20 AI Concepts You Must Understand in 2026
A beginner-friendly primer covering 20 core AI concepts split into four parts: foundational mechanisms, how LLMs work, how models improve, and how real systems are built. Uses simple analogies and visuals to explain neural networks, transformers, RAG, agents, and more. No code or deep implementation details — a quick reference for building mental models.

Everyone uses AI.
Almost nobody understands how it actually works.
People throw around words like transformers, embeddings, RAG, agents, RLHF…
…as if everyone already knows.
Most don't.
And honestly?
AI is not that complicated once you see the mental models.
ChatGPT. Claude. Midjourney. Cursor. Coding agents.
They all make sense once you understand the 20 ideas below.
No PhD required. No jargon. Just simple explanations and visuals.
Save this. You will use it again.
人人都在用AI。
但几乎没人真正理解它怎么运作。
到处都在说 transformer、embedding、RAG、agent、RLHF……
好像每个人本来就知道似的。
其实大多数人并不懂。
诚实地说一句?
只要建立起正确的思维模型,AI 根本没那么复杂。
ChatGPT、Claude、Midjourney、Cursor、编程助手……
通通在理解下面的 20 个概念后就会豁然开朗。
不需要博士头衔,没装着晦涩术语,只有简洁的讲解和图示。
存下来,迟早会回来翻。
- Neural Networks

The brain of every AI model.
A neural network is a pipeline of layers.
→ Data enters the input layer → Passes through hidden layers → Exits as a prediction
Each connection has a "weight" — a tiny score that controls how much influence one neuron has on the next.
Training = adjusting billions of these weights until the output is accurate.
Simple idea. Insane at scale.
GPT-4 has ~1.8 trillion parameters. Claude 3 Opus has hundreds of billions.
All from the same basic concept: layered neurons with adjustable connections.
- 神经网络
所有AI模型的“大脑”。
神经网络就是一层叠一层的处理管道。
→ 数据进入输入层 → 穿过隐藏层 → 输出预测
每条连接都有一个“权重”——一个很小的数值,决定一个神经元对下一个的影响力。
训练就是调整这海量权重,直到输出准确。
原理简单,规模惊人。
GPT-4 约有 1.8 万亿参数,Claude 3 Opus 也有数千亿。
全出于同一个基本概念:层层堆叠、不断调参的神经元。
- Tokenization
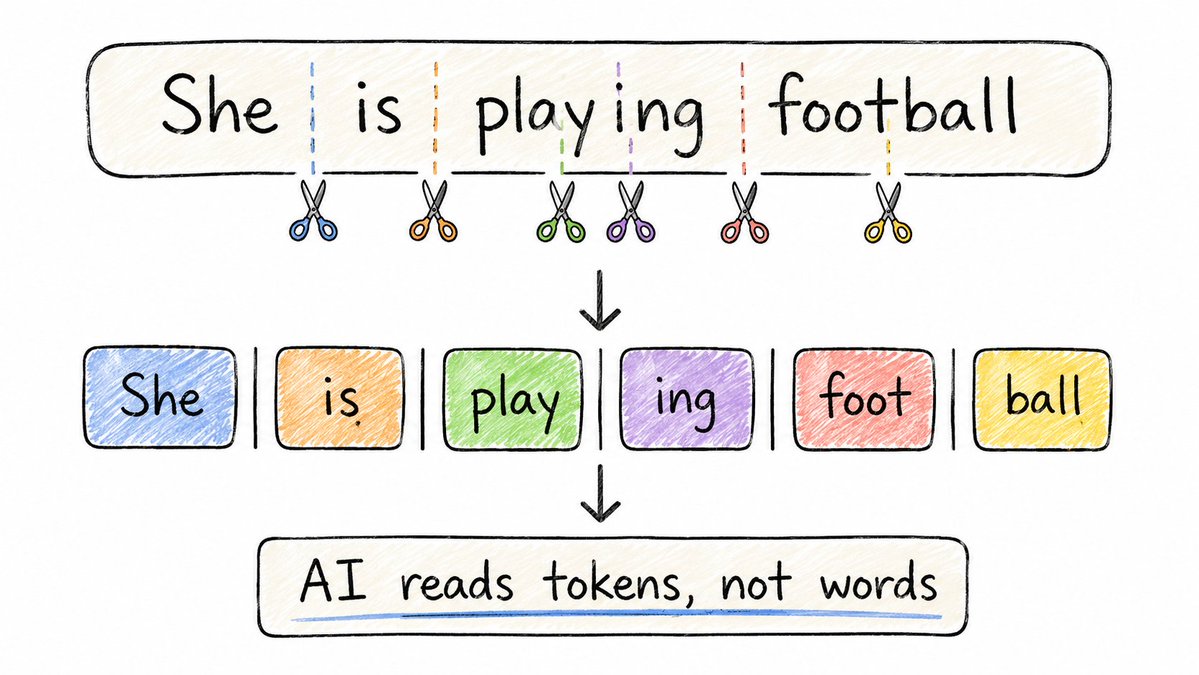
Before AI reads your text, it breaks it into pieces called tokens.
Not always full words.
"playing" → "play" + "ing" "ChatGPT" → "Chat" + "G" + "PT" "dog" → "dog" (stays whole)
Why not just use full words?
Language is messy. New words. Typos. Mixed languages. A fixed vocabulary of words would be impossibly large.
Tokens are reusable building blocks.
Even if the model has never seen a word, it can understand it by breaking it into familiar pieces.
Rough rule: 1 token ≈ 0.75 words.
1000 tokens ≈ 750 words.
- 分词与Token化
AI 读你的文字之前,会先把它切成小碎片,叫 token。
未必是完整的单词。
"playing" → "play" + "ing"
"ChatGPT" → "Chat" + "G" + "PT"
"dog" → "dog"(保持完整)
为什么不用完整的词?
语言太混乱了:新词、拼写错误、中英夹杂。固定词库会大到不现实。
token 是可复用的积木。
哪怕模型从来没见过某个词,也可以拆成熟悉的碎片去理解。
大约的经验:1 token ≈ 0.75 个英文词。
1000 token ≈ 750 个词。
- Embeddings

Once text is tokenized, each token becomes a number.
That number is an embedding — a vector that represents meaning.
Think of it as Google Maps for words.
→ "Doctor" and "Nurse" sit close together → "Doctor" and "Pizza" sit far apart → "King" minus "Man" plus "Woman" ≈ "Queen"
The model doesn't understand words like you do.
It understands distance and direction.
This is what powers: → Semantic search → Recommendations → RAG systems
Everything that "understands intent" uses embeddings under the hood.
- 嵌入(Embedding)
文本被分成 token 后,每个 token 会变成一个数字。
这个数字就是 embedding——一个表示含义的向量。
可以想象成文字版谷歌地图。
→ "医生" 和 "护士" 靠得很近
→ "医生" 和 "披萨" 离得很远
→ "国王" 减 "男人" 加 "女人" ≈ "王后"
模型不是你那样理解字词。
它理解的是距离和方向。
这就是以下功能的底层支撑:
→ 语义搜索
→ 推荐系统
→ RAG 系统
一切“理解意图”的东西,底层都在用 embedding。
- Attention

The word "Apple" means different things:
→ "I ate an Apple" → fruit → "I bought Apple stock" → company
Embeddings alone can't solve this.
Attention can.
Attention lets every word look at every other word in a sentence and decide what matters.
In "She bought shares in Apple": → "Apple" pays high attention to "shares" and "bought" → Model concludes: company, not fruit
Before attention, models read left-to-right. Slow. Limited.
After attention, models see the whole sentence at once.
This single idea unlocked modern AI.
- 注意力(Attention)
“Apple” 这个词可以指不同事物:
→ “我吃了个 Apple”→ 水果
→ “我买了 Apple 股票”→ 公司
光靠 embedding 解决不了这个。
注意力可以。
注意力让每个词都能看看句中的其他词,决定什么更重要。
在 “她买了 Apple 的股票” 中:
→ “Apple” 对 “股票” 和 “买了” 高度关注
→ 模型得出结论:是公司,不是水果
注意力出现之前,模型从左到右死板地读,又慢又窄。
有了注意力之后,模型能一眼看见整个句子。
就这一个点子,开启了现代 AI。
- Transformers

The architecture powering almost every AI model today.
Introduced in 2017 in a paper called "Attention Is All You Need."
The breakthrough: instead of reading text one word at a time, process everything in parallel using attention.
How it works: → Text → Tokens → Embeddings → Stacked attention layers → Output
Each layer refines understanding: → Early layers: grammar, basic structure → Middle layers: word relationships → Deep layers: complex reasoning
The result: massively faster training and far better outputs.
GPT. Claude. Gemini. Llama. Mistral.
All transformers.
If you understand this one architecture, you understand modern AI.
- Transformer
几乎今天所有 AI 模型的底层架构。
2017 年在论文《Attention Is All You Need》中提出。
突破在于:不再逐词阅读,而是用注意力并行处理一切。
工作流程:
→ 文本 → Token → Embedding → 层层注意力堆叠 → 输出
每一层都在理解上更精进一步:
→ 浅层:语法、基础结构
→ 中层:词间关系
→ 深层:复杂推理
结果是训练速度巨幅提升,输出质量也好了太多。
GPT、Claude、Gemini、Llama、Mistral……
全都是 transformer。
搞懂这一个架构,就搞懂了现代 AI。
- LLMs (Large Language Models)

An LLM is a transformer trained on a massive amount of text.
Books. Websites. Code. Wikipedia. Reddit.
Trillions of tokens.
The training task sounds too simple to be powerful:
→ Predict the next token.
That's it.
But when you repeat this across trillions of examples, something remarkable happens.
The model learns grammar. Then reasoning. Then how to write code, translate languages, solve math problems.
No one told it to do any of that.
It emerged from next-token prediction at scale.
"Large" = hundreds of billions of parameters. Training cost = millions of dollars.
ChatGPT, Claude, Gemini → all LLMs.
- 大语言模型(LLM)
LLM 就是在海量文本上训练出来的 transformer。
书籍、网站、代码、维基百科、Reddit……
数万亿 token。
训练任务听上去简单到不像能有多厉害:
→ 预测下一个 token。
就这。
可当你把这件事在如此规模上重复无数次,奇妙的事就发生了。
模型学会了语法,然后是推理,再然后是写代码、翻译语言、解数学题。
没人教它这些。
纯粹从下一个 token 预测中涌现出来。
“大”意味着数千亿参数,训练成本数百万美元。
ChatGPT、Claude、Gemini —— 全是 LLM。
- Context Window

Every AI model has a memory limit.
It's called the context window.
It's the maximum number of tokens the model can "see" at once — your message + its response + conversation history.
Early GPT: ~4,000 tokens. GPT-4: 128,000 tokens. Claude 3.5: 200,000 tokens. Gemini 1.5 Pro: 1,000,000 tokens.
Bigger window = more context = better answers.
But there's a catch.
Models don't read everything equally.
They focus on the beginning and end of the context.
The middle? Often ignored.
This is called the "Lost in the Middle" problem.
Big context window ≠ perfect memory.
Understanding this explains why AI sometimes "forgets" something you clearly mentioned.
- 上下文窗口
每个 AI 模型都有一个记忆上限。
就是上下文窗口。
即模型能一次性“看见”的最大 token 数——包括你的消息、它的回复和对话历史。
早期 GPT:约 4,000 token;GPT-4:128,000 token;Claude 3.5:200,000 token;Gemini 1.5 Pro:1,000,000 token。
窗口越大 → 能放进越多上下文 → 回答越好。
不过有个坑。
模型并不会一视同仁地阅读所有内容。
它更关注上下文开头和结尾的部分。
中间的?常常被忽略。
这就是所谓的“迷失在中段”问题。
大窗口 ≠ 完美记忆。
理解这一点,就能解释为什么 AI 有时会“忘记”你明确说过的东西。
- Temperature

When AI generates text, it doesn't just pick the most likely next word every time.
It has a dial called temperature.
→ Temperature = 0: always picks the safest, most predictable word → Temperature = 1: picks more creatively, more variety → Temperature = 2+: gets wild, sometimes incoherent
Low temperature → use for: code, facts, summaries High temperature → use for: brainstorming, creative writing, variations
Most tools set this for you automatically.
But understanding it explains why sometimes AI seems "boring" and sometimes it surprises you.
- 温度(Temperature)
AI 生成文本时,不是每次都选最可能的下一个词。
它有一个旋钮叫温度。
→ 温度 = 0:永远选最安全、最可预测的词
→ 温度 = 1:更富创意、更多样
→ 温度 = 2+:变得狂野,有时甚至语无伦次
低温度 → 适用于:代码、事实、总结
高温度 → 适用于:头脑风暴、创意写作、多样化尝试
大多数工具会自动帮你设好。
但理解这个,就能明白为什么 AI 有时显得“无聊”,有时又让你眼前一亮。
- Hallucination

AI lies with confidence.
Not on purpose. It literally cannot help it.
Here's why.
An LLM doesn't search for truth.
It predicts what the most probable next token is.
If a false statement looks like something that "should come next" based on training patterns, it generates it.
No verification. No lookup. Pure pattern matching.
So it will: → Cite a research paper that doesn't exist → Invent an API function that was never created → State a fake historical "fact" with complete confidence
This is called hallucination.
The fix: never trust AI output on facts without verifying.
Use RAG (concept 16) to ground it in real data.
- 幻觉(Hallucination)
AI 会自信满满地撒谎。
不是故意的,它压根控制不住。
原因如下。
LLM 并不追求事实。
它只是预测最可能的下一个 token。
如果基于训练模式,一个错误陈述看起来像是“应该紧接着出现的”,它就会生成出来。
没有查证,没有检索,纯粹模式匹配。
于是它就会:
→ 引用一篇不存在的论文
→ 编造一个从未有过的 API 函数
→ 言之凿凿地给出虚假历史“事实”
这就是幻觉。
应对之道:涉及事实时,永远别直接信任 AI 的输出,必须先验证。
用 RAG(见第16个概念)让回答扎根于真实数据。
- Prompt Engineering

The way you ask changes everything.
Same model. Same question. Wildly different results based on how you frame it.
Bad prompt: → "Explain APIs" → Gets: vague, surface-level answer
Good prompt: → "Explain how REST APIs handle authentication. Give a real example with code. Assume I'm a junior developer." → Gets: specific, structured, immediately useful
Prompt engineering is just clear communication.
The tricks that actually work: → Give context ("I'm building a SaaS for X") → Assign a role ("Act as a senior backend engineer") → Show examples ("Here's a format I like: ___") → Be specific about output ("Give me 5 options as a numbered list") → Break complex asks into steps
Prompt engineering isn't a hack.
It's the main way you communicate with the model.
- 提示工程(Prompt Engineering)
提问方式决定一切。
同一个模型,同一个问题,问法不同,结果天差地别。
糟糕的提示:
→ “解释一下 API”
→ 得到:模糊、浮泛的回答
优秀的提示:
→ “请解释 REST API 如何处理身份验证,配上真实代码示例,假设我是一位初级开发者。”
→ 得到:具体、结构化、马上能用
提示工程说白了就是清晰沟通。
真正有效的技巧:
→ 给上下文(“我正在做一个面向 X 的 SaaS”)
→ 指定角色(“扮演一位资深后端工程师”)
→ 给出示例(“我喜欢这种格式:___”)
→ 明确输出格式(“用编号列表给我 5 个选项”)
→ 把复杂要求拆成一步步
提示工程不是什么取巧黑魔法。
它就是你和模型互动的最主要方式。
- Transfer Learning

Training from scratch is expensive.
Insane amounts of data. Massive compute. Weeks of training.
Transfer learning solves this.
You take a model already trained on a huge general task and adapt it for something specific.
You're not starting from zero. You're building on top.
Think of it like this:
→ You already know how to ride a bike → Learning a motorcycle is much faster because of that → You transfer what you already know
This is how almost all AI products work today:
→ OpenAI trains massive foundation model → Companies fine-tune it for their specific use case → Saves millions in compute and months of training
No company trains from scratch anymore.
- 迁移学习
从头训练太烧钱。
海量数据、巨量算力、数周训练。
迁移学习解决了这个问题。
你拿一个已经在海量通用任务上训好的模型,把它适配到特定场景。
不是从零开始,而是在已有基础上继续建。
可以这样想:
→ 你已经会骑自行车
→ 因为有那个基础,学骑摩托车就快得多
→ 你把已经掌握的东西迁移了过来
如今几乎所有 AI 产品都是这么干的:
→ OpenAI 训练一个巨型基座模型
→ 公司再针对自身场景进行微调
→ 省下数百万计算成本,节省数月训练时间
再也没有公司从头开始训模型了。
- Fine-Tuning
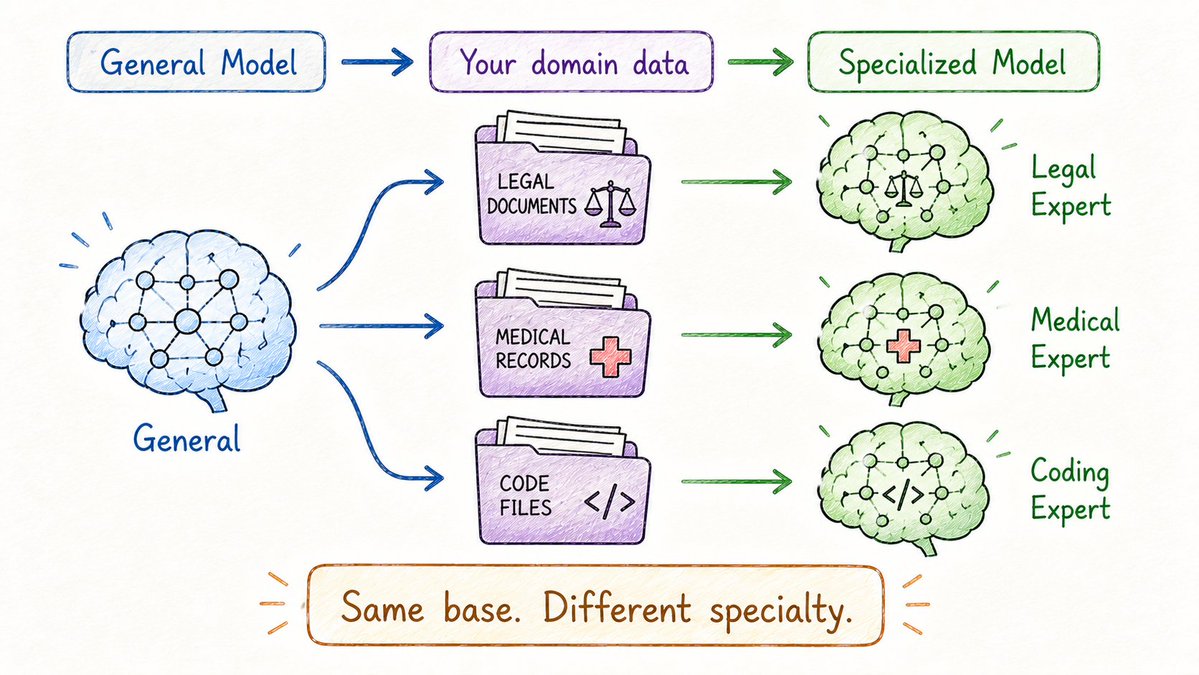
Transfer learning tells you the concept.
Fine-tuning is how you do it.
You take a pretrained model and continue training it on a smaller, focused dataset.
The model already speaks "language."
Now you're teaching it your specific domain.
Examples: → Medical model fine-tuned on clinical notes → Legal model fine-tuned on contracts → Coding model fine-tuned on GitHub
The result: a model that responds perfectly for your use case.
The cost: you need to update billions of parameters.
That requires serious compute — multiple GPUs, serious infrastructure.
(This is why LoRA, the next concept, matters so much.)
- 微调(Fine‑tuning)
迁移学习讲的是概念。
微调就是具体怎么做的办法。
你拿到一个预训练模型,在一个更小、更聚焦的数据集上继续训练。
模型已经会“说语言”了。
现在你在教它你那个特定领域。
例子:
→ 在临床笔记上微调的医疗模型
→ 在合同上微调的法律模型
→ 在 GitHub 上微调的编程模型
结果:模型能完美应对你的使用场景。
代价:你需要更新数以亿计的参数。
那需要真金白银的算力——多块 GPU、一套正儿八经的基础设施。
(这也是为什么下一个概念 LoRA 如此重要。)
- RLHF (Reinforcement Learning from Human Feedback)

Fine-tuning makes models specialized.
RLHF is what makes them feel helpful and safe.
Without it: the model just predicts text. Fluent, but not aligned.
With it: the model learns what humans actually prefer.
Here's how it works:
→ Show model a prompt → Model generates multiple responses → Humans rank the responses → Model learns to prefer what humans prefer
Repeat thousands of times.
The model builds a sense of "good answer": → Clear → Helpful → Honest → Safe
This is why ChatGPT and Claude feel like assistants — not random text generators.
Without RLHF, they'd still be impressive. But far less useful, less trustworthy, and much harder to control.
- RLHF(基于人类反馈的强化学习)
微调让模型变得专业。
RLHF 则让它们用起来感觉贴心且安全。
没有 RLHF:模型只是预测文本,流利但不“对齐”。
有了它:模型学到人类真正偏好什么。
过程是这样的:
→ 给模型一个提示
→ 模型生成多个回答
→ 人类对这些回答排序
→ 模型学会更偏好人类喜欢的
重复成千上万次。
模型就慢慢形成“好回答”的标准:
→ 清晰
→ 有帮助
→ 诚实
→ 安全
这就是为什么 ChatGPT 和 Claude 感觉像助手,而不是随机文本生成器。
没有 RLHF,它们依然惊艳,但会远没这么好用、这么可信,也更难控制。
- LoRA (Low-Rank Adaptation)

Fine-tuning is powerful but expensive.
Updating billions of parameters needs multiple GPUs and serious infrastructure.
LoRA solves this.
Instead of changing the whole model, LoRA:
→ Keeps the original model frozen → Adds tiny trainable layers on top → These layers are a fraction of the full model size
The insight: most fine-tuning changes are small.
You don't need to rewrite the whole model.
You just need small targeted adjustments.
Results: → Fine-tuning on a single consumer GPU: possible → Store one base model + swap different LoRA adapters: practical → Multiple specialized models without massive storage: done
LoRA is why open-source AI exploded.
Suddenly anyone could fine-tune powerful models on a laptop.
- LoRA(低秩适配)
微调虽强,但成本太高。
更新数十亿参数需要多块 GPU 和扎实的基础设施。
LoRA 解决了这一点。
不改变整个模型,而是:
→ 冻结原本的模型
→ 在上层增加极小的可训练层
→ 这些层的大小只是完整模型的一小部分
洞察在于:大多数微调的变化都很小。
你不需要重写整个模型。
只需要一点精准的小调整。
结果:
→ 单张消费级 GPU 就能微调
→ 存一个基座模型,换不同 LoRA 适配器即可
→ 无需海量存储就能拥有多个专精模型
LoRA 就是开源 AI 爆发的关键。
忽然之间,任何人都能在笔记本上微调强力模型。
- Quantization
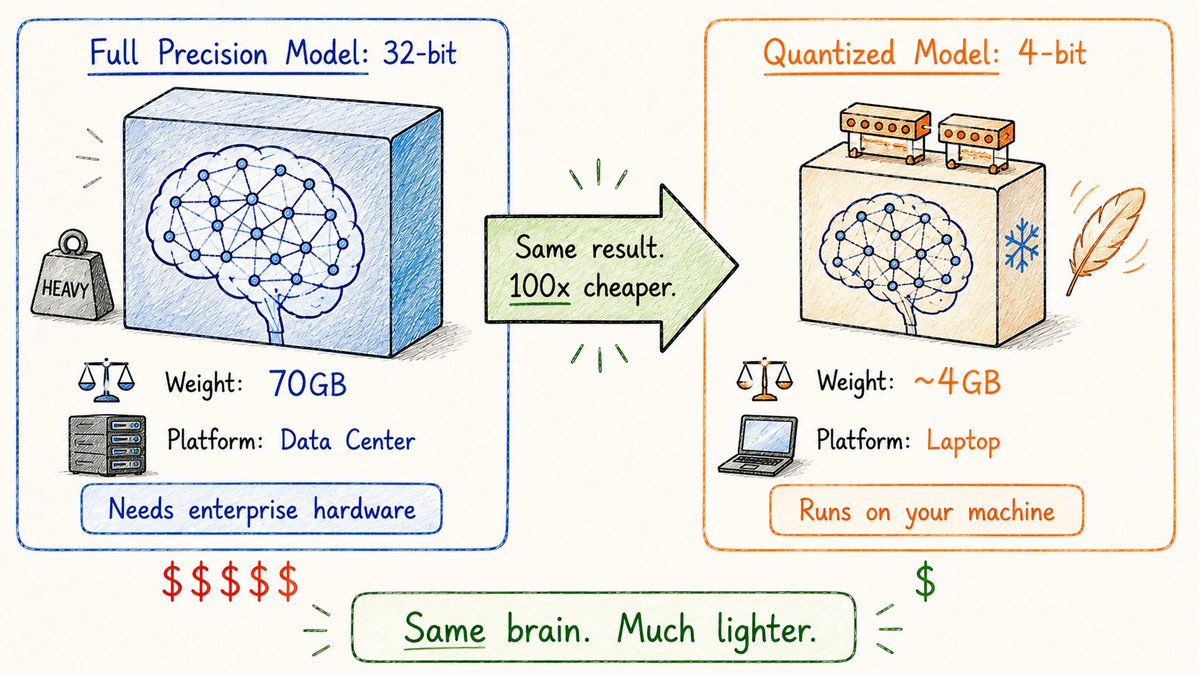
Models are getting huge.
Running them requires serious memory and compute.
Quantization makes them smaller and cheaper to run.
How: reduce the precision of each weight.
A weight stored in full precision uses 32 bits.
Quantized to 4-bit → 8x smaller.
Crazy thing: the quality drop is often surprisingly small.
This is why you can now: → Run LLaMA on a MacBook → Run Mistral locally on a consumer GPU → Use powerful models on a phone
Without quantization, large models would stay locked in data centers.
With quantization, they run on your machine.
- 量化
模型越来越大。
运行它们需要大把内存和算力。
量化让模型变小、运行更省钱。
做法:降低每个权重的精度。
全精度存储一个权重占 32 位。
量化到 4 位 → 缩小为原来的 1/8。
疯狂之处:质量下降往往出奇地小。
所以现在才能:
→ 在 MacBook 上跑 LLaMA
→ 用消费级 GPU 本地跑 Mistral
→ 在手机上用强力模型
没有量化,大模型就只能困在数据中心里。
有了量化,它们就能运行在你自己的机器上。
- RAG (Retrieval-Augmented Generation)

LLMs hallucinate because they answer from memory.
RAG fixes this by letting them look things up first.
How it works:
- User asks a question
- System searches a knowledge base for relevant documents
- Those documents are passed to the model as context
- Model answers using real information — not guesses Think of it like:
→ Closed-book exam (no RAG): answers from memory, often wrong → Open-book exam (RAG): checks the source, far more accurate
Why it's powerful: → No retraining when your data changes — just update the documents → Model always works with current, accurate information → Reduces hallucination dramatically
Every serious AI product uses RAG.
Customer support bots. Legal tools. Medical assistants. Internal knowledge bases.
- RAG(检索增强生成)
LLM 会产生幻觉,因为它们靠记忆回答。
RAG 修复这点,让它们先查一下再答。
工作流程:
- 用户提问
- 系统搜索知识库获取相关文档
- 这些文档作为上下文喂给模型
- 模型基于真实信息作答 —— 而不是瞎猜 可以这样理解:
→ 闭卷考试(无 RAG):凭记忆答,经常错
→ 开卷考试(有 RAG):查资料答,准确得多
之所以强大:
→ 数据变了不用重新训练 —— 更新文档即可
→ 模型始终基于最新、准确的信息工作
→ 大幅减少幻觉
所有正经的 AI 产品都在用 RAG。
客服机器人、法律工具、医疗助手、内部知识库……
- Vector Databases

RAG needs to find the right documents fast.
But how do you search millions of documents by meaning — not just keywords?
Vector databases.
Here's how they work:
- Every document gets converted into an embedding (a vector of numbers)
- These vectors get stored in the database
- When a user asks a question, the question also becomes a vector
- Database finds vectors closest to the question vector
- Returns most semantically similar documents Why this is better than keyword search:
→ "heart disease treatment" finds documents about "cardiac care protocols" → Even though the exact words don't match, the meaning does
Tools: Pinecone, Qdrant, Weaviate, pgvector
Vector databases are what makes AI systems "understand" — not just match strings.
- 向量数据库
RAG 需要快速找到正确的文档。
但如何在数百万文档中按含义搜索,而不是只靠关键词?
靠向量数据库。
原理是这样:
- 每个文档都被转成 embedding(一个数字向量)
- 这些向量存进数据库
- 用户提问时,问题也会变成一个向量
- 数据库找出与问题向量最接近的向量
- 返回语义最相似的文档 为什么比关键词搜索更好:
→ “心脏疾病治疗”会找到讲“心脏护理方案”的文档
→ 即便字面不匹配,含义却吻合
常见工具:Pinecone、Qdrant、Weaviate、pgvector
向量数据库就是让 AI 系统真正“理解”的关键——而不只是字符串匹配。
- AI Agents
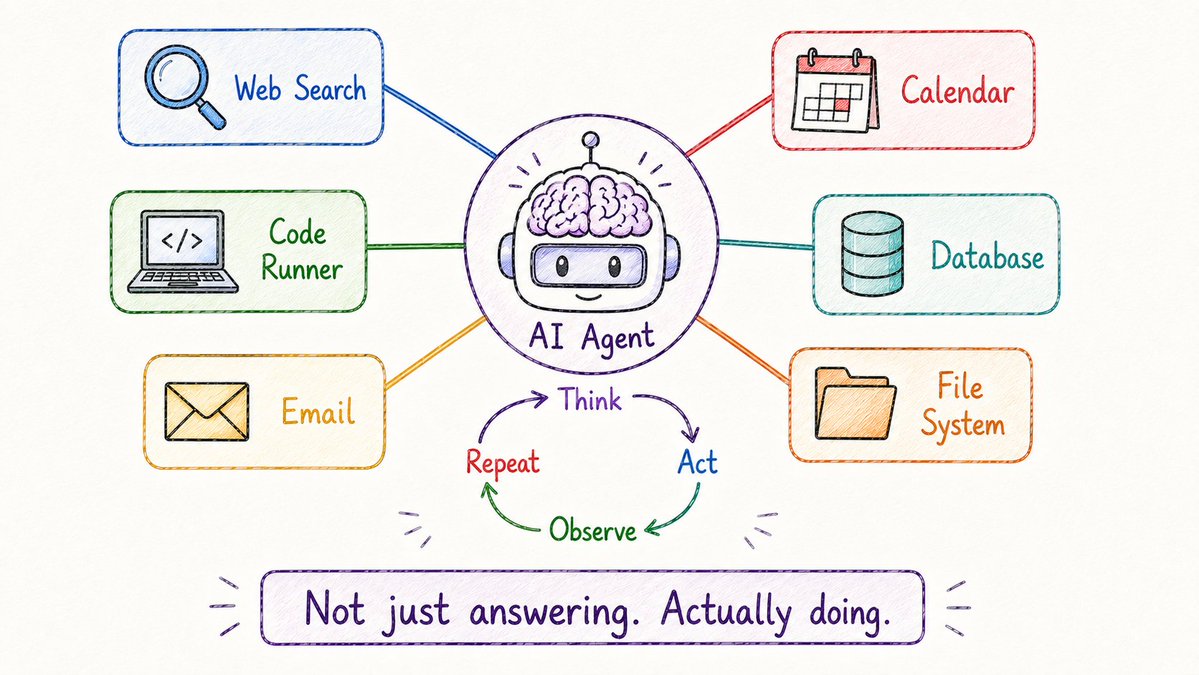
An LLM responds to messages.
An AI agent actually does things.
The difference:
→ LLM: you ask, it answers, done → Agent: you give a goal, it plans, takes actions, checks results, adjusts, repeats
The agent loop:
Think → Act → Observe → Repeat
Example: coding agent fixing a bug → Reads the issue → Explores the codebase → Identifies the problem → Writes a fix → Runs tests → Sees what failed → Adjusts the fix → Repeats until done
The model is the brain. Tools are the hands.
What tools can agents use? → Web search → Code execution → File system → APIs → Email / calendar → Databases
Agents are what turn AI from a chatbot into a coworker.
- AI 智能体(Agent)
LLM 止于回复消息。
AI Agent 是真正动手做事。
区别在哪:
→ LLM:你问,它答,结束
→ Agent:你给目标,它规划、行动、检查结果、调整、重复
Agent 循环:
思考 → 行动 → 观察 → 重复
例子:编程 Agent 修 bug
→ 读 issue
→ 浏览代码库
→ 定位问题
→ 写修复
→ 跑测试
→ 看到哪里失败
→ 调整修复
→ 重复直到修好
模型是大脑,工具是双手。
Agent 能用的工具有:
→ 网页搜索
→ 代码执行
→ 文件系统
→ API
→ 邮件/日历
→ 数据库
Agent 让 AI 从聊天机器人升级为同事。
- Chain of Thought (CoT)

Sometimes AI gets the wrong answer not because it's stupid.
But because it jumped to the answer too fast.
Chain of thought fixes this.
Instead of asking for the final answer directly:
→ "Solve: If a train travels 60mph for 2.5 hours, how far?"
You prompt it to think step by step:
→ "Solve step by step: Speed = 60mph. Time = 2.5 hours. Distance = Speed × Time = ?"
The model walks through reasoning: → Step 1: Identify the formula → Step 2: Plug in numbers → Step 3: Calculate
Far more reliable for math, logic, multi-step problems.
The insight: give the model room to think, not just react.
This is why prompts like "think step by step" or "reason through this carefully" actually work.
- 思维链(Chain of Thought)
有时 AI 答错,不是因为笨。
而是因为它直接跳到了答案,太快了。
思维链就解决这个。
不直接要最终答案,比如:
→ “求解:一辆列车以 60 英里/小时行驶 2.5 小时,走了多远?”
你改为让它一步步思考:
→ “逐步求解:速度 = 60 英里/小时,时间 = 2.5 小时,距离 = 速度 × 时间 = ?”
模型就会走过推理:
→ 第 1 步:确定公式
→ 第 2 步:代入数字
→ 第 3 步:算出结果
对数学、逻辑、多步问题可靠得多。
启示:给模型思考的空间,而不是只让它瞬间反应。
这就是为什么像“一步步思考”或“仔细推理一下”之类的提示真的管用。
- Diffusion Models

Everything so far has been about text.
Diffusion models explain how AI generates images.
The process is counterintuitive.
The model doesn't learn to draw.
It learns to destroy images.
Training: → Start with a real image → Add noise step by step until it's pure static → Train the model to reverse this — remove noise step by step
Generation: → Start with pure noise → Model removes noise step by step → Guided by your text prompt → Image emerges from randomness
The name comes from physics — particles diffusing randomly through a medium, like ink spreading in water.
Here, the model learns to reverse that diffusion.
Not just images anymore: → Video (Sora, Runway) → Audio → 3D content → Drug molecules
Diffusion models are how AI generates anything visual.
- 扩散模型
到现在为止全是关于文本的内容。
扩散模型解释的是 AI 怎么生成图像。
这个过程非常反直觉。
模型不是学画画。
它学的是破坏图像。
训练:
→ 从一张真实图像开始
→ 一步步加噪,直到变成纯雪花
→ 让模型学会逆转这个过程 —— 一步步去噪
生成:
→ 从纯噪点开始
→ 模型一步步去掉噪点
→ 同时被你的文字提示引导
→ 图像从随机中浮现
名字来自物理学——粒子在介质中随机扩散,就像墨水在水中散开。
在这里,模型学的是逆转这种扩散。
现在不止图像了:
→ 视频(Sora、Runway)
→ 音频
→ 3D 内容
→ 药物分子
扩散模型就是 AI 生成任何视觉内容的途径。
That's all 20.
Let me recap:
How AI Works:
→ 1. Neural Networks — layered pattern learning
→ 2. Tokenization — breaking text into pieces
→ 3. Embeddings — meaning as numbers
→ 4. Attention — context changes meaning
→ 5. Transformers — the architecture behind everything
How LLMs Work:
→ 6. LLMs — next token prediction at massive scale
→ 7. Context Window — memory limits and the middle problem
→ 8. Temperature — the creativity dial
→ 9. Hallucination — confident and wrong
→ 10. Prompt Engineering — how you communicate
How Models Improve:
→ 11. Transfer Learning — build on what exists
→ 12. Fine-Tuning — specialize a model
→ 13. RLHF — teach it to be helpful
→ 14. LoRA — fine-tuning without the cost
→ 15. Quantization — run big models on small machines
How Real Systems Are Built:
→ 16. RAG — look it up first, then answer
→ 17. Vector Databases — search by meaning
→ 18. AI Agents — from answering to doing
→ 19. Chain of Thought — give it room to think
→ 20. Diffusion Models — noise to image
You now understand how AI actually works.
Most people who use AI every day don't.
That gap is your edge.
If this was useful:
→ Repost to share it with your network → Follow @sairahul1 for more breakdowns like this → Bookmark this for reference
I write about AI, building products, and systems that work while you sleep.
以上就是全部 20 个概念。
快速回顾一遍:
AI 如何工作:
→ 1. 神经网络 —— 层层模式学习
→ 2. Token化 —— 将文本切成小碎片
→ 3. Embedding —— 用数字代表含义
→ 4. 注意力 —— 上下文改变词义
→ 5. Transformer —— 支撑一切的基础架构
LLM 如何工作:
→ 6. 大语言模型 —— 海量规模下的下一 token 预测
→ 7. 上下文窗口 —— 记忆上限与中间迷失问题
→ 8. 温度 —— 创意旋钮
→ 9. 幻觉 —— 自信但错误
→ 10. 提示工程 —— 你怎么与模型沟通
模型如何改进:
→ 11. 迁移学习 —— 在已有基础上构建
→ 12. 微调 —— 把模型变专精
→ 13. RLHF —— 教它变有用
→ 14. LoRA —— 不烧钱的微调
→ 15. 量化 —— 让小机器跑大模型
真实系统如何构建:
→ 16. RAG —— 先查一下再回答
→ 17. 向量数据库 —— 按含义搜索
→ 18. AI Agent —— 从作答到动手
→ 19. 思维链 —— 给它思考空间
→ 20. 扩散模型 —— 从噪点到图像
现在,你真懂 AI 是怎么工作的了。
而每天用 AI 的大多数人并不懂。
这个差距就是你的优势。
如果这篇对你有用:
→ 转发分享给你的圈子
→ 关注 @sairahul1 获取更多类似拆解
→ 收藏以备查阅
我写关于 AI、产品构建,以及让你睡着后也能自动运转的系统。