慎设计)。验证能力是区分“Vibe Coding”和真正的工程化 Agent 的分界线:测试覆盖确定性部分,评估覆盖非确定性输出和轨迹。白皮书提供了具体数据:仅修改载体(不换模型)即可将编码 Agent 在 Terminal Bench 2.0 上从 30 名外提升至前 5;LangChain 的实验中通过修改系统提示、工具和中间件在相同基准上提升了 13.7 分。适用于所有正在或准备将 AI Agent 引入研发流程的工程师和技术管理者。
I co-wrote a Google whitepaper about how AI is changing the software lifecycle. I’m not going to summarize the whole thing. Instead, here are the handful of ideas in it I think actually matter, plus six figures you’re welcome to reuse.
Google published The New SDLC With Vibe Coding this week. I co-wrote it with Shubham Saboo and Sokratis Kartakis, and it’s the first in a short series.
It’s a Day 1 paper, so the early pages cover the basics: what an agent is, what “vibe coding” means, why the job is moving from writing code to judging it. If you read this blog you already have all of that. I’m going to skip it and write about the parts I think are worth your time, with six of the figures pulled out. Reuse the figures wherever you like.
我参与合著了一篇关于 AI 如何改变软件生命周期的 Google 白皮书。我不打算概括全文,而是挑出我认为真正重要的几个想法,外加六张图,大家可以任意复用。
本周 Google 发布了《Vibe Coding 带来的新 SDLC》。我与 Shubham Saboo 和 Sokratis Kartakis 合著了此文,它是一个短系列的第一篇。
作为 Day 1 论文,开头几页覆盖了基础知识:什么是 agent,什么是“vibe coding”,为什么工作正从写代码转向评判代码。如果你读这个博客,这些你已经知道了。我会跳过这部分,只写我认为值得你花时间的内容,并抽出六张图,大家可以随意复用。
Here’s the framing from the paper that I keep coming back to: an agent is a model plus a harness.
The model is one input. Everything else is the harness: the instructions and rule files, the tools and MCP servers, the sandboxes it runs in, the orchestration logic that spawns sub-agents and routes between models, the hooks that run deterministic code at set points, and the observability that tells you when it’s drifting. The paper’s rough split is 10% model, 90% harness. That sounds high until you’ve spent a week debugging one.
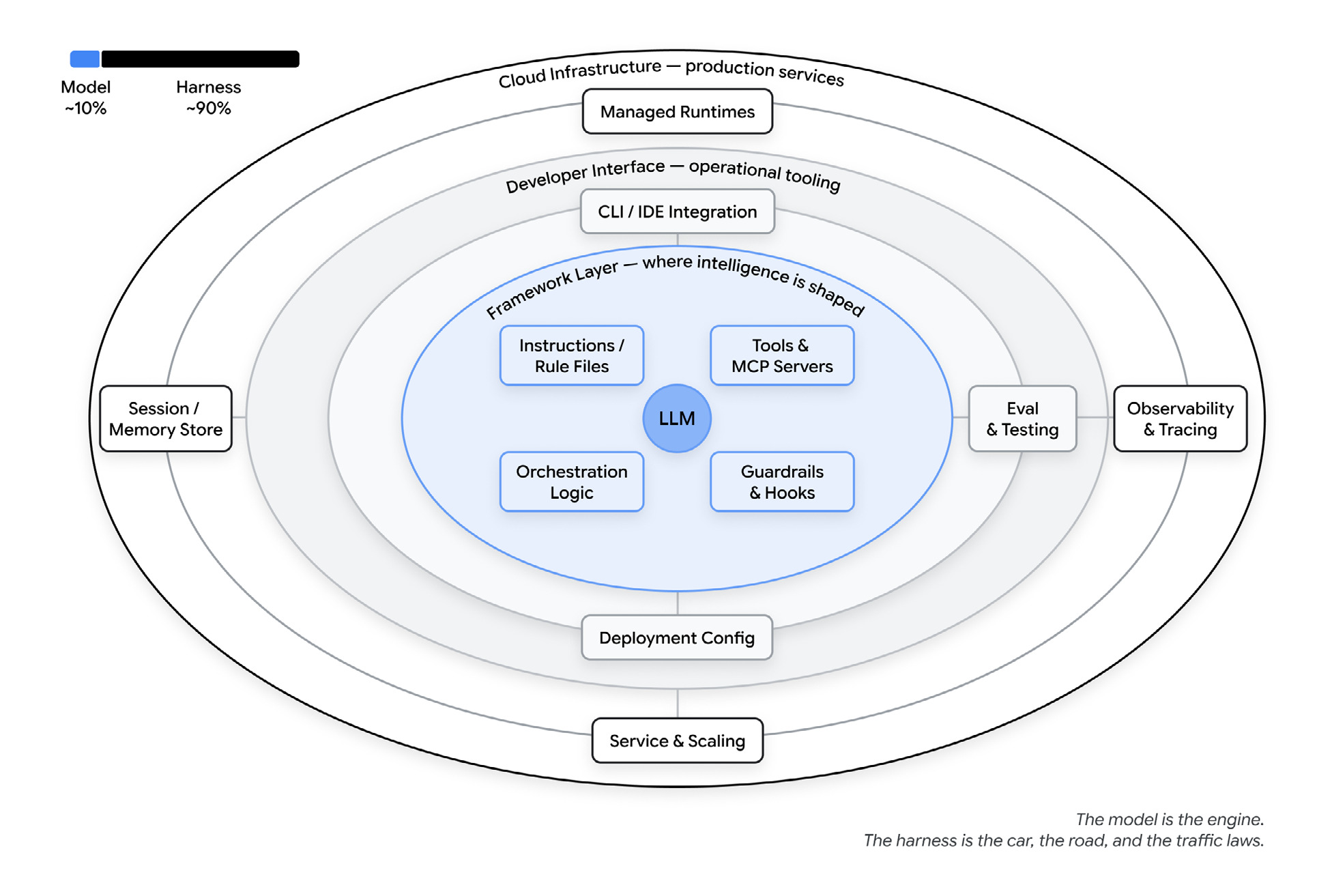
The model is the engine. The harness is the car, the road, and the traffic laws.
论文中有一个我反复回味的框架:Agent 是模型加套件。
模型只是一个输入。其他一切都是套件:指令和规则文件、工具和 MCP 服务器、运行沙盒、生成子 agent 并在模型间路由的编排逻辑、在固定点运行确定性代码的钩子,以及告诉你何时偏移的可观测性。论文中粗略的划分是 10% 模型、90% 套件。这个比例听起来很高,但你花一周调试一个 Agent 后就不会这么认为了。
模型是引擎。套件是汽车、道路和交通法规。
A couple of public numbers make this concrete. On Terminal Bench 2.0, one team moved a coding agent from outside the top 30 into the top 5 by changing only the harness, with the same model underneath. A separate experiment at LangChain added 13.7 points on the same benchmark by changing just the system prompt, tools and middleware around a fixed model. Neither touched the model.
So when an agent does something dumb, I’ve learned to debug the harness first. Usually it’s a missing tool, a rule I wrote too loosely, a guardrail I forgot, or a context window full of junk. Most agent failures are configuration failures. I find that encouraging, because configuration is the part I can fix today, without waiting for a better model. The model will get swapped out under the harness sooner or later anyway. I’ve written this up at more length as harness engineering and the factory model.
几个公开数据让这个观点更具体。在 Terminal Bench 2.0 上,一个团队只修改套件,不换底层模型,就把编码 Agent 从 30 名开外提升到前 5 名。LangChain 的另一个实验在相同基准上,只改系统提示、工具和中间件,就增加了 13.7 分。两者都没碰模型。
所以当 Agent 做傻事时,我学会先调试套件。通常是缺少某个工具、我写得太松的规则、忘记设的护栏、或塞满垃圾的上下文窗口。大多数 Agent 故障都是配置故障。我觉得这很鼓舞人心,因为配置是我今天就能修复的部分,无需等待更好的模型。模型迟早会被套件底下的新版本替换掉。我以“套件工程与工厂模式”为题详细写过这个观点。
If the harness is the system, context engineering is the most important knob inside it. The paper sorts agent context into six types: instructions, knowledge, memory, examples, tools and guardrails. The interesting decision, the one that shows up on your bill, is what goes in static versus dynamic context.
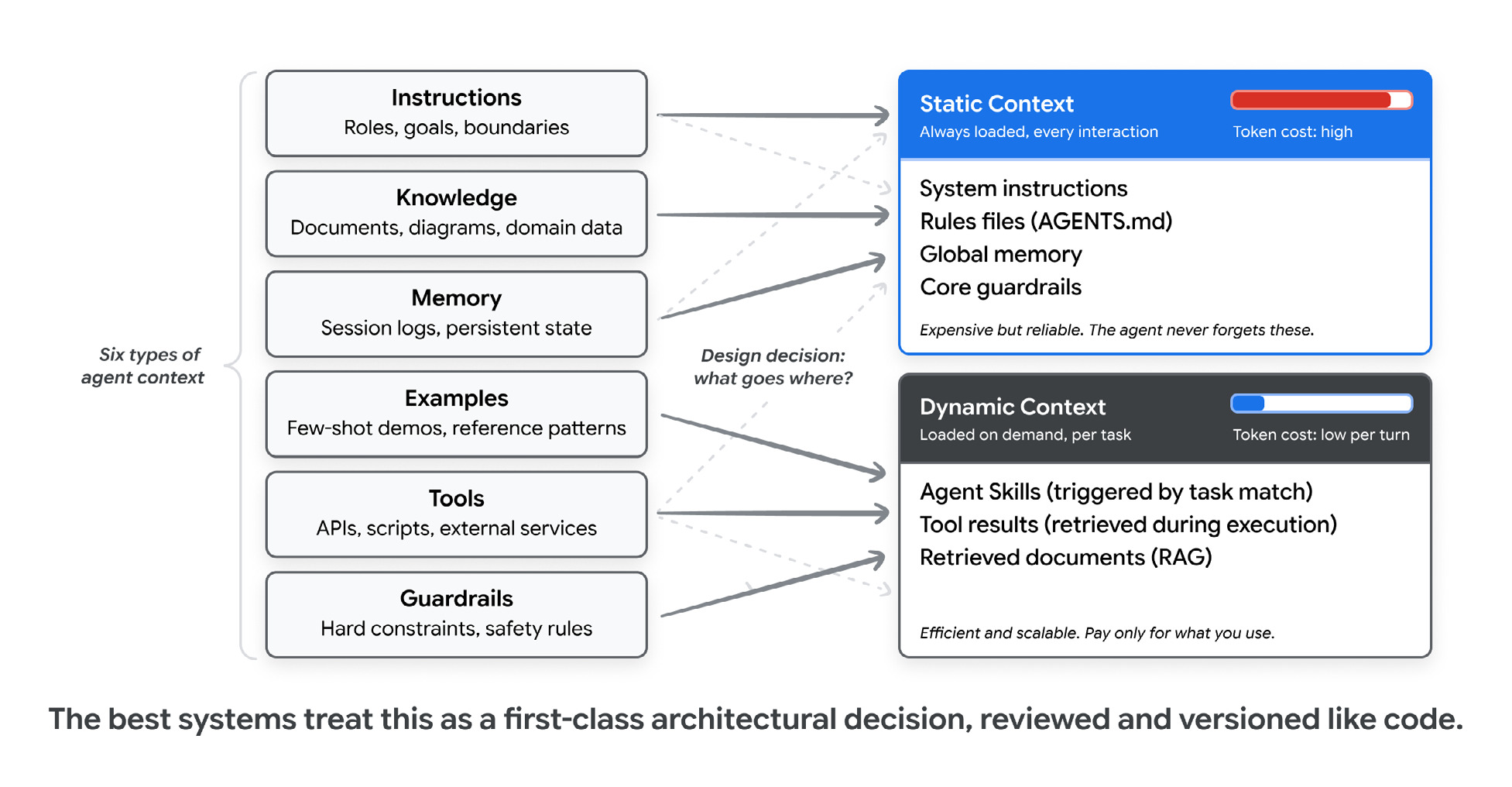
Static context is loaded on every turn, so it’s reliable and expensive. Dynamic context is loaded on demand, so you only pay for what a task needs.
如果套件是系统,那么上下文工程就是其中最重要的旋钮。论文将 Agent 上下文分为六类:指令、知识、记忆、示例、工具和护栏。一个有趣的决定——会体现在你账单上的那个——是哪些放入静态上下文,哪些放入动态上下文。
静态上下文每轮都加载,因此可靠且昂贵。动态上下文按需加载,你只为任务所需的部分付费。
Static context is loaded every turn: system instructions, rule files (AGENTS.md, CLAUDE.md, GEMINI.md), global memory, core guardrails. It’s reliable, and it’s expensive, because you pay for it on every single call. Dynamic context is loaded on demand: skills that fire when a task matches, tool results, documents pulled from RAG. You only pay for the bits a given task touches.
Get that balance wrong in one direction and you burn tokens and bury the signal. Wrong in the other and the agent forgets the rules that keep it safe. The paper’s advice, which I agree with, is to treat the boundary as a real architectural decision: reviewed in a pull request, versioned like code.
The trick that makes dynamic context scale is Agent Skills with progressive disclosure. The agent sees a little metadata at startup, loads the full instructions when a task matches, and only pulls in the heavy reference material when it actually needs it. That’s how one agent can carry dozens of skills and still only pay for the one it’s using.
静态上下文每轮都加载:系统指令、规则文件(AGENTS.md、CLAUDE.md、GEMINI.md)、全局记忆、核心护栏。它可靠,但昂贵,因为你为每次调用付费。动态上下文按需加载:任务匹配时触发的技能、工具结果、从 RAG 拉取的文档。你只为给定任务触及的部分付费。
平衡搞错一边,你会浪费令牌并淹没信号;搞错另一边,Agent 会忘记保护它的规则。论文的建议——我同意——是将这个边界视为真正的架构决策:在 PR 中审查,像代码一样版本化。
让动态上下文可扩展的技巧是采用渐进式披露的 Agent 技能。Agent 在启动时看到少量元数据,任务匹配时加载完整指令,只有实际需要时才拉取重参考材料。这就是一个 Agent 能携带几十个技能却只为正在用的那个付费的原因。
You can sit anywhere on the spectrum from vibe coding to agentic engineering with the same agent. The thing that decides where you land is verification.
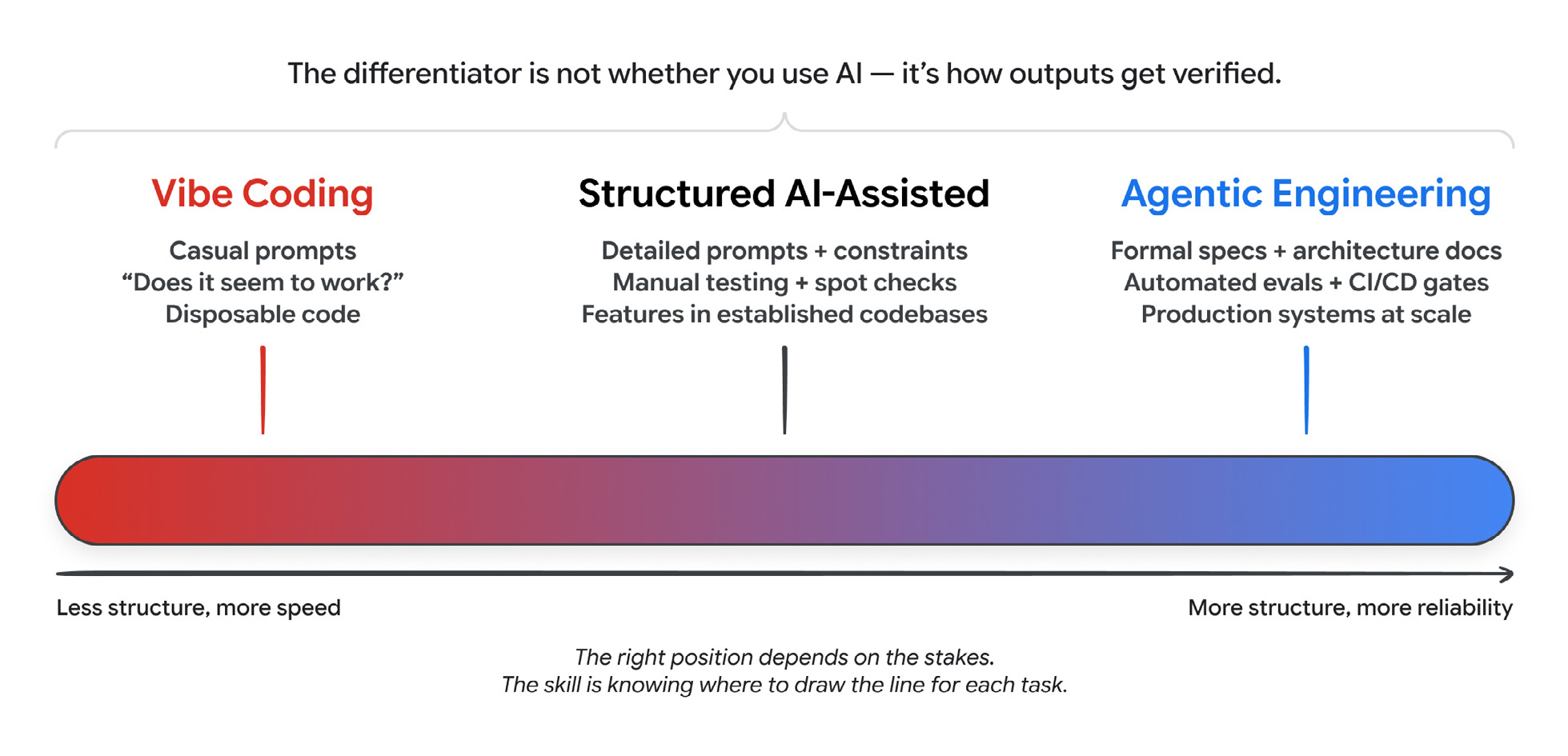
The right spot on the spectrum depends on the stakes. The skill is knowing where to draw the line for each task.
同一个 Agent 可以在从 vibe coding 到 agentic engineering 的光谱上任意放置。决定落点的因素是验证。
光谱上的合适位置取决于风险大小。技能在于知道每项任务在哪里划线。
There are two mechanisms. Tests cover the deterministic parts: this input, that output. Evals cover the parts that aren’t deterministic, and the paper splits them in a way I found useful. Output evaluation asks whether the final result is correct. Trajectory evaluation asks whether the path it took to get there, the tool calls and the reasoning, was sound. You want both. An answer that looks right but skipped its checks is more dangerous than one that’s obviously broken.
If I had to hand a leader one line from the paper, it’s this: set the bar at the eval, not the demo. A demo shows an agent can work once. An eval suite with a real rubric shows it works reliably. I keep making this argument; see agentic code review.
有两种机制。测试覆盖确定性部分:这个输入、那个输出。评估覆盖非确定性部分,论文将其拆分为两种,我发现很有用。产出评估问最终结果是否正确。轨迹评估问到达结果所走的路径——工具调用和推理——是否合理。两者都需要。看起来正确但跳过检查的答案比明显有问题的更危险。
如果我要给领导者一句论文中的话,那就是:把标准定在评估上,而不是演示上。演示表明 Agent 能工作一次。带有真实评分标准的评估套件表明它能可靠工作。我一直在强调这个论点;参见 Agentic Code Review。
AI compresses the lifecycle, but unevenly, and the unevenness is the whole story. Implementation drops from weeks to hours. Requirements, architecture and verification stay slow, because they’re judgment work. So specification quality becomes the bottleneck, and verification moves to the middle.
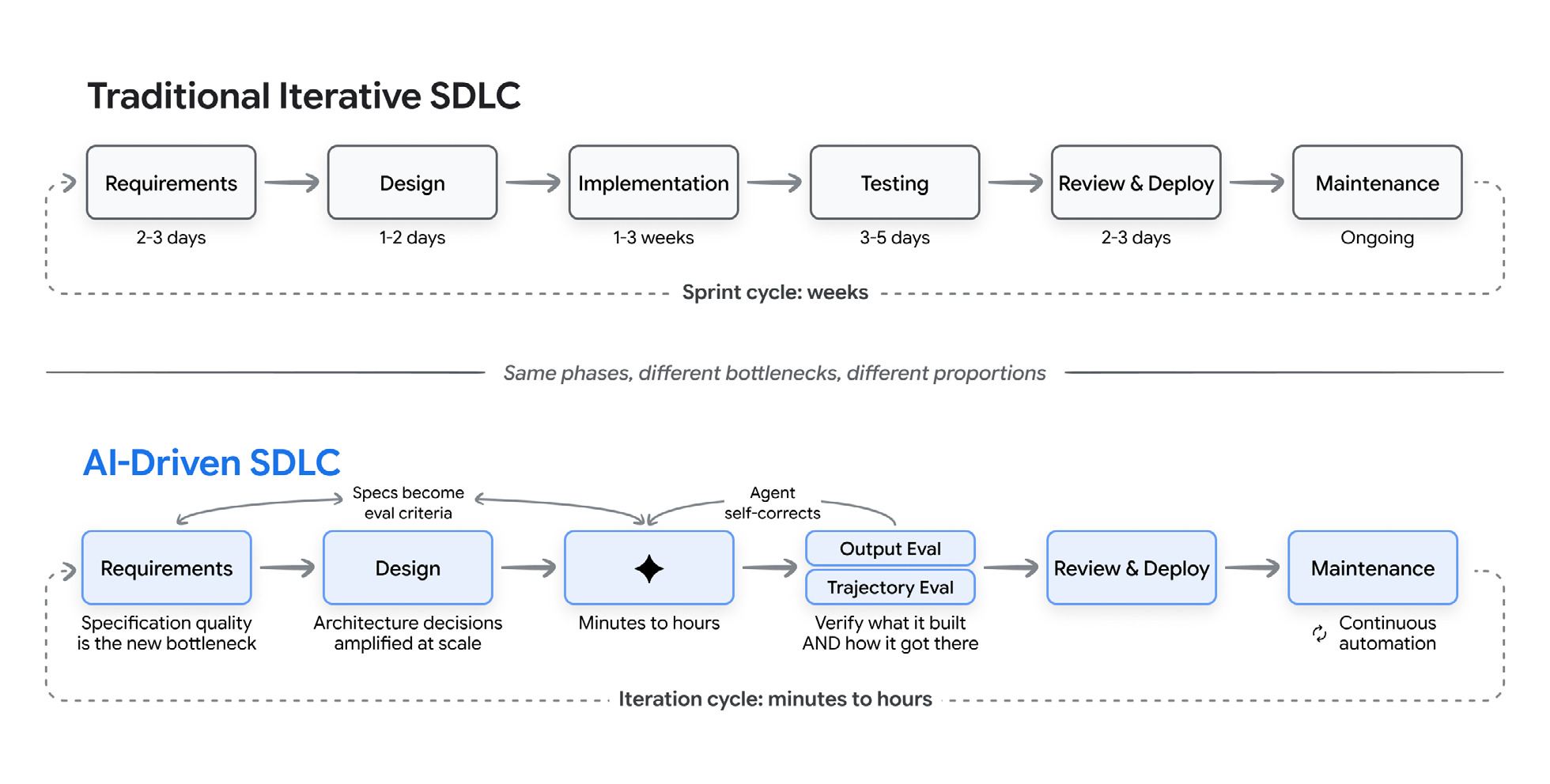
Same phases, different bottlenecks, different proportions.
AI 压缩了生命周期,但压缩不均衡,而不均衡才是关键。实现从几周降到几小时。需求、架构和验证仍然缓慢,因为它们属于判断工作。因此,规格质量成为瓶颈,而验证被移到中间位置。
相同的阶段,不同的瓶颈,不同的比例。
Phase by phase:
Requirements stop being a document you hand between teams. They become a conversation that produces a spec and a first prototype at the same time. The agent drafts user stories from a brief, surfaces edge cases, and turns a description into something that runs in minutes.
逐个阶段来看:
需求不再是你团队间传递的文档。它们变成一场对话,同时产出规格和第一个原型。Agent 根据简报草拟用户故事,揭示边界情况,并将描述变成几分钟内就能运行的东西。
Architecture is the most stubbornly human phase. Trade-offs like consistency versus availability depend on business context the model can’t fully see. The developer’s job becomes making and documenting the structural calls the agent then implements.
架构是最顽固的人类阶段。像一致性与可用性之间的权衡取决于模型无法完全看到的业务上下文。开发者的工作变成做出并记录结构性决策,然后由 Agent 来实现。
Implementation is where the gains and the caveats both live. Surveys put the productivity gain at 25 to 39%. A METR study found experienced developers going 19% slower on some tasks once you count the time spent checking and fixing. Both are true. The honest summary is that AI turns implementation from writing into reviewing.
实现阶段同时蕴含着收益和注意事项。调查显示生产力提升在 25% 到 39% 之间。一项 METR 研究发现,算上检查和修复的时间后,经验丰富的开发者在某些任务上反而慢了 19%。两者都正确。诚实的总结是:AI 将实现从写作变成了审查。
Testing and QA flips around. Your tests and evals become the main way you tell the agent what “correct” means, wired into a loop: run against a benchmark, cluster the failures, fix the prompt or tool that caused them, check against a regression suite, watch production for new ones.
测试和 QA 翻转了。你的测试和评估成为你告诉 Agent“正确”含义的主要方式,嵌入一个循环:在基准上运行、聚类失败、修复导致失败的提示或工具、用回归套件检查、监控生产环境是否有新问题。
Maintenance is the one I think is most underrated. Code that was “too risky to touch” because only its authors understood it can now be read, refactored and modernized by an agent. The migrations and deprecation cleanups that never happened because they were tedious and risky start happening.
The ceiling on all of this is still the 80% problem: agents get the first 80% of a feature fast, and the last 20%, the edge cases and the seams between systems, still needs context the models usually don’t have.
维护阶段是我认为最被低估的。那些因为只有作者能理解而“太危险不敢碰”的代码,现在可以被 Agent 阅读、重构和现代化。那些因为繁琐和风险而从未发生的迁移和弃用清理开始发生了。
这一切的上限仍然是 80% 问题:Agent 能快速完成一个功能的头 80%,但最后 20%——边界情况和系统之间的接缝——仍然需要模型通常不具备的上下文。
The number that matters to a leader isn’t velocity, it’s total cost of ownership. The AI era splits it in a way that flips the usual intuition about which option is cheap.
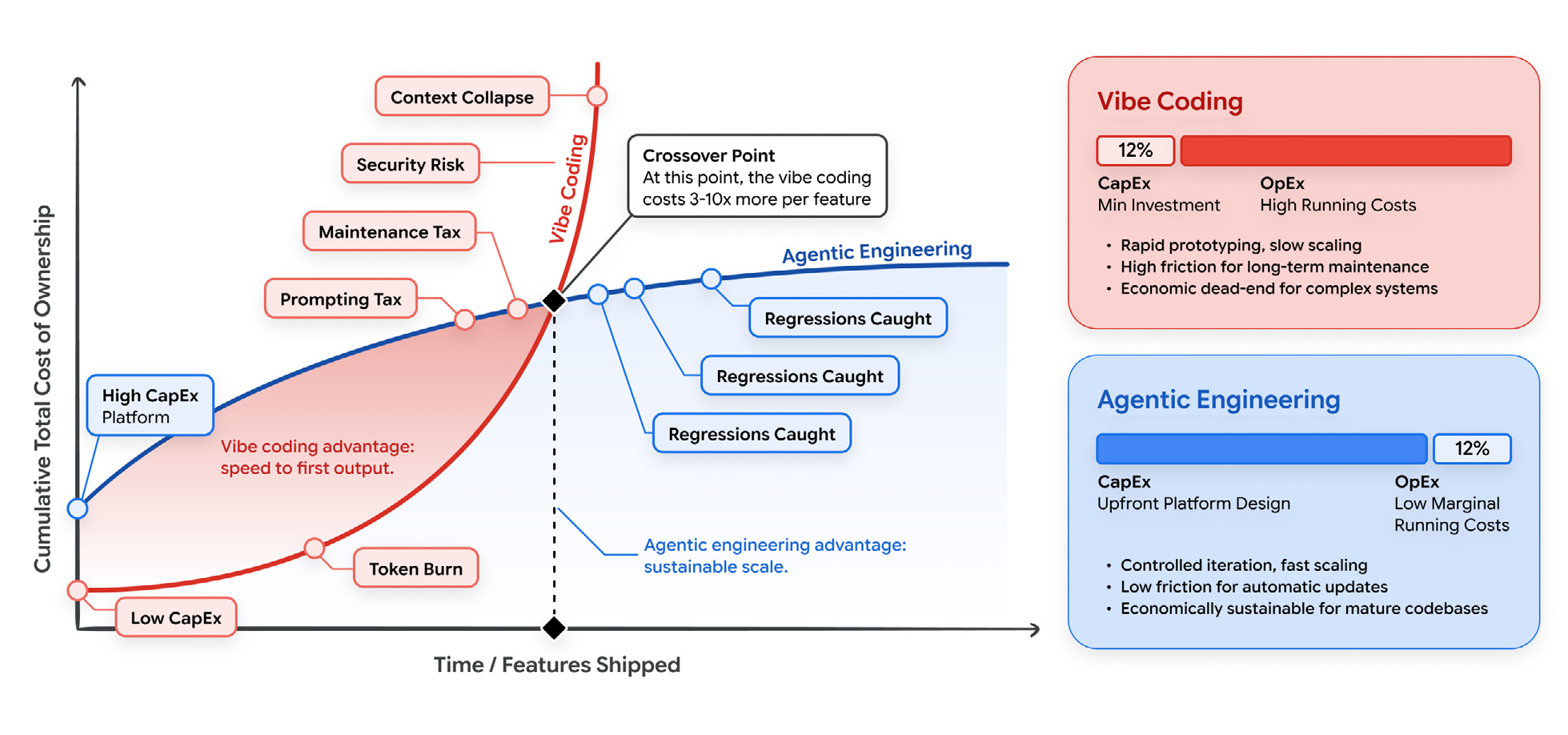
Past the crossover, vibe coding costs 3 to 10x more per feature. How long the code has to live decides whether you ever get there.
对领导者来说,重要的数字不是速度,而是总体拥有成本。AI 时代以某种方式拆分成本,颠覆了通常关于哪个选项便宜的直觉。
过了交叉点后,vibe coding 每个功能的成本高出 3 到 10 倍。代码需要存活多久决定了你是否会达到那个点。
Vibe coding is cheap up front and expensive to run. You pay almost nothing to start: a subscription and some prompts. Then you pay later. Token burn, from throwing unstructured files at the model and asking it to fix its own mistakes. A maintenance tax, when someone has to reverse-engineer the ad-hoc code months later. Security cleanup, because fast generation produces vulnerabilities about as fast as it produces features. Agentic engineering flips that: more up front (schemas, tests, structured context), less per feature after.
The “vibe coding costs 3 to 10x more per feature” crossover is illustrative, not a measured constant. The part I want developers to take away is that context engineering and model routing are financial levers, not just technical ones. You can’t pass a 100,000-token repo into every prompt and expect it to scale. Route the hard reasoning to a big model and the routine work, test generation, code review, CI checks, to a small cheap one. The quality holds and the bill comes down. That’s the money side of what I’ve called the orchestration tax.
Vibe coding 前期便宜,运行昂贵。起步几乎不花钱:一个订阅和一些提示。然后之后付出代价。令牌浪费,来自把非结构化文件扔给模型并要求它修复自己的错误。维护税,几个月后有人必须逆向工程那些临时代码。安全清理,因为快速生成产生漏洞的速度几乎和生成功能一样快。Agentic engineering 则相反:前期投入更多(模式、测试、结构化上下文),之后每个功能成本更低。
“vibe coding 每个功能成本高 3 到 10 倍”这个交叉点是示意性的,不是精确常数。我想让开发者带走的是:上下文工程和模型路由是财务杠杆,不仅仅是技术杠杆。你不能把 10 万令牌的代码库塞进每个提示并期望它可扩展。把困难推理路由到大模型,把常规工作——测试生成、代码审查、CI 检查——路由到小而便宜的模型。质量保持住,账单降下来。这就是我称之为编排税的经济层面。
This is the part of the paper I’m watching most closely. The same terminal workflow that spits out a throwaway script can now produce a production agent, in the same place, often by talking to the coding agent you were already using.
Building, evaluating and deploying a real agent, with persistent memory, scoped permissions, eval coverage and observability, used to be a separate stack and a separate job. Now it folds into the loop you already run. Google’s Agents CLI is built around this. After a one-time install, your coding agent picks up skills for the whole lifecycle, and you drive it in plain language:
one-time setup
uvx google-agents-cli setup
then, in your coding agent:
Build a support agent that answers questions from our docs. Evaluate it on the FAQ dataset. Deploy it to Agent Engine.
Behind that one instruction it scaffolds the project, writes the code, generates an eval set, runs it, deploys to a managed runtime, and reports back. The prototype from your laptop yesterday becomes the production agent serving users today, with no rewrite. Coordination between agents runs on open standards: MCP for tools, A2A for handing work to other agents.
这是论文中我最关注的部分。同一个终端工作流,之前吐出一次性脚本,现在可以生成生产级 Agent,在同一个地方,通常通过和你已经在用的编码 Agent 对话来实现。
构建、评估和部署真正的 Agent——带有持久化记忆、作用域权限、评估覆盖和可观测性——以前是一个独立的堆栈和独立的工作。现在它嵌入你已经在运行的循环中。Google 的 Agents CLI 就是围绕这个设计的。一次性设置后,你的编码 Agent 会获得整个生命周期的技能,你用自然语言驱动它:
一次性设置
uvx google-agents-cli setup
然后在你的编码 agent 中:
构建一个回答文档问题的支持 Agent。 在 FAQ 数据集上评估它。 部署到 Agent Engine。
在这条指令背后,它会搭建项目框架、写代码、生成评估集、运行它、部署到托管运行时并报告结果。你昨天笔记本上的原型,今天变成服务用户的生成级 Agent,无需重写。Agent 之间的协调基于开放标准:MCP 用于工具,A2A 用于将工作交给其他 Agent。
There’s one experiment in the paper I keep mentioning to people. An Anthropic team had a group of agents build a working C compiler in Rust over two weeks, with humans setting direction and reviewing rather than writing the code. That’s roughly the shape of where this is heading.
Day to day you switch between two modes the paper calls the conductor and the orchestrator. The conductor is real-time and in the IDE, keystroke by keystroke, good for exploring and for code you don’t know yet. The orchestrator is async: you hand a goal to one or more agents and review what comes back, good for well-specified work like migrations or test generation. The tooling does both now, sometimes in the same hour. I think the move from conductor to orchestrator is a skills shift before it’s a tooling one.
论文中有一个我常跟人提到的实验。Anthropic 的一个团队让一组 Agent 在两周内用 Rust 构建了一个能工作的 C 编译器,人类设定方向并审查,而不是写代码。这大致就是未来的方向。
日常工作中,你在论文称之为指挥家和指挥官两种模式间切换。指挥家是实时的、在 IDE 中、逐次击键,适合探索和不熟悉的代码。指挥官是异步的:你把目标交给一个或多个 Agent,然后审查返回结果,适合规格清晰的工作,比如迁移或测试生成。工具现在都支持这两种模式,有时在同一小时内切换。我认为从指挥家到指挥官的转变,首先是技能转变,然后才是工具转变。
One more figure, and this one isn’t for you. It’s for the people you’re trying to bring along: the exec who still thinks this is fancy autocomplete, the colleague who hasn’t made the jump.
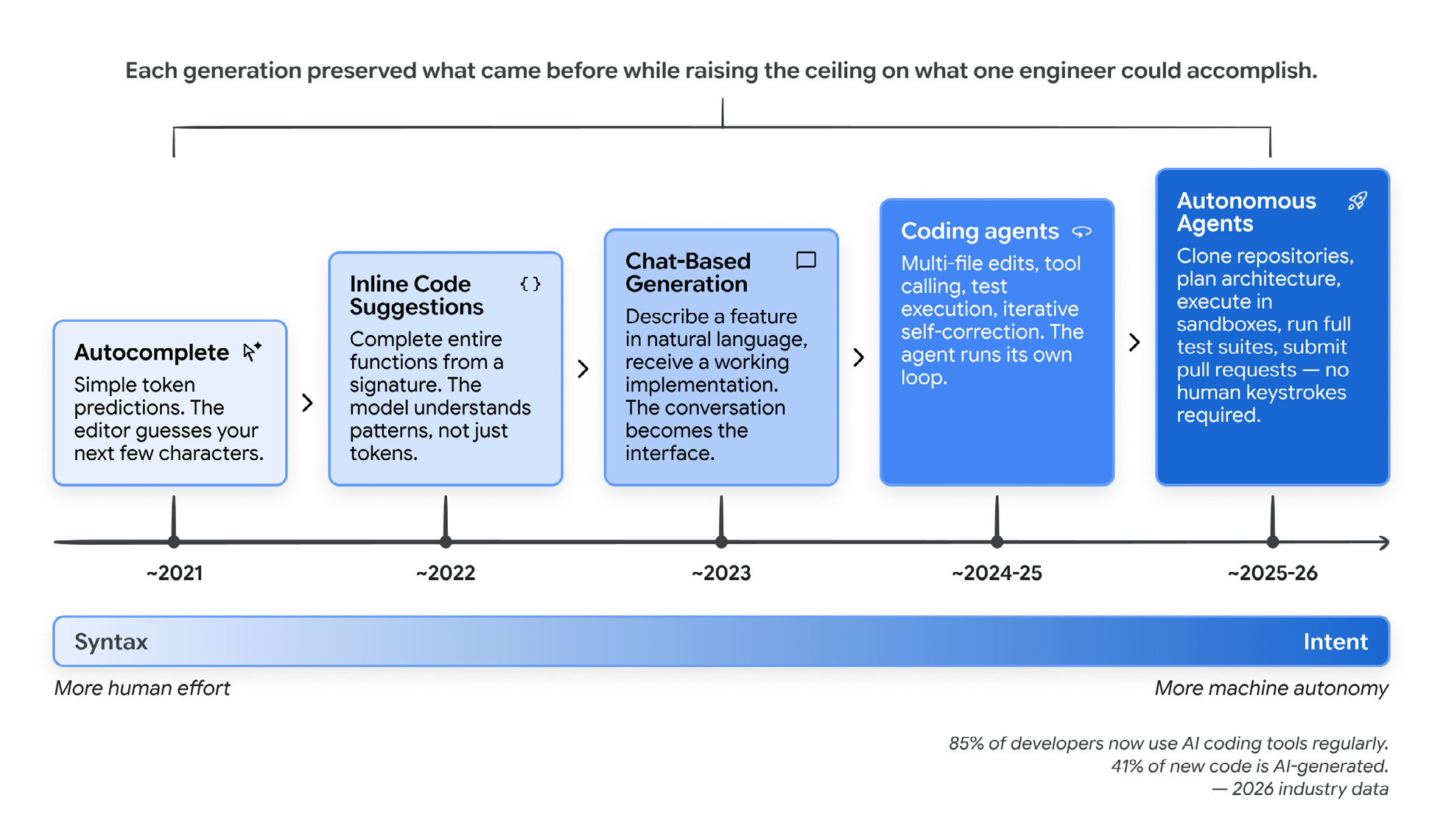
Each generation kept what came before and raised what one engineer could do.
It has the adoption numbers that tend to end the “is this real yet” argument. As of early 2026, 85% of professional developers use AI coding agents regularly, 51% use them daily, and roughly 41% of new code is AI-generated.
还有一张图,这张不是给你的。是给那些你正试图拉来的人:仍然认为这只是花哨自动补全的高管,还没跨出那一步的同事。
每一代都保留了前一代的能力,并提升了一个工程师能做的事情。
它包含的采纳数据通常能终结“这到底是不是真的”的争论。截至 2026 年初,85% 的专业开发者定期使用 AI 编码 Agent,51% 每天使用,大约 41% 的新代码是 AI 生成的。
The paper closes with a longer set of recommendations for individuals, leaders and organizations. I won’t repeat them all here.
If there’s one line to take from it, it’s that AI amplifies whatever engineering culture it lands in, the good parts and the bad parts both. Generation is mostly solved now. The work that’s left is specification and verification, and the systems that hold them together. That’s the part I’d get good at.
The full paper is here.
论文结尾给出了给个人、领导者和组织的更长建议清单。我不在这里全部重复。
如果要从中提炼一条,那就是:AI 会放大它所处的任何工程文化,好的部分和坏的部分都是。生成现在基本解决了。剩下的工作是规格和验证,以及支撑它们的系统。这就是我建议你擅长的部分。
全文在这里。