Build a Self-Improving Agent System with Claude Fable 5 in 14 Steps
A practical guide based on Anthropic engineering posts and experiments detailing how to build a self-improving agent system around Claude Fable 5. It argues most users underutilize the Mythos-class model, treating it like a bigger Sonnet 4.6. The architecture layers primitives (model, sub-agents, worktrees), orchestration (/goal and Outcomes loops, Dynamic Workflows, Routines for cloud execution), memory (state files and compounding Skills), and self-improvement (vision self-checks, eval loops, rule distillation). Key tactics include using an independent verifier sub-agent instead of self-critique, ensuring parallel safety with git worktrees, running multi-day tasks on cloud infrastructure, and following a 5-stage memory progression from failure documentation to general rule consultation. Designed for engineers building compound systems rather than prompting for minutes.
Most people are using Claude Fable 5 like Sonnet 4.6 with a bigger context window. They prompt it. It works for 5 minutes. They close the tab.
9 out of 10 users have never run an agent system that compounds - where every run leaves the next run smarter, every state file accumulates, every skill sharpens.
Fable 5 was built to run for days. You're using it for minutes. This is the 14-step roadmap to build the self-improving system Fable 5 was designed for.
大多数人把 Claude Fable 5 当作上下文窗口更大的 Sonnet 4.6 在用。发一条 prompt,跑五分钟,关掉标签页。
十个人里有九个从未运行过一个能产生复利效应的 agent 系统——每次运行都让下一次更聪明,状态文件不断累积,技能持续精进。
Fable 5 生来就是为了跑几天的。你只用了它几分钟。这里有一份 14 步路线图,教你构建 Fable 5 真正适配的自改进系统。
Claude Fable 5 launched June 9, 2026 - the first publicly available Mythos-class model, the tier Anthropic put one rung above Opus.

This is the 14-step roadmap to build the self-improving system Fable 5 was designed for - sourced from Anthropic engineering posts, the team's public experiments, and verified against the launch documentation as of June 2026.
Three tiers: what Fable 5 actually unlocks, the three primitives that make it compound (loops, dynamic workflows, routines), and the self-improvement layer that turns it into a system.
Claude Fable 5 于 2026 年 6 月 9 日发布,是首个公开可用的 Mythos 级模型——这是 Anthropic 在 Opus 之上新设的一个等级。
这份 14 步路线图,基于 Anthropic 工程团队的博文、公开实验以及截至 2026 年 6 月的发布文档编写,目标是构建 Fable 5 真正适配的自改进系统。
路线图分三层:Fable 5 真正解锁了什么;让它产生复利效应的三个基础组件(loops / 循环,Dynamic Workflows / 动态工作流,Routines / 云上常驻任务);以及将这一切转化为系统的自改进层。
 14 steps. 3 tiers. Stop prompting. Start building a system that compounds.
14 steps. 3 tiers. Stop prompting. Start building a system that compounds.
14 步。3 层。别再只是发 prompt 了,开始构建一个能产生复利效应的系统。
Claude Fable 5 launched June 9, 2026 as the first publicly available Mythos-class model - the tier Anthropic introduced one rung above Opus.
Mythos Preview shipped in April through Project Glasswing to a handful of critical-infrastructure partners; Fable 5 is the version Anthropic considered safe for general release, with built-in safety classifiers that decline requests in high-risk areas.
Mythos 5 (without those classifiers) remains Glasswing-only.
What Fable 5 actually does that previous Claude models couldn't sustain, from Anthropic's launch documentation:
- Days-long autonomous sessions. Run inside an agent harness like Claude Code or Claude Managed Agents (CMA), Fable 5 can work for days - planning across stages, delegating to sub-agents, and checking its own work.
- Self-verification built in. Writes its own tests to check its work. Uses vision to check outputs against goals. Distills lessons into general rules. Tests its own assumptions.
- Most ambitious code work. Large migrations, complex implementations, multi-day autonomous coding sessions. The headline use case Anthropic puts forward is "hand off large projects and review completed deliverables."
- Multi-stage knowledge work. Deep research and analysis to deliverables ready for review - with minimal oversight. The pricing matches the tier: $10 per million input tokens, $50 per million output tokens, with the existing 90% input token discount for prompt caching.
Available on Claude API, AWS, Amazon Bedrock, Vertex AI, Microsoft Foundry, and the consumption-based Enterprise plan. This is not a subscription model. Heavy use earns its own bill.
Claude Fable 5 于 2026 年 6 月 9 日发布,是首个公开可用的 Mythos 级模型——这是 Anthropic 在 Opus 之上新设的等级。
Mythos Preview 版本在 4 月通过“玻璃翼计划”开放给了少数关键基础设施合作伙伴;而 Fable 5 是 Anthropic 认为可以安全公开发布的版本,内建了安全分类器,在高风险领域会拒绝请求。
Mythos 5(去掉了这些分类器)仍然仅限玻璃翼计划使用。
根据 Anthropic 的发布文档,Fable 5 实际能做到的、且此前 Claude 模型无法持续做到的事包括:
- 持续数天的自主会话。在 Claude Code 或 Claude Managed Agents (CMA) 这类 agent 运行框架里,Fable 5 可以连续工作数天——跨阶段规划、委派子 agent、检查自身工作。
- 内建自我验证。会自己写测试来检查工作,用视觉能力把输出与目标对比,将经验提炼为通用规则,并检验自己的假设。
- 更复杂的代码任务。大规模迁移、复杂实现、持续数天的自主编码会话。Anthropic 给出的核心用例是:“交付大型项目,然后审核已完成的成果。”
- 多阶段知识工作。从深度研究和分析,到生成可供审核的交付物——只需很少的监督。
定价与等级匹配:每百万输入 token 10 美元,每百万输出 token 50 美元,现有 prompt 缓存仍享受 90% 的输入 token 折扣。
可在 Claude API、AWS、Amazon Bedrock、Vertex AI、Microsoft Foundry 以及按量付费的企业计划上使用。这不是订阅制,大量使用对应产生实际账单。
The phrase "self-improving agent system" gets thrown around carelessly. The version that's real and the version that's hype are very different things, and the gap is worth understanding before you build anything.

- Self-learning - the agent updates its own weights based on what it learns. Fable 5 does not do this. No publicly available model does this in production. Recursive self-improvement (RSI) is the long-term direction Anthropic itself warned about in May 2026, not the capability shipping today.
- Self-improving - the system around the agent compounds. Each session writes lessons to memory. Skills sharpen as edge cases get added. State files accumulate verified facts. Eval loops refine prompts and rubrics. The model stays the same; the environment it runs in gets sharper.
Self-improvement, in this sense, is a property of the system you build. Fable 5 has the raw capability - long context, sub-agent delegation, vision self-check, days-long stamina - that turns the environment-feedback loop into something that actually compounds run over run.
Anthropic's engineering team puts it directly: "Rather than directly prompting and steering Fable 5, it's often better to design loops that let the model self-correct in response to environment feedback (e.g., /goal or Outcomes) and manage its own context (e.g., via memory)."
“自改进 agent 系统”这个词常被随意使用。但真实的版本和被吹上天的版本差别巨大,在动手构建之前,值得先搞清楚其中的差距。
- 自学习:agent 根据学到的内容更新自身权重。Fable 5 做不到,目前所有公开模型在真实产品中都做不到。递归自我改进(RSI)是 Anthropic 在 2026 年 5 月自己发出过警示的远期方向,不是现在交付的能力。
- 自改进:模型周围的系统产生复利。每次会话把经验写进记忆,技能随着 edge case 的增加而精进,状态文件不断累积已验证的事实,评估循环持续优化 prompt 和评分标准。模型不变,但它运行的环境在变强。
在这个意义上,自改进是你所构建系统的一项能力。Fable 5 拥有原始能力——大上下文窗口、子 agent 委派、视觉自我检查、持续数天的续航能力——这些能力将“环境反馈循环”转化为每次运行都能真正累积成果的系统。
Anthropic 工程师团队说得直白:“与其直接向 Fable 5 发 prompt 并操控它,更好的方式是设计一些循环,让模型能根据环境反馈(例如 /goal 或 Outcomes)自我纠正,并自行管理上下文(例如通过记忆)。”
Figure 1 at the top of this article shows the architecture in one diagram. Read it from the bottom up - that's the order the system gets built, and the order the leverage compounds.
- Layer 1 · Primitives. Fable 5 itself, sub-agents, worktrees, the tools the agent reaches for. Raw capability with no system around it yet. This is what most people use today.
- Layer 2 · Orchestration. /goal and Outcomes for self-correcting loops. Dynamic Workflows for complex multi-step orchestration. Routines for laptop-off cloud runs. This is what turns the primitives into a workflow.
- Layer 3 · Memory. State files, Skills, Knowledge Bases, lessons written down. Memory is what makes tomorrow's session resume instead of restart.
- Layer 4 · Self-improvement. Vision self-checks, eval loops, rule distillation. The agent grades its own output, refines the Skill that produced it, writes the lesson back to memory. The loop closes.
The reason this architecture compounds: every output from layer 1 flows up through layer 4, where it gets graded, distilled, and written back to layer 3. Tomorrow's run at layer 1 inherits the sharpened memory and refined Skills from yesterday. The model is stateless; the system around it isn't.
本文开头的图 1 在一张图中展示了整个架构。建议从下往上看——那是构建系统的顺序,也是复利效应逐步放大的顺序。
- 第一层 · 基础组件。Fable 5 本身、子 agent、worktree、agent 可调用的工具。只是原始能力,还没有围绕它构建系统。这是大多数人目前的用法。
- 第二层 · 编排。/goal 和 Outcomes 用于自我纠正循环,Dynamic Workflows 用于复杂的多步编排,Routines 用于笔记本合上后仍在云上运行。这一层把基础组件变成工作流。
- 第三层 · 记忆。状态文件、Skills、知识库,以及记录下的经验教训。记忆让明天的会话能够接续,而不是从头再来。
- 第四层 · 自改进。视觉自我检查、评估循环、规则提炼。agent 给自己的输出打分,精进产生该输出的 Skill,把经验写回记忆。循环闭合。
这套架构会产生复利的原因:第一层的每个输出都会向上流到第四层,经评估、提炼,写回第三层。明天在第一层运行时,就会继承昨天更精练的记忆和更成熟的 Skill。模型本身是无状态的,围绕它的系统不是。
Fable 5 costs ~5× what Opus 4.8 does per token. Not every step in a self-improving system needs the top tier. The teams running this in production route by task complexity, not by default:

- Fable 5 for the heavy-lift orchestrator role: planning across days, delegating to sub-agents, checking work with vision, distilling rules from accumulated evidence. Use Fable 5 where the "days at a time" capability earns its pricing.
- Opus 4.8 for hard-but-bounded subtasks the orchestrator delegates: architecture decisions, complex debugging, deep code reviews. Also the explicit fallback for any request Fable 5's classifiers block (cyber, bio, chem, distillation).
- Sonnet 4.6 for high-volume worker tasks: lint passes, simple refactors, test scaffolding, doc updates. The bulk of fan-out work runs here.
- Haiku 4.5 for grader sub-agents and cheap classifiers. Independent context window, low cost - ideal for the verifier role Anthropic explicitly recommends.
The cost pattern that makes a self-improving system economical, used by teams running this in production: orchestrator on Fable 5, workers on Sonnet 4.6, graders on Haiku 4.5, fallback to Opus 4.8 on classifier blocks. Same pattern Anthropic engineers use internally.
Fable 5 的每 token 成本大约是 Opus 4.8 的 5 倍。自改进系统中并非每个环节都需要顶级模型。已经在生产环境中这样跑的团队,是按任务复杂度来路由,而不是默认全部用最强模型:
- Fable 5 承担重负载的编排者角色:跨天规划、委派子 agent、通过视觉检查工作、从累积证据中提炼规则。在“连续跑几天”的能力能值回票价的地方,才用 Fable 5。
- Opus 4.8 处理编排者委派的、困难但边界明确的子任务:架构决策、复杂 debug、深度代码审查。同时也是 Fable 5 内置分类器拒绝请求(如网络安全、生物、化学、蒸馏等领域)时的显式回退方案。
- Sonnet 4.6 处理大批量 worker 级任务:lint 扫描、简单重构、测试脚手架、文档更新。多数发散型并行的任务都在这一层跑。
- Haiku 4.5 用于评分子 agent 和轻量分类器。独立上下文窗口,成本低廉,Anthropic 明确推荐它做验证者角色。
生产团队使用的、能让自改进系统保持经济可行的成本配置模式是:Fable 5 做编排、Sonnet 4.6 做 worker、Haiku 4.5 做评分、遇到分类器拦截时回退到 Opus 4.8。Anthropic 工程师自己内部也这么做。
The Anthropic Claude Code team publishes two near-identical primitives for goal-driven loops: one in each harness.
They share the same shape: an independent grader checks the work, a not-met verdict starts the next iteration, the loop exits when the grader passes.
The implementations differ in surface details that matter for which you use.

The decision rule between them is short:
- Use /goal in Claude Code when the work happens at your machine and you want a quick, in-session loop with a measurable end state. Best for hands-on coding, debugging flaky tests, refining a single file. Plain text goal, model grader, in-terminal feedback.
- Use Outcomes in CMA when the work needs to run for hours or days on Anthropic-hosted infrastructure with a sandbox, GPUs, or a controlled environment. Best for ML training, long-running migrations, multi-day research. File-based rubric with gradable criteria, sub-agent grader, hard max_iterations bound.
Anthropic 的 Claude Code 团队发布了两个几乎相同、用于目标驱动循环的基础组件,分别对应两种运行框架。
它们结构相同:一个独立评分器检查工作,判断为“未完成”则启动下一轮迭代,评分通过则循环退出。
两者的实现细节不同,影响你该选哪一个。
选择规则很简单:
- 在 Claude Code 中用 /goal,适合工作在你本机进行、想要一个快速的会话内循环,且有一个可衡量的终点。最适合动手编码、调试不可靠的测试、打磨单个文件。纯文本目标描述,由模型评分,在终端反馈结果。
- 在 CMA 中用 Outcomes,适合工作需要在 Anthropic 托管基础设施(含沙箱、GPU 或受控环境)上跑数小时甚至数天。最适合机器学习训练、长时间迁移、跨天研究。基于文件、含有可评分标准的评分表,由子 agent 评分,有明确的 max_iterations 上限。
两者共通的核心结构:写代码的 agent 不讲评代码的 agent。我们会在第 6 步深入讨论为什么这一点至关重要。
Anthropic engineer Prithvi Rajasekaran wrote a piece on the engineering blog showing models have a hard time self-critiquing their own outputs. The Claude Code team confirmed this empirically with Fable 5:
"We've found that a verifier sub-agent tends to outperform self-critique with Fable 5"
The mechanism is structural, not about "trying harder." A model evaluating its own output sees its own reasoning trail and prefers conclusions consistent with what it already wrote.
A separate model evaluating the same output sees only the artifact and the rubric. The verifier has no skin in the maker's game.

What the chart actually shows, beyond the headline numbers:
- Fable 5 made larger structural changes - TRAIN_SEQ_LEN=2048 train+eval (−0.0179), overlapped sliding-window eval (−0.0207), int6 QAT + int6 expo (−0.0163). Each is an architecture-level move, not a constant tweak.
- Fable 5 pushed through a quantization regression to its biggest win - instead of reverting after a failed experiment, it continued investigating.
- Opus 4.7's first experiment (QK_GAIN_INIT=5.0) produced a small win. Nearly everything that followed used the same template: adjust a scalar, measure, keep if positive. The shape is safer, not better.
The takeaway for system design: Fable 5 with an independent verifier explores larger hypothesis spaces and recovers from negative intermediate results. Without the verifier, the same model has nothing forcing it past the first "good enough."
Anthropic 工程师 Prithvi Rajasekaran 曾在工程博客撰文指出,模型很难对自己的输出进行自我批评。Claude Code 团队用 Fable 5 做实验,也验证了这一点:
“我们发现,在 Fable 5 上,用一个验证子 agent 的效果往往优于自我批评。”
其原理是结构性的,与“更努力”无关。一个模型在评估自己的输出时,会看到自己的推理路径,倾向于选择与自己之前结论一致的结果。
而一个独立模型在评估同一输出时,只会看到产出物和评分标准。验证者在制造者的博弈中毫无利益牵扯。
除了标题数据之外,这张图表还揭示了一些深层次信息:
- Fable 5 做了更大的结构变化——TRAIN_SEQ_LEN=2048 训练+评估(−0.0179)、重叠滑窗评估(−0.0207)、int6 QAT + int6 指数(−0.0163)。每一步都是架构级的变动,不是微调一个常量。
- Fable 5 在一次量化回归实验中顶住了压力,最终取得了最大收益——并没有在实验失败后立即回退,而是持续深挖。
- Opus 4.7 的第一个实验(QK_GAIN_INIT=5.0)取得了小幅提升,之后几乎所有尝试都是同一模板:调一个标量,测量,如果是正向结果就保留。行为模式更安全,但并不更优。
对系统设计者的关键启示:Fable 5 配备独立验证者时,会探索更大的假设空间,并能从负面的中间结果中恢复。没有验证者,同一位模型就没有任何机制能推动它跨过第一个“够好了”的阶段。
Dynamic Workflows shipped in Claude Code on May 28, 2026.
The idea: Claude writes its own JavaScript harness on the fly - a file with agent(), parallel(), and pipeline() primitives, plus standard JS to process the data flowing between them. The harness is custom-built for the task, not generic.
For self-improving systems with Fable 5, three of the six documented Dynamic Workflow patterns earn their place:
- Fan-out-and-synthesize. Split the work into N independent pieces, run an agent on each in parallel, synthesize results. Best when each step benefits from its own clean context window - e.g., evaluating each rule in a Skill against historical examples.
- Adversarial verification. For each maker agent, spawn an independent verifier with no exposure to the maker's reasoning. The structural fix for self-preferential bias from step 6, applied per task.
- Loop until done. Loop spawning agents until a stop condition is met - no new findings, no more errors in the logs, theory verified. Pair with /goal to set a hard completion requirement. The two patterns that don't typically appear in self-improving systems but are worth knowing: classify-and-act (route the task to the right model based on a classifier) and tournament (pairwise comparison for taste-based ranking). The first is useful for model routing (step 4). The second is rare in coding loops but useful for design or naming tasks.
Dynamic Workflows 于 2026 年 5 月 28 日在 Claude Code 中发布。
核心思路:让 Claude 动态编写用于控制任务流的 JavaScript“骨架文件”——该文件内含有 agent()、parallel() 和 pipeline() 等基础组件,辅以处理数据流的常规 JavaScript 逻辑。骨架是按需为当前任务定制的,不是通用模板。
在基于 Fable 5 的自改进系统中,文档记录的六种动态工作流模式中有三种尤其值得采用:
- 发散-综合。把任务拆分为 N 个独立部分,每个放在独立的 agent 上并行执行,最后汇总结果。适合每一步能从各自干净的上下文窗口中获益的场景——例如,把 Skill 中的每条规则分别与历史案例做对比评估。
- 对抗验证。为每个制造者 agent 派生一个独立验证者,让它完全看不到制造者的推理过程。这就是第 6 步中描述的那一结构性问题——自我偏好偏差的结构性解法,按任务实施。
- 循环直到完成。不断派生 agent 直到触发停止条件——“没有新发现”“日志中没有错误”“理论得到验证”。配合 /goal 即可设定一个硬性完成要求。
另外两种虽不常出现在自改进系统中、但值得了解的模式是:分类-行动(通过一个分类器把任务路由到合适模型)和锦标赛(通过两两比较,用于主观排序的场景)。第一种在第 4 步的模型路由时很有用,第二种在编码循环中罕见,但在设计或命名任务中很有价值。
The moment a self-improving system spawns more than one agent, files start colliding. Two agents writing the same file is the same problem as two engineers committing to the same lines without talking first.
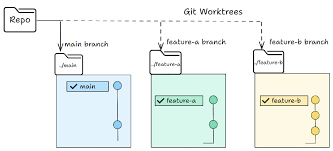
A git worktree fixes it - a separate working directory on its own branch sharing the same repo history, so one agent's edits literally cannot touch the other's checkout.
For self-improving systems where Fable 5 spawns sub-agents to verify or specialize, worktrees are non-optional:
- Maker writes in worktree A. Verifier reads in worktree B (or runs against the worktree A checkout with read-only filesystem). No risk the verifier's exploration touches the maker's state.
- Parallel structural experiments. If Fable 5 explores multiple architecture changes (like in Parameter Golf), each experiment runs in its own worktree. The orchestrator collects results from all of them; the best one merges.
- Days-long runs with checkpoints. Each major phase can be a separate worktree. A failed phase doesn't poison the rest.
In Claude Code, worktrees are exposed three ways: git worktree directly, a --worktree flag to open a session in its own checkout, and an isolation: worktree setting on subagents so each helper gets a fresh checkout that cleans itself up after the session ends.
一旦自改进系统派生出多个 agent,文件冲突就开始了。两个 agent 写同一个文件,与两个工程师不打招呼就往同一行代码上提交修改面临的问题一样。
Git worktree 可以解决这个问题——创建一个独立的本地工作目录,挂在独立分支上,与主工程共享版本历史。这样一位 agent 的编辑完全不会影响到其他人的工作区。
在 Fable 5 派生子 agent 来验证或专门完成特定任务的系统中,worktree 是必选项,而非可选项:
- 制造者在 worktree A 里写作。验证者在 worktree B 里读取(或者以只读文件系统挂载 worktree A,再进行操作)。验证者的探索绝不会污染制造者的状态。
- 并行结构实验。如果 Fable 5 要探索多种架构变更(类似 Parameter Golf 实验),每个实验跑在自己的 worktree 里。编排者从所有 worktree 中收集结果,只合并最好的那一个。
- 带检查点的跨天运行。每个主要阶段可以是一个独立 worktree。一个失败的阶段不会污染后续阶段。
在 Claude Code 中,worktree 有三种暴露方式:直接使用 git worktree 命令;通过 --worktree 标志位在一个独立工作区打开会话;以及在子 agent 上设置 isolation: worktree,让每个辅助 agent 得到独立的工作区,并在会话结束后自动清理。
Routines launched April 14, 2026 in research preview. They're saved Claude Code configurations - a prompt, repositories, connectors, permissions - that run on Anthropic-managed cloud infrastructure on a trigger.
Your laptop can be off. The run still happens.

For Fable 5 specifically, Routines are the trigger layer that earns the model's capability. Anthropic measures Fable 5's "days at a time" on Claude Managed Agents - a hosted sandbox with full tools and no local machine constraint.
The Parameter Golf experiment ran for up to 8 hours on 8×H100 GPUs. That class of run doesn't happen on your laptop.
The three Routine trigger types, mapped to self-improvement patterns:
- Schedule triggers - the morning briefing pattern. Daily at 7am: re-run yesterday's eval suite, distill any new failure modes into Skills, write the digest to Slack. The agent gets sharper while you sleep.
- API triggers - the "fire on event" pattern. CI fails → fire a Routine to investigate. Sentry alert → fire a Routine to triage. The self-improving system reacts to your real environment, not a fixed schedule.
- GitHub event triggers - the "learn from real work" pattern. On PR open, run an evaluation against the latest Skills. On merge, write any new patterns the PR introduced back to the Skill. Repository state and Skill state stay in sync.
Routines 于 2026 年 4 月 14 日以研究预览版发布。它们是保存好的 Claude Code 配置——包括 prompt、代码仓库、连接器、权限等——由触发器驱动,在 Anthropic 托管的云基础设施上运行。
你的笔记本可以合上,运行依然会继续。
对 Fable 5 来说,Routines 就是让模型能力真正兑现的那一层触发器。Anthropic 对“持续数天”的宣传,是基于在 Claude Managed Agents(一个托管式沙箱、拥有完整工具且不受限于本地机器)上测量的结果。
Parameter Golf 实验在 8 块 H100 GPU 上最长跑了 8 个小时。这类运行的规模不可能在你笔记本上完成。
三种 Routine 触发器类型与自改进模式的对应关系:
- 定时触发器——“早晨简报”模式。每天早上 7 点:重新运行昨天的评估套件,把任何新的失败模式提炼到 Skill 中,将摘要推送到 Slack。agent 在你睡觉时变得更敏锐。
- API 触发器——“事件响应”模式。CI 挂了 → 启动 Routine 去调查。Sentry 报警 → 启动 Routine 去分类排查。这套自改进系统能对你的真实环境做出响应,而非只按固定周期运行。
- GitHub 事件触发器——“在实践中学习”模式。PR 打开时,用最新 Skill 运行评估。合并后,把 PR 引入的新模式写回 Skill。仓库状态与 Skill 状态保持同步。
> /schedule daily at 7am, use Fable 5 in CMA
Goal: Re-run yesterday's eval suite against the latest skills.
Any test that newly passes → distill the pattern into the skill.
Any test that newly fails → investigate, document in STATE.md.
Post the digest to #engineering. /goal don't stop until digest is
posted and STATE.md is updated.
▲ Claude
Creating routine: nightly-eval-compounding
- model: claude-fable-5
- harness: claude managed agent (sandbox)
- trigger: schedule (0 7 * * *)
- grader: independent Haiku sub-agent (Outcomes)
✓ Active. First run tomorrow 07:00 local. Skill set will compound.
> /schedule daily at 7am, use Fable 5 in CMA
Goal: Re-run yesterday's eval suite against the latest skills.
Any test that newly passes → distill the pattern into the skill.
Any test that newly fails → investigate, document in STATE.md.
Post the digest to #engineering. /goal don't stop until digest is
posted and STATE.md is updated.
▲ Claude
Creating routine: nightly-eval-compounding
- model: claude-fable-5
- harness: claude managed agent (sandbox)
- trigger: schedule (0 7 * * *)
- grader: independent Haiku sub-agent (Outcomes)
✓ Active. First run tomorrow 07:00 local. Skill set will compound.
The single most useful framing for what "agent memory" means in practice comes from the Anthropic team's Continual Learning Bench 1.0 experiment. Effective use of memory requires a progression of five stages. Each stage is a structural move; each model exits the progression at a different point.
-
- Fail - the agent gets something wrong and documents the failure with enough detail to be useful later.
-
- Investigate — before moving on, the agent figures out why the failure happened.
-
- Verify - the agent turns the diagnosis into a checked fact, not a guess.
-
- Distill - the agent turns the verification into a general rule that applies beyond the specific case.
-
- Consult - on the next task, the agent reads the rule instead of re-deriving the fact from scratch.

The measured difference between models on a SQL exploration task from the Continual Learning Bench, each model with memory provided:
- Sonnet 4.6 exits at step 1. Its memory store is a list of failure notes and open guesses ("maybe prc instead of prc_usd?"). It rarely consults prior notes. Memory exists but doesn't compound.
- Opus 4.7 exits at step 3. It creates a schema reference with uncertainty flagged ("possibly prc in cents? Verify."). Verification coverage runs 7–33% (median ~17%) of questions.
- Fable 5 tends to complete the progression. In its strongest runs, verification coverage reaches 73% (22 of 30), and it distills learnings into general rules that help with future tasks.
关于“agent 记忆”在实践中最实用的模型,来自 Anthropic 团队在 Continual Learning Bench 1.0 实验中的总结。有效使用记忆需要经过五阶递进。每一阶都是结构性的动作,每个模型会在不同位置停下。
-
- 失败——agent 在某事上搞错了,并以足够详细的方式记录了该失败,供日后参考。
-
- 调查——在继续之前,agent 搞清楚失败为什么会发生。
-
- 验证——agent 把诊断变成经过检验的事实,而非猜测。
-
- 提炼——agent 把验证结果转化为一条通用规则,超出原有案例范围。
-
- 调阅——下一项任务中,agent 直接查阅规则,而不是从头重新推理。
在 Continual Learning Bench 的 SQL 探索任务中,各模型均配给了记忆,实测差异如下:
- Sonnet 4.6 到第 1 阶就停了。它的记忆存储就是一串失败备注和开放的猜测(“或许用 prc 而不是 prc_usd?”)。它很少调阅之前的笔记。记忆存在,但不产生复利。
- Opus 4.7 到第 3 阶停下。它会创建一个 schema 参考文件,并标注不确定性(“prc 可能是以分为单位?需要验证。”)。验证覆盖率为 7%–33%(中位值约 17%)。
- Fable 5 倾向于走完整个递进过程。在表现最好的几次运行中,验证覆盖率达到了 73%(30 个问题中验证了 22 个),并能将学到的内容提炼成对后续任务有帮助的通用规则。
The 5-stage progression is the mental model. The state file is where the model writes each stage's output. For Fable 5 running in Claude Managed Agents, memory is a mounted filesystem that survives between sessions; in Claude Code locally, a markdown file or a Linear board does the same job.
The structure of a state file that actually supports the 5-stage progression:
# Project memory · trading-platform
## Verified facts # stage 3 — stop guessing about these
- prc is in dollars, not cents. Verified via SELECT MIN(prc), MAX(prc) FROM trades.
- user_id matches auth_users.uid via JOIN, not auth_users.id. Confirmed 2026-06-09.
- Test database uses Stripe sandbox keys; production uses real keys via env.
## General rules # stage 4 — consult before re-deriving
- When querying time-bucketed metrics, always include timezone (default UTC mismatches).
- Auth middleware order matters: rate_limit -> jwt -> rbac. Reversing causes 401s.
- For migrations, never use ALTER on tables >1M rows without batching.
## Open failures (investigate next session) # stage 1 → 2
- 2026-06-09: tests/e2e/checkout flakes ~1 in 50 runs. Hypothesis: webhook race.
Reproduction steps in debug/checkout-flake.md.
## Lessons learned # stage 4 distillations
- PowerShell hits TLS 1.2 issue on Windows CI runners. Always shell out to bash.
- Stripe webhook tests require STRIPE_WEBHOOK_SECRET. Skip with clear message if missing.
## Last session # stage 5 — resume, don't restart
2026-06-10 03:30 UTC · 7 failures classified, 3 fixes drafted (claude/fix-*), 4 escalated.
Next: verify the auth middleware fix in claude/fix-rate-limit-order against production load.
The file has five sections matching the five stages. Verified facts is stage 3 output - things the agent stopped guessing about. General rules is stage 4 - distilled rules that apply beyond the specific case. Open failures is stages 1–2 work in progress. Lessons learned is more stage 4 output.
Last session is the resume pointer for stage 5.
Two operational rules that decide whether this file actually compounds or just grows:
- Write before walking away. Every Fable 5 session ends by updating STATE.md - what was tried, what passed, what failed, what new rules survived. If the session doesn't finish with a write, the next one restarts from zero.
- Read at session start. Every new session begins by reading STATE.md and the most relevant Skills. The Continual Learning Bench data shows that without this, Sonnet-class memory behavior shows up even in Fable 5.
五阶递进是心智模型,状态文件则是模型记录每一阶产出的地方。在 Claude Managed Agents 里,Fable 5 的记忆是一个持久化挂载的文件系统,跨会话留存;在本地 Claude Code 中,一份 Markdown 文件或一个 Linear 看板也能起到同样的作用。
一个真正支撑五阶递进的状态文件结构长这样:
# Project memory · trading-platform
## Verified facts # stage 3 — stop guessing about these
- prc is in dollars, not cents. Verified via SELECT MIN(prc), MAX(prc) FROM trades.
- user_id matches auth_users.uid via JOIN, not auth_users.id. Confirmed 2026-06-09.
- Test database uses Stripe sandbox keys; production uses real keys via env.
## General rules # stage 4 — consult before re-deriving
- When querying time-bucketed metrics, always include timezone (default UTC mismatches).
- Auth middleware order matters: rate_limit -> jwt -> rbac. Reversing causes 401s.
- For migrations, never use ALTER on tables >1M rows without batching.
## Open failures (investigate next session) # stage 1 → 2
- 2026-06-09: tests/e2e/checkout flakes ~1 in 50 runs. Hypothesis: webhook race.
Reproduction steps in debug/checkout-flake.md.
## Lessons learned # stage 4 distillations
- PowerShell hits TLS 1.2 issue on Windows CI runners. Always shell out to bash.
- Stripe webhook tests require STRIPE_WEBHOOK_SECRET. Skip with clear message if missing.
## Last session # stage 5 — resume, don't restart
2026-06-10 03:30 UTC · 7 failures classified, 3 fixes drafted (claude/fix-*), 4 escalated.
Next: verify the auth middleware fix in claude/fix-rate-limit-order against production load.
文件中的五个部分分别对应五个阶段。“已验证事实”是第三阶的产出——agent 不再需要猜测的东西。“通用规则”是第四阶的产出——提炼出的、适用范围超出具体案例的规则。“未关闭的失败”是第一、二阶正在进行的工作。“经验教训”同样是第四阶的产出。
“上一次会话”则是第五阶的接续指针。
决定这份文件是产生复利还是仅仅在膨胀的两条操作纪律:
STATE.md is for project memory. Skills are for procedural memory - the "how to do this kind of thing" that should apply across projects.
The compounding pattern: after any non-trivial failure, write the lesson into the Skill itself. The Skill gets sharper every time the system runs.

A Skill that's been compounding for two weeks looks different from a fresh one. New sections appear: known failure modes, rules that came out of post-mortems, anti-patterns observed in production.
The Skill is no longer a static set of instructions; it's an accumulating record of what the team has actually learned.
STATE.md 是项目级记忆,Skill 则是过程性记忆——那种“如何做这类事情”、可以跨项目复用的知识。
复利模式:任何不平凡的失败发生之后,就把教训写进 Skill 本身。系统每多运行一次,Skill 就更锐利一分。
一个经过两周持续累积的 Skill,和刚建好的 Skill 看起来截然不同。会出现全新的章节:已知的失败模式、复盘后产生的规则、生产环境中观察到的反模式等等。
Skill 不再是静态的指令集,而是团队实际学习到的经验在持续累积的记录的。
---
name: ci-triage
description: Classify CI failures, draft fixes for easy ones, escalate the rest.
Trigger on workflow_run.failure or on the morning triage routine.
---
# CI triage skill
## Classification rules
- env: missing secret, wrong env var. # escalate to human, never auto-fix
- flake: passes on retry without code change. # retry once, then file
- bug: deterministic failure tied to recent commit. # draft fix
- dependency: tied to version bump. # draft rollback
- infra: timeout, OOM, runner issue. # escalate
## Known failure modes # added by the loop over 14 days
- webhook-race: e2e checkout flakes when Stripe webhook arrives mid-test.
Fix: add 2s settle delay in tests/utils/webhook.ts.
- tls-handshake: Windows runners fail TLS 1.2 in PowerShell. Use bash.
- db-migration: ALTER on trades table >1M rows times out at 30s. Batch in 10k chunks.
## Anti-patterns (do NOT do) # added after real incidents
- Never disable a failing test to make CI green. File it instead.
- Never modify .github/workflows/ without human approval.
- Never touch src/payments/ or src/billing/ without security review.
## State
Update STATE.md after each run with classifications, fixes drafted, escalations.
## Eval suite # step 13 — the loop verifies the skill
Run against eval/ci-triage-cases.jsonl weekly. Any newly-failing case →
add to known failure modes after Outcomes verifier confirms.
The compounding contract: every confirmed lesson goes into a Skill, not just STATE.md. STATE.md is project-scoped and dies with the project. Skills live in ~/.claude/skills/ and travel with you.
Two weeks of disciplined writing produces a Skill that materially outperforms whatever Fable 5 would derive from scratch on a fresh project.
---
name: ci-triage
description: Classify CI failures, draft fixes for easy ones, escalate the rest.
Trigger on workflow_run.failure or on the morning triage routine.
---
# CI triage skill
## Classification rules
- env: missing secret, wrong env var. # escalate to human, never auto-fix
- flake: passes on retry without code change. # retry once, then file
- bug: deterministic failure tied to recent commit. # draft fix
- dependency: tied to version bump. # draft rollback
- infra: timeout, OOM, runner issue. # escalate
## Known failure modes # added by the loop over 14 days
- webhook-race: e2e checkout flakes when Stripe webhook arrives mid-test.
Fix: add 2s settle delay in tests/utils/webhook.ts.
- tls-handshake: Windows runners fail TLS 1.2 in PowerShell. Use bash.
- db-migration: ALTER on trades table >1M rows times out at 30s. Batch in 10k chunks.
## Anti-patterns (do NOT do) # added after real incidents
- Never disable a failing test to make CI green. File it instead.
- Never modify .github/workflows/ without human approval.
- Never touch src/payments/ or src/billing/ without security review.
## State
Update STATE.md after each run with classifications, fixes drafted, escalations.
## Eval suite # step 13 — the loop verifies the skill
Run against eval/ci-triage-cases.jsonl weekly. Any newly-failing case →
add to known failure modes after Outcomes verifier confirms.
复利契约是:每一个被确认的教训都要写进 Skill,而不只是 STATE.md。STATE.md 是项目级范围的,项目结束就失效了。Skill 存放在 ~/.claude/skills/,会跟着你走。
只需要两周,严格按此规律来写,产出的 Skill 就能大幅优于 Fable 5 在一个全新项目中从头推导出的结果。
One of the headline capabilities Anthropic ships with Fable 5 is "uses vision to check outputs against goals." This sounds abstract until you see what it actually replaces: the human eyeballing a screenshot to confirm the UI looks right.
Fable 5 does that step itself, in the loop, before declaring done.
The pattern in production:
- Maker sub-agent writes the UI code. Renders the result to a screenshot.
- Verifier sub-agent reads the screenshot with vision, compares it against the goal description, against design tokens in the project Skill, and against the previous screenshot from STATE.md.
- Verdict goes back to the loop. Match → mark task complete. Mismatch → describe the gap, hand back to maker with a structured diff.
This pattern is what Anthropic measured in the Parameter Golf experiment under the same harness: Fable 5 looked at training charts (visual artifact) and decided whether the curve matched the criterion.
No human in the loop reading the chart. The verifier read the chart.
Anthropic 在 Fable 5 中交付的杀手级能力之一是“用视觉能力来把输出与目标进行对比检查”。这句话听起来很抽象,直到你看到它具体取代了什么:原来是需要一个人盯着截图确认 UI 对不对。
Fable 5 在循环中自己完成这一步,然后才宣布“完成”。
在生产中的模式长这样:
- 制造者子 agent 写 UI 代码,把结果渲染成一张截图。
- 验证者子 agent 用视觉能力读取截图,与目标描述对比,与项目 Skill 中的设计 token 对比,与 STATE.md 中的上一版截图对比。
- 对比结果回传给循环。匹配 → 标记任务完成。不匹配 → 描述差异,将结构化 diff 返回给制造者。
这正是 Anthropic 在 Parameter Golf 实验中使用相同框架所测量的模式:Fable 5 盯着训练曲线图(视觉产物),判断曲线是否符合标准。
过程中没有人去读图,是验证者在读图。
The last step is the one most easily skipped on day one and most expensive to learn the hard way.
Fable 5 ships with built-in safety classifiers that decline to respond in specific high-risk domains - cybersecurity vulnerability research, biology, chemistry, and model distillation. In those domains, Anthropic falls Fable 5 back to Claude Opus 4.8 automatically. This is documented; it's not a bug.
What this means for a self-improving system that runs autonomously:
- If your system touches security tooling (SAST scans, exploit research, penetration testing logic, even some classes of code review), expect classifier blocks. Architect for the fallback: route those tasks to Opus 4.8 explicitly, or surface the block to a human reviewer.
- Same for biology, chemistry, and distillation domains. The classifier is broad. A scientific computing workflow might trigger it; a code review of crypto primitives might trigger it.
- Design your Skills to surface the fallback gracefully. A Skill should know which kinds of tasks it produces that may hit the classifier and document the expected behavior. A loop that silently fails on a classifier block looks identical to a loop that fails on a real error — until you debug it.
- Audit the system card. Fable 5's 319-page system card documents the classifier's scope. The launch generated controversy in mid-June 2026 because some downgrade behaviors were discovered buried in the document. Read it before deploying to production.
The general design principle: treat the safety boundary as a known fallback, not as a failure mode. A self-improving system that ships with explicit handling of the boundary stays robust as the classifier evolves. A system that ignores it produces silent regressions when Anthropic updates the policy.
最后一步是很多人第一天最容易跳过的,但也是后续用惨重代价才能学会的教训。
Fable 5 发布时就内建了安全分类器,会在特定高风险领域拒绝回复——网络安全漏洞研究、生物、化学以及模型蒸馏。在这些领域,Anthropic 约定 Fable 5 会自动回退到 Claude Opus 4.8。这是写明的设计,不是 bug。
对自主运行的自改进系统意味着什么?
- 如果你的系统涉及安全工具(SAST 扫描、漏洞利用研究、渗透测试逻辑,甚至若干类代码审查),要做好碰到分类器拦截的准备。架构上必须设计好回退:将这些任务显式路由给 Opus 4.8,或将拦截情况上报给人类审核员。
- 生物、化学和蒸馏领域同理。分类器的覆盖范围很宽。一个科学计算工作流可能触发它;一份针对密码学原语的代码审查也可能触发它。
- 要设计好 Skill,让它能优雅地暴露回退行为。一份 Skill 应该知道它可能产出哪些会被分类器拦截的任务类型,并记录下预期行为。因分类器拦截而静默失败的一次循环,与因真实错误而失败的循环,表现完全一样——直到你去调试时才会发现问题。
- 去审查系统卡文档。Fable 5 长达 319 页的系统卡文档记载了分类器的边界。2026 年 6 月中旬这项发布曾引发争议,就是因为文档中埋藏着一些降级行为的信息。上生产环境之前必须读完。
总体设计原则:把安全边界当作一个已知的兜底策略,而不是一种故障模式。一个显式处理了边界的自改进系统,在分类器演进时依然能保持稳定。一个忽略了它的系统,在 Anthropic 更新政策时就会产生静默的衰退。
The mistakes that keep Fable 5 at 10% of its potential
- Using Fable 5 like Sonnet 4.6 with more context. A 5-minute prompt-and-close session burns Mythos-tier pricing for no compound effect.
- Self-critique instead of an independent verifier. The maker grades its own homework. Anthropic measured the difference; the team explicitly documents the verifier sub-agent pattern.
- No STATE.md. Every session restarts from zero. The Continual Learning Bench data shows this is where 70%+ of Fable 5's memory advantage disappears.
- Skills that never get written to. A static Skill is fine; a Skill that doesn't accumulate lessons after real failures is wasted scaffolding.
- Fable 5 on tasks Sonnet 4.6 would handle. Doc updates, simple refactors, lint fixes. Route by complexity; reserve Fable 5 for the orchestrator role.
- Running long sessions on a laptop. Days-long capability requires cloud infrastructure (CMA or Routines). A closed laptop kills the session.
- Ignoring the Mythos safety boundary. Classifier blocks on cyber/bio/chem produce silent regressions. Architect for the fallback explicitly.
- No vision-verify on visual tasks. UI, dashboards, design fidelity — checking these with text-only verifiers misses the failure mode that matters.
- Skipping /goal or Outcomes. Without an objective stop condition checked by an independent grader, loops stop at "handled enough" instead of done.
- No retention policy review. Sensitive data through a Fable 5 routine without checking the 30-day / 2-year terms creates compliance issues silently.
让 Fable 5 只能发挥 10% 潜力的常见错误
- 把 Fable 5 当作上下文更大的 Sonnet 4.6。5 分钟 prompt 然后关掉的方式,花着 Mythos 级的钱,没有任何复利效果。
- 用自我批评替代独立验证者。制造者自己给自己的作业打分。Anthropic 实测过差异,团队也明确写明了验证子 agent 模式。
- 没有 STATE.md。每次会话都从零开始。Continual Learning Bench 的数据表明,超过 70% 的 Fable 5 记忆优势就是这样消失的。
- 从不往 Skill 里写东西。静态 Skill 还行,但经历过失败却不累积教训的 Skill 等于白搭。
- 在 Sonnet 4.6 完全够用的任务上跑 Fable 5。文档更新、简单重构、lint 修复。按复杂度路由;Fable 5 要留给编排者角色。
- 在笔记本上跑长会话。“持续数天”的能力需要云基础设施(CMA 或 Routines)。合上笔记本就杀掉了会话。
- 无视 Mythos 安全边界。对网络/生物/化学领域的分类器拦截会产生静默衰退。必须显式设计兜底方案。
- 视觉类任务不用视觉验证。UI、仪表盘、设计还原度——只用纯文本验证会漏掉真正关键的失败模式。
- 跳过 /goal 或 Outcomes。没有由独立评分器检查的客观完成条件,循环会在“差不多搞定了”的地方停下,而不是真的“完成了”。
- 不审查数据保存政策。敏感数据通过 Fable 5 Routine 运行时,不检查 30 天/2 年的合规性要求,会悄悄埋下合规隐患。
Fable 5 isn't a faster chat tool. It's the substrate for a system that compounds.
The first publicly available Mythos-class model didn't ship to be prompted faster. It shipped to be the orchestrator of a self-improving system you build around it.
The capability headlines - days-long sessions, sub-agent delegation, vision self-check, accumulated memory - only earn their pricing if the system around the model is doing its job.
The Anthropic team's own experiments make the gap visible. Parameter Golf: Fable 5 with an independent verifier explored larger architectural changes and pushed through negative intermediate results to land ~6× more improvement than Opus 4.7.
Continual Learning Bench: Fable 5 with memory completed the full 5-stage progression with 73% verification coverage, against Opus 4.7's 17%. The model is the same in both halves of every comparison. The system around it is what changed.
Pick one layer of the compound stack you weren't doing - probably the verifier sub-agent (step 6), the state file (step 11), or vision-verify (step 13) - and add it tomorrow. Then the next.
Self-improvement is a property of the system, not the model. Build the system.
Fable 5 不是一个更快的聊天工具。它是一个可以产生复利效应的系统的底层引擎。
首个公开的 Mythos 级模型,不是为了让你更快发 prompt 而发布的。它是为了成为你所构建的自改进系统的编排者而发布的。
那些能力卖点——持续数天的会话、子 agent 委派、视觉自查、累积记忆——只有模型周围的系统尽责运转时,才能值回票价。
Anthropic 团队的实验清晰展示了这套差距。Parameter Golf 实验中:Fable 5 配备独立验证者,探索了更大的架构变更空间,扛过了负面的途中结果,最终提升幅度大约是 Opus 4.7 的 6 倍。
Continual Learning Bench 实验中:Fable 5 配好记忆,完整走完了五阶递进,验证覆盖率达 73%,而 Opus 4.7 只有 17%。每次对比中模型本身没有变,改变的是它周围的系统。
选一层你之前没做的复利堆栈——很可能是验证子 agent(第 6 步)、状态文件(第 11 步)、或者视觉自我验证(第 13 步)——明天就把它加上。然后再加下一层。
自改进是系统的能力,不是模型的能力。去构建系统吧。