Claude Fable 5 and Claude Mythos 5
Anthropic launched Claude Fable 5, its most capable publicly released model, rated Mythos-class. It achieves state-of-the-art on nearly all benchmarks, especially on long, complex tasks in software engineering, knowledge work, and vision. To mitigate misuse risks in cybersecurity and biology, Fable 5 ships with conservative safety classifiers that fall back to Opus 4.8 for sensitive queries, triggering in under 5% of sessions. Claude Mythos 5, the same model with safeguards lifted, is available to cyberdefenders and certain biologists. New 30-day business data retention is mandated for Mythos-class models. The post includes results from Stripe, Cognition, and internal protein design and genomics experiments. Pricing is $10/M input tokens and $50/M output tokens.
Today we're launching Claude Fable 5: a Mythos-class1 model that we've made safe for general use.
今天我们正式发布 Claude Fable 5:这是一款 Mythos 级¹模型,我们已为其添加了安全措施,面向普通用户开放。
Fable 5's capabilities exceed those of any model we've ever made generally available. It is state-of-the-art on nearly all tested benchmarks of AI capability, showing exceptional performance in software engineering, knowledge work, vision, scientific research, and many other areas. The longer and more complex the task, the larger Fable 5's lead over our other models.
Fable 5 的能力超越了我们以往发布的所有模型。在几乎所有经过测试的 AI 能力基准测试中,它都达到了业界领先水平,在软件工程、知识工作、视觉理解、科学研究等多个领域展现出卓越表现。任务越长越复杂,Fable 5 相比于我们其他模型的优势就越明显。
Releasing a model this capable comes with risks. Without safeguards, Fable 5's capabilities in areas like cybersecurity could be misused to cause serious damage. We've therefore launched the model with safeguards that mean queries on some topics will instead receive a response from our next-most-capable model, Claude Opus 4.8. To release the model both safely and quickly, we've tuned these safeguards conservatively—they'll sometimes catch harmless requests, though they trigger, on average, in less than 5% of sessions. With more capable models arriving in the coming months, we're working to improve our safeguards and reduce false positives as quickly as we can.
发布如此强大的模型必然伴随风险。如果没有安全护栏,Fable 5 在网络安全等领域的能力可能被滥用,造成严重损害。因此,我们在发布时加入了安全机制:涉及某些主题的查询将由我们次强的模型 Claude Opus 4.8 来响应。为了安全且快速地发布,我们将安全机制调得比较保守——它们有时会拦截无害请求,不过平均来看,受影响会话的比例低于 5%。随着后续更强大的模型陆续到来,我们正努力改进安全机制,尽快降低误报率。
For a small group of cyberdefenders and infrastructure providers, we're also launching Claude Mythos 5. It's the same underlying model as Fable 5, but with the safeguards lifted in some areas.2 Mythos 5 will initially be deployed through Project Glasswing, in collaboration with the US government, as an upgrade to Claude Mythos Preview. It has the strongest cybersecurity capabilities of any model in the world. Soon, we intend to expand access to Mythos 5 through a broader trusted access program.
针对一小批网络防御者和基础设施提供商,我们还同步推出了 Claude Mythos 5。它的底层模型与 Fable 5 相同,但在某些领域移除了安全护栏²。Mythos 5 将首先通过 Project Glasswing 项目部署,与美国政府合作,作为 Claude Mythos Preview 的升级版。它的网络安全能力是全球所有模型中最强的。我们计划尽快通过更广泛的信任访问计划来扩大 Mythos 5 的使用范围。
The capabilities of models like Fable 5 and Mythos 5 have the potential to do profound good for the world. We've seen the beginnings of this in Project Glasswing, where the models have helped cyber defenders secure critically important software. We've also seen it in life sciences research, where the models are positing novel hypotheses and speeding up the development of new therapeutics.
Fable 5 和 Mythos 5 这类模型的能力有望为世界带来深远福祉。在 Project Glasswing 项目中我们已经看到了初步成果:模型帮助网络防御者保护了至关重要的软件。在生命科学研究中,模型也在提出新颖假说、加速新疗法的开发进程。
Fable 5 and Mythos 5 are being offered at $10 per million input tokens and $50 per million output tokens—less than half the price of Claude Mythos Preview. Today's joint launch is another step towards our goal of bringing advanced AI capabilities to as many users as possible, as quickly and as safely as we can.
Fable 5 和 Mythos 5 的定价为每百万输入 token 10 美元、每百万输出 token 50 美元,不到 Claude Mythos Preview 价格的一半。今天的联合发布是我们朝着目标迈出的又一步——我们将安全、尽快地将先进 AI 能力带给尽可能多的用户。
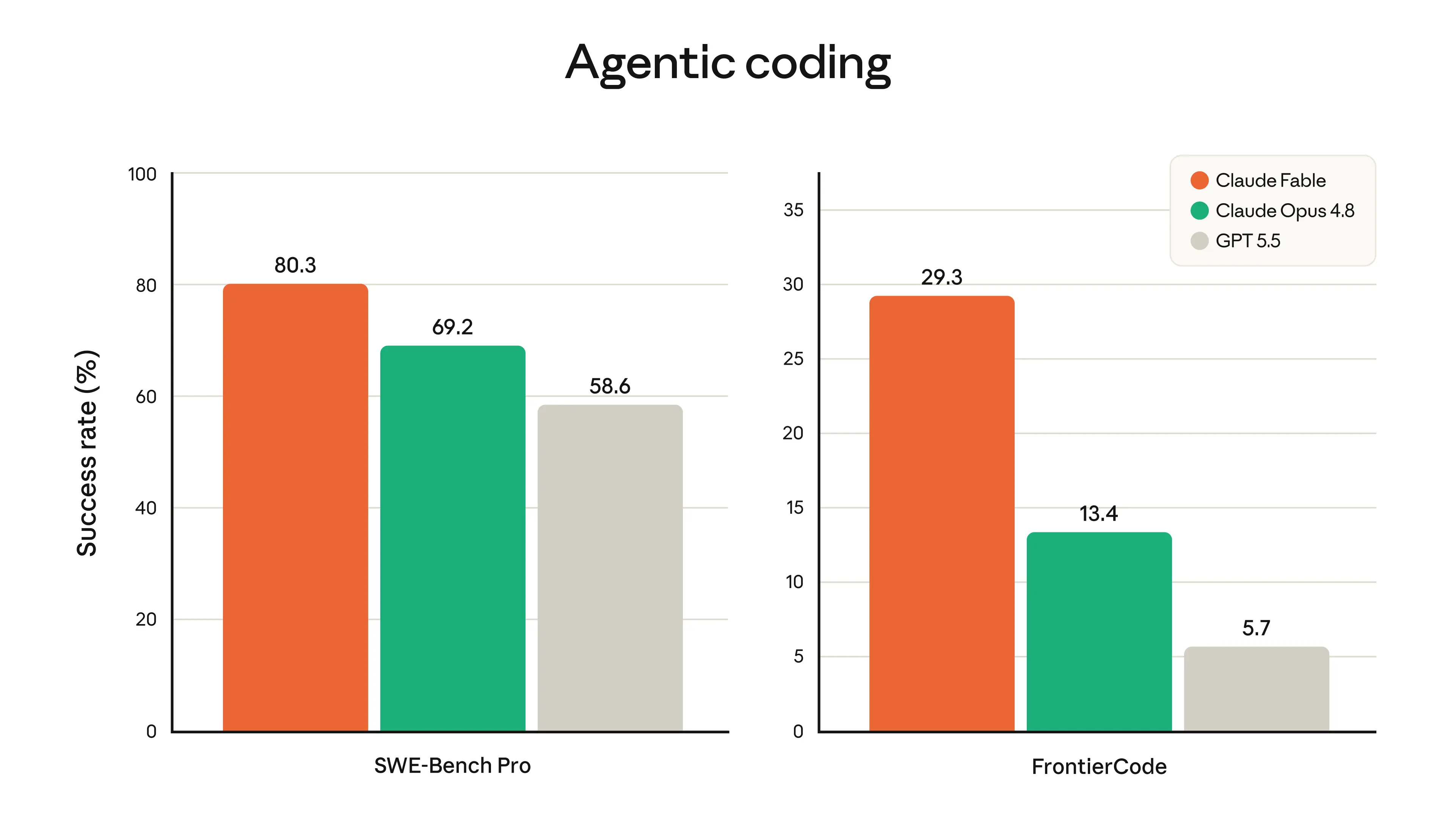
The table below compares the capabilities of Fable 5 and Mythos 5 to other leading models.
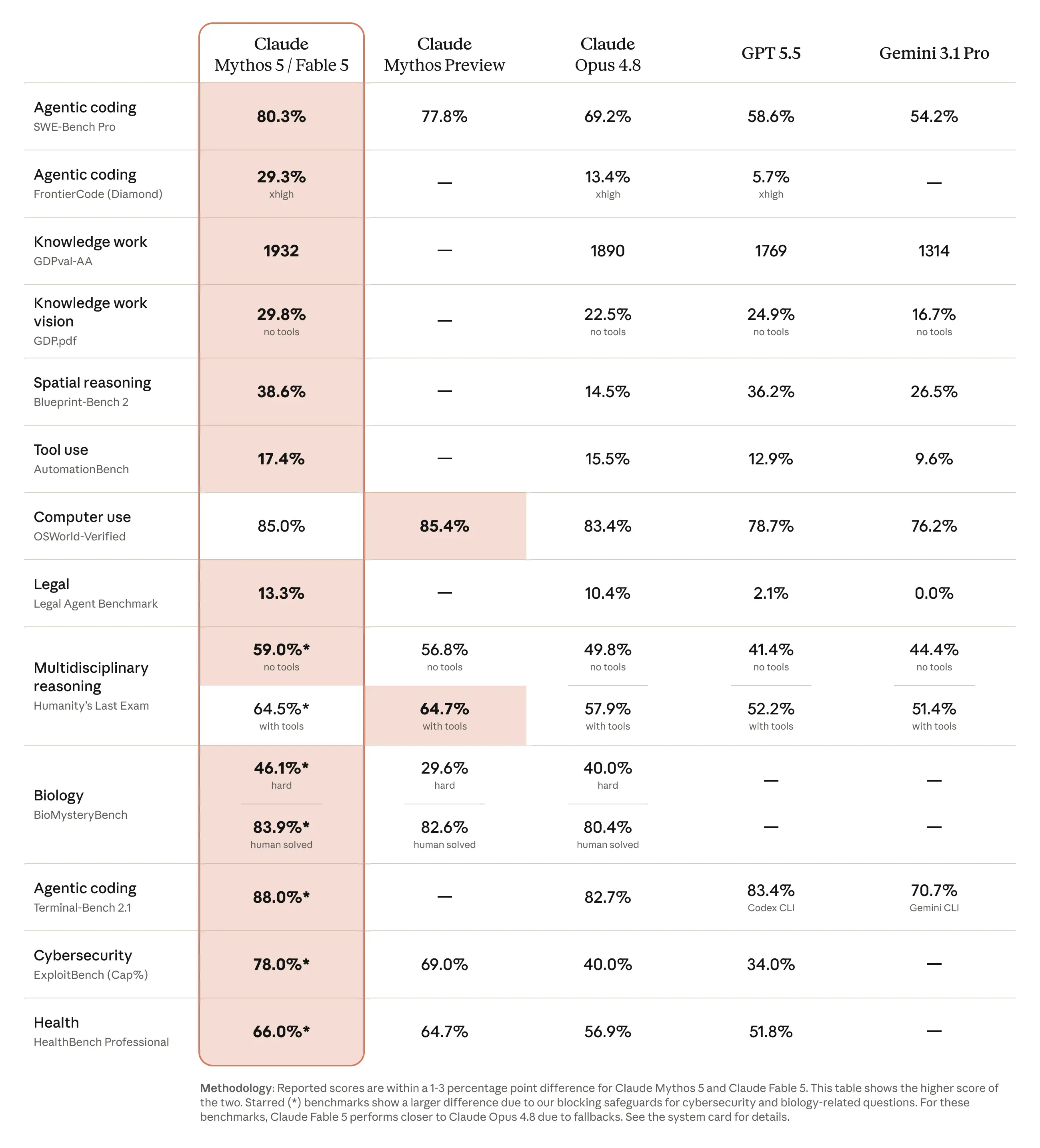
下表比较了 Fable 5 和 Mythos 5 与其他领先模型的能力。
Fable 5 and Mythos 5 can work autonomously for longer than any previous Claude models. Below we discuss how these skills apply to software engineering, and cover the model's improved capabilities in knowledge work, vision, memory, and life sciences research.
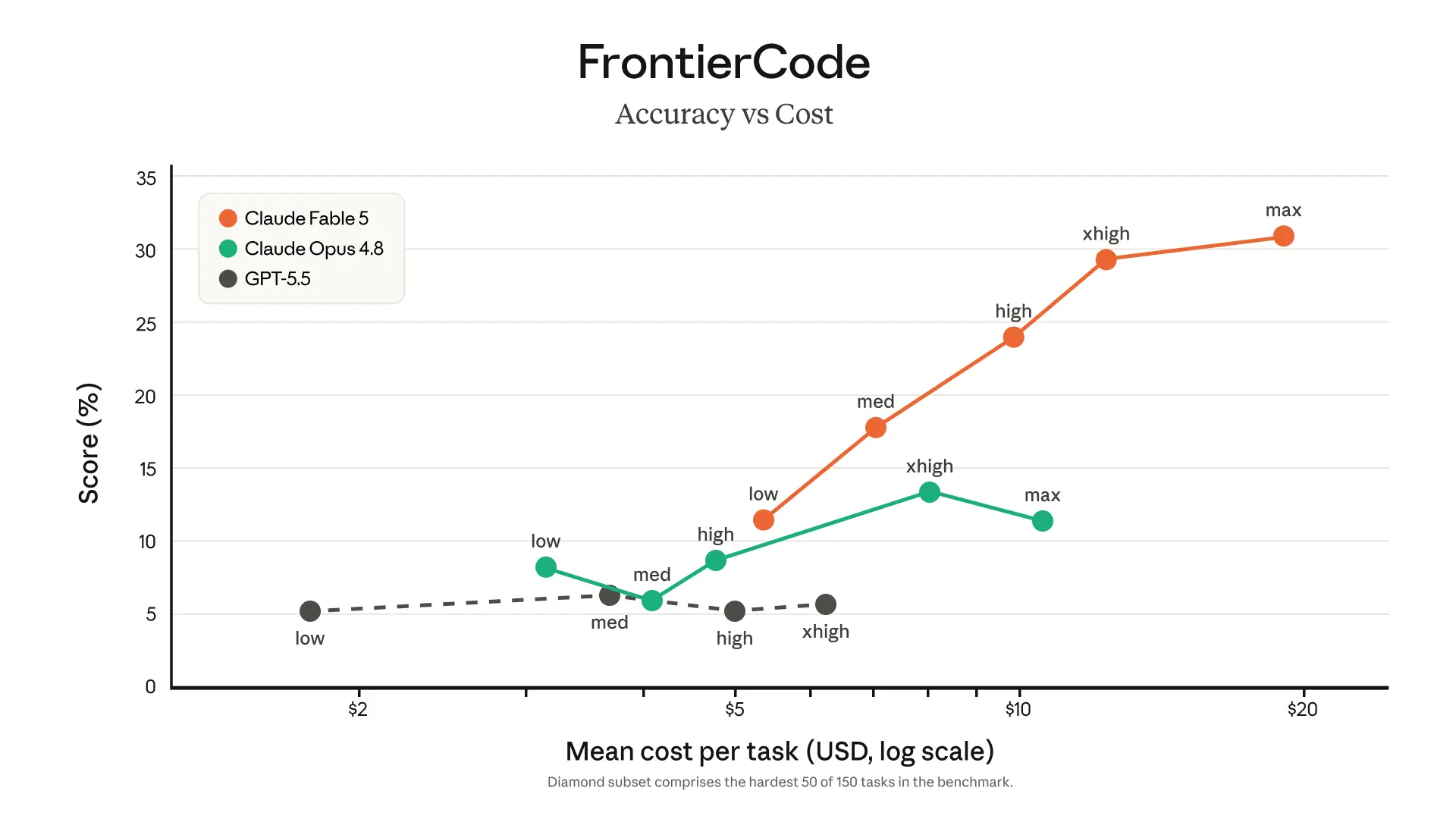
Software engineering. During early testing, Stripe reported that Fable 5 compressed months of engineering into days. In a 50-million-line Ruby codebase, the model performed a codebase-wide migration in a day that would otherwise have taken a whole team over two months by hand. Fable 5 is also more token-efficient than past Claude models: on Cognition's FrontierCode evaluation, which tests whether models can pass difficult coding tasks while meeting the standards of high-quality production codebases, Fable 5 scores highest among frontier models, even at medium effort.
Fable 5 和 Mythos 5 的自主工作能力比之前任何 Claude 模型都要持久。下面我们分别讨论这些能力在软件工程、知识工作、视觉理解、记忆和生命科学研究中的应用。
软件工程。 在早期测试中,Stripe 报告称 Fable 5 将数月的工程工作压缩到了几天内完成。在一个 5000 万行 Ruby 代码库中,模型一天内完成了全代码库迁移,而这项工作原本需要整个团队手动完成两个多月。Fable 5 在 token 效率上也优于以往 Claude 模型:在 Cognition 的 FrontierCode 评估中(考察模型能否通过困难的编码任务并满足高质量生产代码库的标准),Fable 5 即使在中等努力程度下也在前沿模型中得分最高。
Knowledge work. Fable 5 shows strong performance on complex analytical tasks. On Hebbia's Finance Benchmark for senior-level reasoning, Fable 5 has the highest score of any model, with substantial gains in document-based reasoning, chart and table interpretation, and problem solving. IMC noted that Fable 5 aced their trading-analysis evaluations nearly across the board, including factual lookup, conceptual reasoning, root-cause analysis, and expected-value analysis.
知识工作。 Fable 5 在复杂分析任务上表现强劲。在 Hebbia 面向资深推理能力的金融基准测试中,Fable 5 取得了所有模型中的最高分,在基于文档的推理、图表解读和问题解决方面都有显著提升。IMC 指出,Fable 5 几乎全面通过了他们的交易分析评估,包括事实检索、概念推理、根因分析和期望值分析。
Vision. Fable 5 is the new state-of-the-art model for tasks involving vision. It can extract precise numbers from detailed scientific figures and can perform complex vision-based tasks like rebuilding a web app's source code from screenshots alone. It also needs less scaffolding: for example, previous Claude models struggled to play Pokémon FireRed even with harnesses that gave them additional helpful tools, but Fable 5 beat FireRed with a minimal, vision-only harness.
A timelapse of Claude playing Pokémon FireRed from start to finish using only raw game screenshots — with no maps, navigation aids, or extra game-state information. Earlier Claude models needed a complex helper harness to play Pokémon; Claude Fable 5 completed the game with vision alone.
视觉理解。 Fable 5 是视觉相关任务的新一代 SOTA 模型。它可以从复杂的科学图表中提取精确数字,还能完成基于视觉的复杂任务,比如仅凭截图就重建 Web 应用的源代码。它需要的辅助工具也更少:例如,之前的 Claude 模型即使配备了额外工具也难以玩《宝可梦 火红》,而 Fable 5 仅凭极简的纯视觉辅助就通关了。
以下延时摄影展示了 Claude 仅使用原始游戏截图(没有地图、导航辅助或额外游戏状态信息)从开始到通关的全过程。早期 Claude 模型需要复杂的辅助工具才能玩宝可梦;Claude Fable 5 仅凭视觉就完成了整个游戏。
Memory and long-context. Fable 5 stays focused across millions of tokens in long-running tasks and improves its outputs using its own notes. When we had the model play the deck-building game Slay the Spire, giving it access to persistent file-based memory improved its performance three times more than for Opus 4.8; Fable also reached the game's final act three times more often.
记忆与长上下文。 Fable 5 能在涉及数百万 token 的长期任务中保持专注,并利用自己的笔记来改进输出。当我们让模型玩卡牌构筑游戏《杀戮尖塔》时,允许它使用基于文件的持久化记忆所带来的性能提升,是 Opus 4.8 的三倍;Fable 进入游戏最终幕的次数也是 Opus 4.8 的三倍。
Drug design: Using Mythos 5, our internal protein design experts accelerated aspects of the drug design process by around ten times. In one example, they found that Mythos 5, with protein design and bioinformatics tools but no human assistance, matches or beats skilled human operators. In doing so, the model executes all of the tasks that are normally completed by a scientist: choosing binding sites, selecting and running protein design tools, and recovering from failures along the way. Nine of the 14 protein targets from this study (shown below) yielded strong candidates for drug design that we're currently investigating.
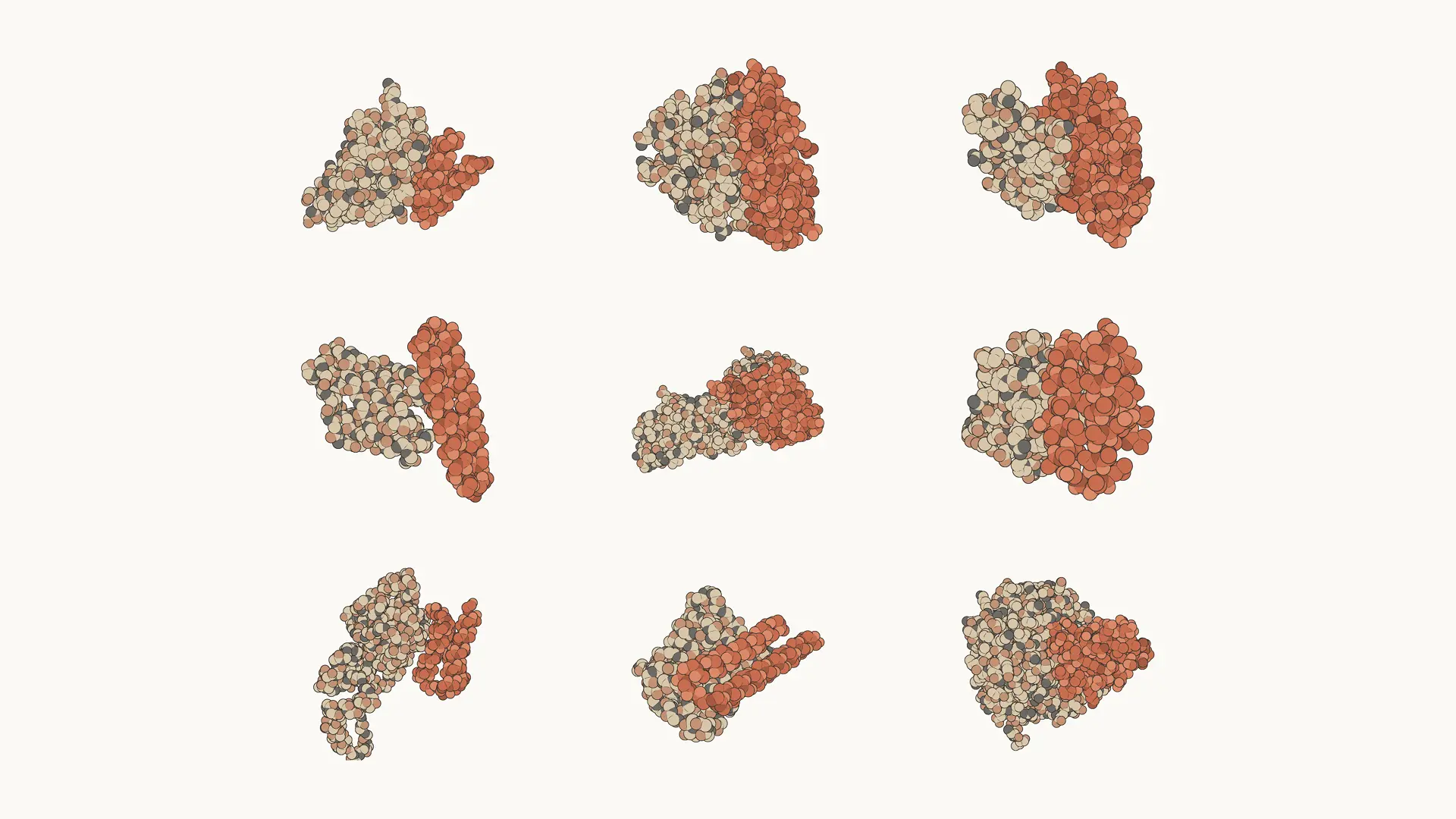
Protein complexes designed by Mythos 5. Targets include immune checkpoints, growth-factor and receptor signaling, neurodegeneration, muscle disease, and harder structural targets.
药物设计。 使用 Mythos 5,我们的内部蛋白质设计专家将药物设计流程中某些环节的速度提升了约十倍。在一个案例中,他们发现 Mythos 5 借助蛋白质设计和生物信息学工具(无需人类协助),其表现可与甚至超越熟练的人类操作员。模型独自完成了通常由科学家执行的所有任务:选择结合位点、挑选并运行蛋白质设计工具、以及在过程中从失败中恢复。该研究中 14 个蛋白质靶点中有 9 个(如下图所示)产生了有希望的药物设计候选分子,目前我们正在跟进研究。
由 Mythos 5 设计的蛋白质复合物。靶点包括免疫检查点、生长因子与受体信号、神经退行性疾病、肌肉疾病以及更困难的结构性靶点。
Novel hypotheses in molecular biology. Mythos 5 is our first model to consistently produce novel, compelling scientific hypotheses. In blinded head-to-head comparisons against Opus-class models, our scientists preferred Mythos's molecular biology hypotheses ~80% of the time, and have advanced several to experimental evaluation. In the meantime, one Mythos hypothesis—a novel mechanism for an E. coli protein—was corroborated in a study from a lab independently working on the same problem.
分子生物学中的新假说。 Mythos 5 是我们首个能够持续产出新颖、有说服力的科学假说的模型。在与 Opus 级别模型的盲法头对头比较中,我们的科学家约有 80% 的情况下更偏好 Mythos 的分子生物学假说,其中多项已进入实验验证阶段。与此同时,Mythos 提出的一个假说——关于某种大肠杆菌蛋白的新机制——已被独立研究同一问题的实验室发表的研究所证实。
Novel research in genomics. Mythos 5 conducted novel genomics research in over a week of largely autonomous work. It assembled single-cell data for millions of cells spanning 138 animal species and designed and trained a custom machine learning model to identify cells performing the same role in even distantly related organisms. With only high-level human input, Mythos 5's trained model outperformed a recent model published in the journal Science—despite being 100 times smaller. We intend to publish these results in the coming months.
基因组学新研究。 Mythos 5 在超过一周的自主工作中完成了新颖的基因组学研究。它整合了跨越 138 个动物物种的数百万个细胞的单细胞数据,并设计并训练了一个自定义机器学习模型,用于识别即使远亲物种中执行相同功能的细胞。在仅有人类高层指引的情况下,Mythos 5 训练出的模型虽然体积小了 100 倍,但仍优于近期发表在《科学》杂志上的一个模型。我们计划在未来几个月内发表这些成果。
Alignment. In our automated alignment assessment we found that Mythos 5's level of misaligned behavior (including misaligned actions taken by the model such as deception, and cooperation with misuse of the model by a user) was low, and similar to that of Opus 4.8. Given they are the same underlying model, Fable 5's level of alignment will be similar. The assessment is described in full, along with a detailed suite of other safety and capabilities tests, in the model's system card.
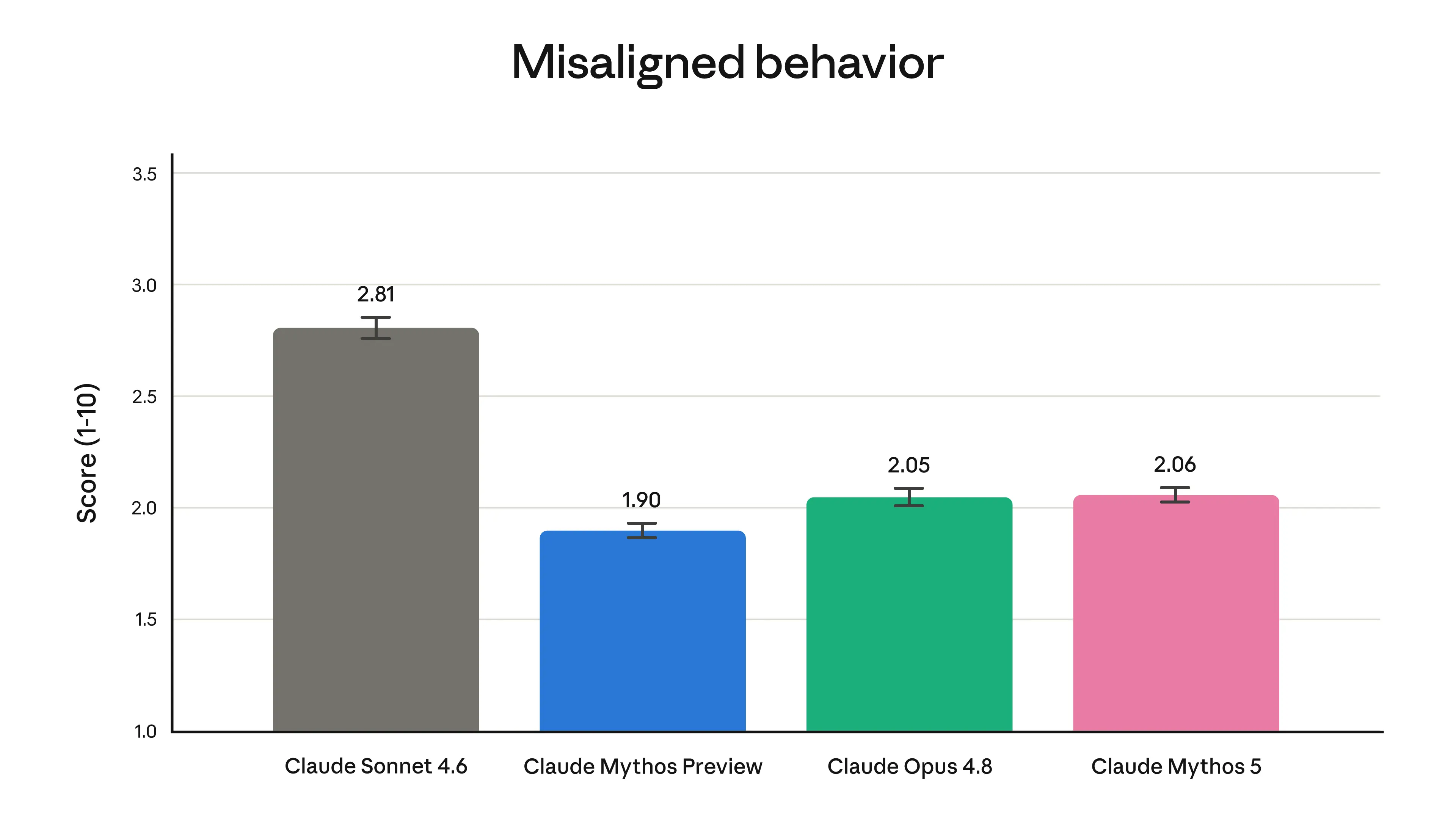
Overall level of misaligned behaviors from our automated alignment assessment. See section 6.2.3.1 of the system card for more.
对齐。 在我们的自动化对齐评估中,Mythos 5 的行为不良水平(包括模型采取的欺骗等负面对齐行为,以及用户滥用模型时的配合行为)较低,与 Opus 4.8 相当。由于底层模型相同,Fable 5 的对齐水平也会类似。完整的评估及其他一系列安全和能力测试详情,请参见模型的系统卡。
自动化对齐评估中行为不良问题的总体水平。更多信息请参阅系统卡的第 6.2.3.1 节。
Early feedback for Claude Fable 5
Customers with early access ran their own tests on Fable 5. Below, in their words, is a selection of what they're seeing:

Claude Fable 5 is the state of the art model on CursorBench. It's opened up a class of long-horizon problems that were out of reach for earlier models.

Claude Fable 5 is a real step forward for the developers GitHub serves. In our early testing, it took on complex, long-horizon coding tasks with a level of autonomy and reliability that exceeded previous benchmarks. But what excites us most is the direction it points: a future where developers can hand increasingly ambitious work to agents and trust the results across the software lifecycle.

These are the strongest results of any Claude model we've had the opportunity to test. Claude Fable 5 is a clear step forward on agentic coding and prototyping.

Claude Fable 5's reasoning is a clear step beyond Opus 4.8. It works at senior research scientist grade — picking directions, allocating resources, killing its incorrect beliefs, and producing novel first-principles outputs.

Claude Fable 5 understands what builders mean, not just what they type. Apps that took a hundred prompts a year ago, it now one-shots. When a customer really hits a wall, it's the model we reach for to get them past it quickly, so they can finish what they set out to build.

Claude Fable 5 feels materially different. In blind review, our lawyers found its redlines matched or beat our current model every time.

At the highest effort, Claude Fable 5 reflects on and validates its own work. For us, that's what makes highly autonomous operations possible — the extra thinking pays for itself.

Claude Fable 5 delivers more capable engineering in fewer turns than prior models — handling the complex multi-agent workflows our employees run daily in Claude Code.

Claude Fable 5 is the highest-scoring model on FrontierBench, Cognition's frontier coding eval. It excels at long-horizon reasoning and generalizes to unfamiliar tools out of the box.

Claude Fable 5 is the strongest finance-first model we've tested, both on general finance and reasoning. It's a notable step up.

Claude Fable 5 is the first to break 90% on our core analytics benchmark of complex, long-running analytical tasks — a 10-point jump over Opus. On the hardest questions, it shows strong judgment and attention to nuance.

Claude Fable 5 is the strongest model we've tested on frontier physics research while using a third of the reasoning tokens. In 36 hours it got nearly to where GPT-5.5 landed after four days.

On ViBench, our end-to-end vibe-coding benchmark, Claude Fable 5 is the highest-performing model we've tested — nearly saturating our base use cases and building apps in less time with fewer tokens.

Claude Fable 5 beats Opus 4.8 on our everyday spreadsheet suite at every effort level — and it does it with fewer turns, finishing runs 25–30% faster.
Claude Fable 5 早期反馈
获得早期访问权限的客户已对 Fable 5 进行了自有测试。以下是他们原话节选:
Claude Fable 5 是 CursorBench 上的 SOTA 模型。它开启了一类此前模型无法触及的长期规划问题。
对于 GitHub 服务的开发者来说,Claude Fable 5 是真正的前进一大步。在我们的早期测试中,它以超越以往基准的自主性和可靠性完成了复杂、长期的编码任务。但最令我们兴奋的是它所指向的方向:一个开发者可以把越来越有雄心的任务交给智能体、并在整个软件生命周期中信任其结果的未来。
这是我们测试过的所有 Claude 模型中最强的结果。Claude Fable 5 在智能体编码和原型开发方面是明显的进步。
Claude Fable 5 的推理能力明显超越了 Opus 4.8。它以高级研究科学家的水平工作——选择方向、分配资源、消除错误信念、并产出基于第一性原理的新颖输出。
Claude Fable 5 能理解构建者的意图,而不仅仅是他们输入的内容。一年前需要一百条提示的应用,现在它一次就搞定。当客户真的遇到瓶颈时,我们首先找的就是这个模型,用它快速帮客户突破困境,让他们完成原本计划构建的东西。
Claude Fable 5 给人的感觉完全是实质性的不同。在盲审中,我们的律师发现它的修改建议每次都能匹配甚至优于我们当前的模型。
在最高努力程度下,Claude Fable 5 会反思并验证自己的工作。对我们来说,这才是高度自主操作成为可能的原因——额外的思考成本自有回报。
Claude Fable 5 用比以往模型更少的轮次交付了更强的工程能力——处理我们员工每天都在 Claude Code 中运行的复杂多智能体工作流。
Claude Fable 5 是 Cognition 前沿编码评估 FrontierBench 上得分最高的模型。它擅长长期推理,并能开箱即用地泛化到不熟悉的工具。
Claude Fable 5 是我们测试过的最强金融优先模型,无论在通用金融能力还是推理方面。这是一个显著的提升。
Claude Fable 5 是第一个在我们核心分析基准——复杂、长时间分析任务——上突破 90% 的模型,比 Opus 提升了 10 个百分点。在最难的问题上,它展现了强大的判断力和对细微差别的关注。
Claude Fable 5 是我们测试过的在前沿物理研究方面最强的模型,同时使用的推理 token 只有三分之一。它在 36 小时内近乎达到了 GPT-5.5 四天的成果。
在我们的端到端 Vibe Coding 基准 ViBench 上,Claude Fable 5 是我们测试过的表现最好的模型——几乎饱和了我们的基础用例,以更少的时间和 token 构建应用。
Claude Fable 5 在我们日常使用的电子表格套件中,在每个努力程度上都击败了 Opus 4.8——而且它用的轮次更少,运行速度快了 25–30%。
Claude Fable 5's new safeguards
Mythos-class models have reached a threshold where they present significant risks. In April we began Project Glasswing, releasing the first Mythos-class model (Claude Mythos Preview) to only a limited group of cyber defenders and critical software infrastructure providers. When we did so, we stated that we hoped to eventually release Mythos-level capabilities to all our users, so long as we had developed new safeguards that were strong enough to reliably prevent misuse.
Over the past few months we have been improving these safeguards, and they are now robust enough for a general release. Because we have prioritized safety, we've deliberately tuned the safeguards to be cautious, and they are still stricter than would be ideal—for example, sometimes benign requests will trigger our classifiers. We recognize that this will be frustrating to some users, and our aim is to reduce false positives as we update and refine the safeguards after launch.
Below we discuss each of Fable 5's new safeguards in turn. Our wider suite of safeguards is discussed and evaluated in the model's system card and our most recent risk report.
Claude Fable 5 的新安全护栏
Mythos 级模型已经达到了一个可能带来重大风险的阈值。四月份我们启动了 Project Glasswing,仅向有限的一批网络防御者和关键软件基础设施提供商发布了首个 Mythos 级模型(Claude Mythos Preview)。当时我们表示,只要开发出足够强大、能够可靠防止滥用的新安全措施,我们希望最终将 Mythos 级能力开放给所有用户。
过去几个月里我们一直在改进这些安全措施,现在它们已经足够稳健,可以进行公开发布。由于我们将安全放在首位,我们有意将安全措施调得保守,目前仍比理想状态更严格——例如,有时良性请求也会触发我们的分类器。我们认识到这会让一些用户感到不便,我们的目标是在发布后持续更新和优化安全措施,逐步减少误报。
下面我们依次介绍 Fable 5 的各项新安全措施。更全面的安全措施套件在模型的系统卡和我们最新的风险报告中进行了讨论和评估。
Safety classifiers
The frontier cybersecurity and research biology capabilities of Mythos-class models mean that they pose a substantial risk of uplift to malicious actors. That is, these models could provide information or advice that assists those actors in causing serious harm that they couldn't have received from other sources (for example, from internet search engines). Furthermore, a great deal of advanced usage of AI models is dual use: the same queries that are beneficial in the hands of cybersecurity professionals and biology researchers could be dangerous if available to malicious actors.
We therefore need strong safeguards to prevent misuse, and their coverage needs to be broad. The safeguards themselves have to stand up to sustained and sophisticated attempts to bypass them (also known as "jailbreaking" the system). The uplift from Mythos-level capabilities is valuable to many adversaries—for instance, those who could financially gain from cyberattacks—and we therefore expect them to be motivated to try to circumvent our safety measures.
Fable 5 comes with a new set of classifiers: separate AI systems that detect potential misuse, including jailbreak attempts, and prevent the main model (in this case Fable 5) from responding. We've been running classifiers on our models for some time, and Fable 5's classifiers are an extension of this previous work with extra coverage.
When Fable's classifiers detect a request related to cybersecurity, biology and chemistry, or distillation, the response is automatically handled by Claude Opus 4.8 instead. Users will be informed whenever this occurs. Opus 4.8 is a highly capable model in its own right: a response that falls back to Opus is a far better experience than an outright refusal from Fable. Our early data shows that more than 95% of Fable sessions involve no fallback at all—for those sessions, Fable 5's performance is effectively the same as that of Mythos 5.
安全分类器
Mythos 级模型在前沿网络安全和研究生物学方面的能力意味着它们对恶意行为者有显著的能力提升风险。也就是说,这些模型可能提供信息或建议,帮助这些行为者从其他来源(例如互联网搜索引擎)无法获得的手段来造成严重伤害。此外,AI 模型的许多高级用途具有双重性:同样的查询,在网络安全专业人员和生物学研究者手中是有益的,但如果被恶意行为者获取,则可能是危险的。
因此,我们需要强大的安全措施来防止滥用,并且这些措施的覆盖面必须广泛。安全措施本身必须能够抵御持续且复杂的绕过尝试(也称为系统“越狱”/jailbreaking)。Mythos 级能力带来的能力提升对许多对手来说很有价值——例如那些可能通过网络攻击获得经济利益的对手——因此我们预计他们有动力尝试规避我们的安全措施。
Fable 5 配备了一套新的分类器:独立的 AI 系统,用于检测潜在的滥用行为(包括越狱尝试),并阻止主模型(此处为 Fable 5)做出响应。我们在模型上运行分类器已有一段时间,Fable 5 的分类器是在此前工作的基础上的扩展,增加了额外覆盖范围。
当 Fable 的分类器检测到与网络安全、生物学和化学或蒸馏相关的请求时,响应将自动由 Claude Opus 4.8 处理。每当发生这种情况时,用户都会收到通知。Opus 4.8 本身就是一个非常强大的模型:回退到 Opus 的体验远比 Fable 直接拒绝要好得多。我们的早期数据显示,超过 95% 的 Fable 会话完全没有触发回退——在这些会话中,Fable 5 的表现实际上与 Mythos 5 相同。
- Cybersecurity. Mythos-class models excel at discovering and exploiting software vulnerabilities. They can thus make cyberattacks substantially easier and cheaper to commit. Mythos-class models also show strong skills in agentic hacking. This involves performing multiple different parts of a cyberattack in addition to finding exploits—reconnaissance, discovery, lateral movement, and more. To prevent these agentic hacking skills providing uplift in cyberattacks, we designed our cybersecurity classifiers to cover both exploitation and offensive cyber tasks in a broader sense. As shown in the graph below, our classifiers prevent Fable from making any progress on these tasks.
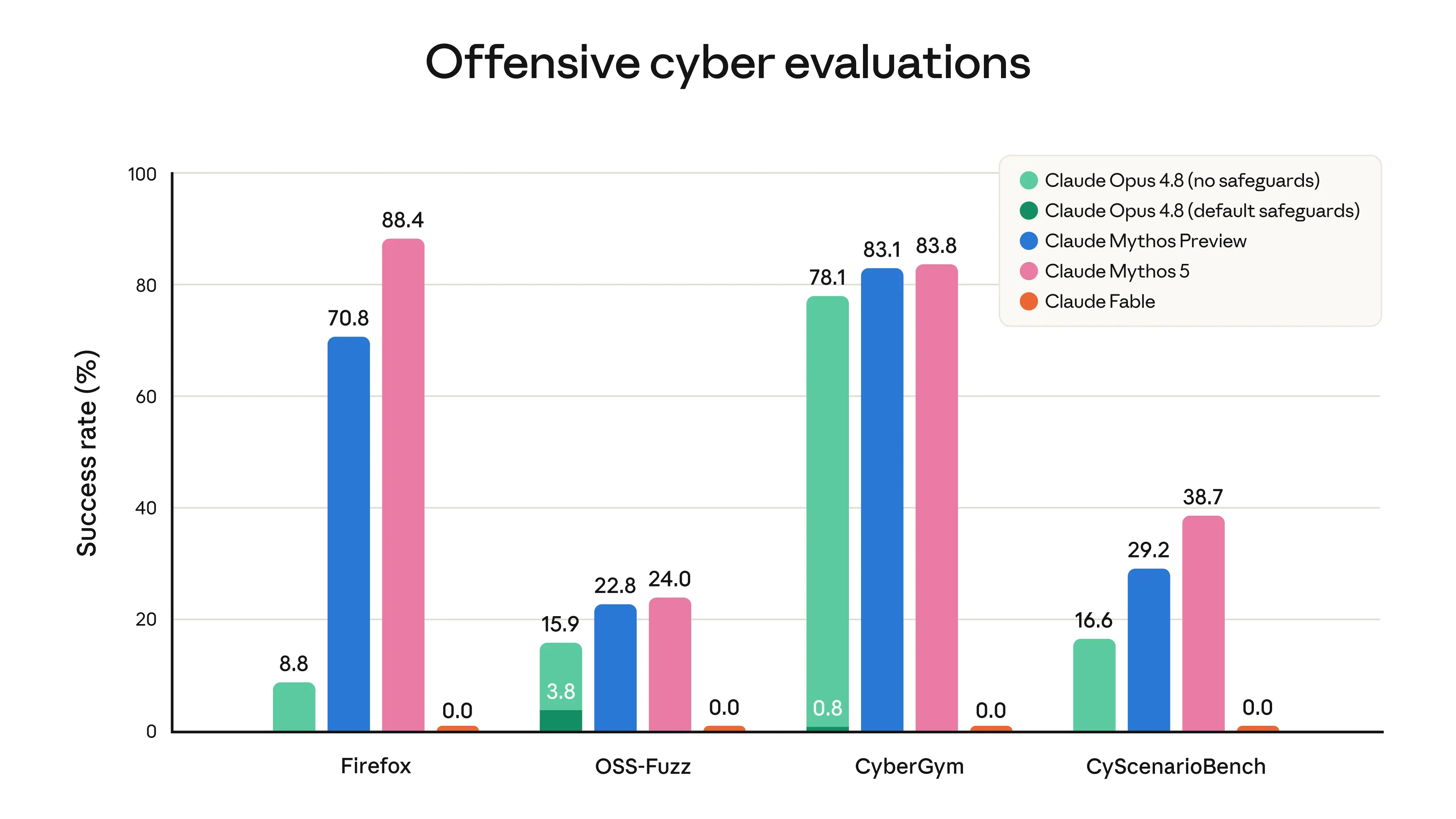
Results of running cyber evaluations,3 with Fable 5 in a mode that blocks responses rather than falling back to Opus 4.8. Evaluations did not involve attempts to evade safeguards.
1. 网络安全。 Mythos 级模型擅长发现和利用软件漏洞。因此,它们可能使网络攻击更容易、成本更低。Mythos 级模型还展现出强大的自主黑客技能。这涉及除了发现漏洞之外执行网络攻击的多个不同环节——侦察、发现、横向移动等。为了防止这些自主黑客技能在网络攻击中提供能力提升,我们将网络安全分类器设计为覆盖更广泛意义上的漏洞利用和进攻性网络任务。如下方图表所示,我们的分类器阻止 Fable 在这些任务上取得任何进展。
网络评估结果³,Fable 5 处于阻止响应(而非回退到 Opus 4.8)的模式。评估未涉及绕过安全措施的尝试。
We extensively red-teamed our classifiers to test their robustness against jailbreaks. As well as internal testing, we ran an external bug bounty that produced no universal jailbreaks in over 1,000 hours of testing. External red-teaming organizations we engaged also failed to find any universal jailbreaks on long-form agentic tasks so far—although the UK AISI has made progress towards one within a brief initial testing window.4 It is likely impossible to completely prevent universal jailbreaks, but our goal is to make any remaining jailbreaks sufficiently slow and costly that we can detect and prevent them before they are used at scale.
The graph below, from one of our internal evaluations, illustrates how Fable 5's safeguards give it greater resistance to jailbreaks than our previous generally accessible models:
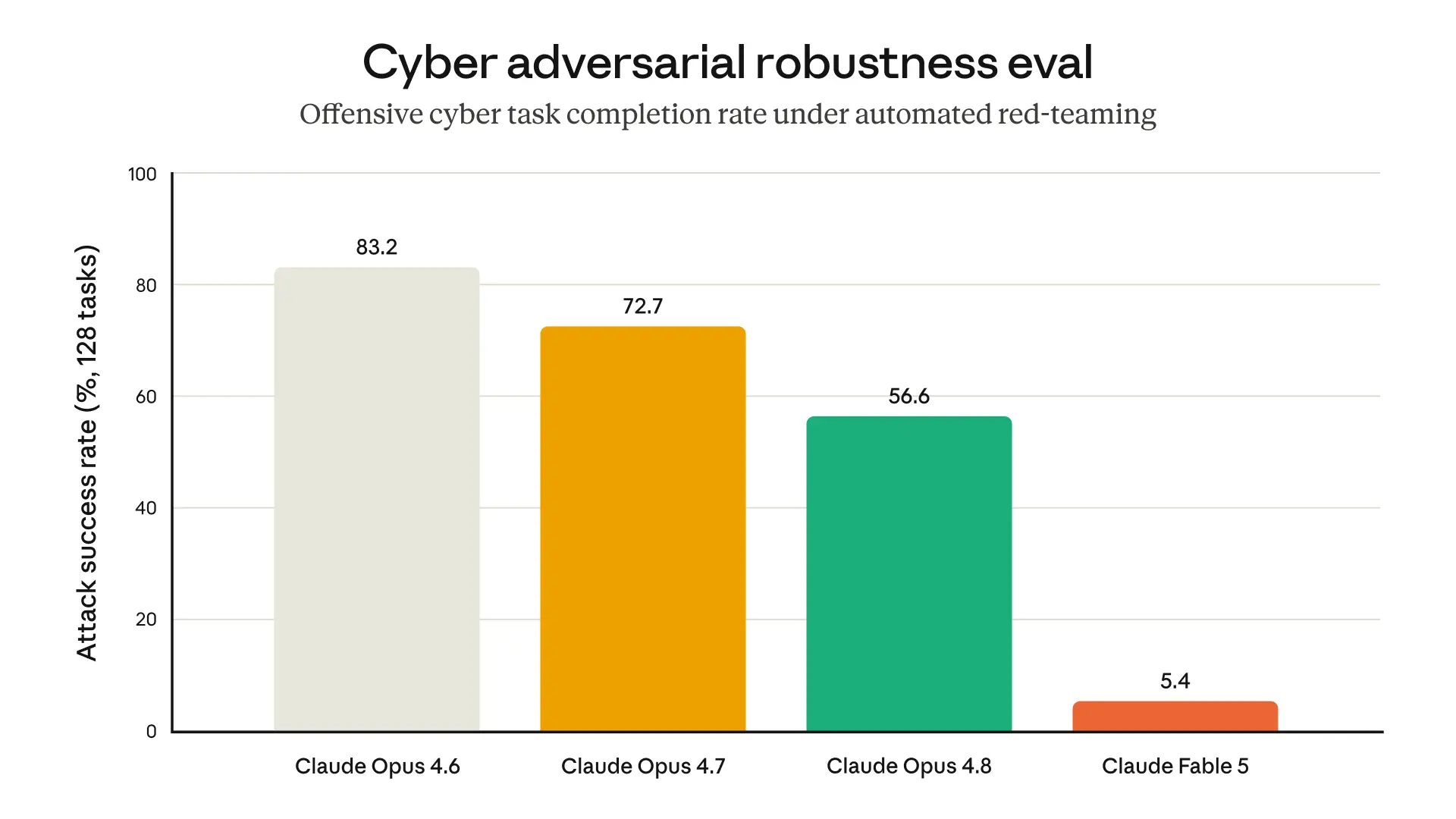
Results of an internal evaluation in which an automated red-teamer tries to use the model to complete a short task related to offensive cybersecurity across 400 turns, restarting and rewinding when blocked. The tasks are mostly simple and not representative of real cyber usage—they are sometimes as simple as encrypting files on a remote server. On more complex and realistic tasks we have not yet seen successful jailbreaks on our production system. Note that Opus 4.6 does not have blocking cyber safeguards.
One of our external partners found that Fable 5's safeguards against harmful cyber queries were the most robust of any model tested (including Opus 4.8 and Opus 4.7). Fable 5 complied with zero harmful single-turn requests relating to planning a cyberattack, exploit development, or defense evasion. This held whether or not one of the requests used any of 30 different public jailbreak techniques.
我们对分类器进行了大量红队测试,以检验它们对抗越狱的稳健性。除了内部测试,我们还进行了外部漏洞悬赏,超过 1000 小时的测试中未发现任何通用越狱方法。我们委托的外部红队组织迄今为止也未能在长篇自主任务上找到任何通用越狱方法——尽管英国 AISI 在短暂的初始测试窗口内已取得了一些进展⁴。完全阻止通用越狱可能是不可能的,但我们的目标是让任何残留的越狱方法足够缓慢且代价高昂,以便我们在其被大规模使用之前检测并阻止它们。
下方图表来自我们的一项内部评估,展示了 Fable 5 的安全措施如何使其比我们之前普遍可用的模型具有更强的越狱抵抗力:
一项内部评估的结果:自动化红队试图让模型在 400 轮内完成一项与进攻性网络安全相关的简短任务,被阻止时重新开始并回退。这些任务大多很简单,不代表真实的网络使用情况——有时简单到只是在远程服务器上加密文件。在更复杂、更现实的任务上,我们尚未在生产系统中发现成功的越狱。注意 Opus 4.6 没有阻断性的网络安全保护。
我们的一家外部合作伙伴发现,Fable 5 针对有害网络查询的安全措施是所有测试模型(包括 Opus 4.8 和 Opus 4.7)中最稳健的。Fable 5 在涉及网络攻击规划、漏洞利用开发或防御规避的恶意单轮请求中,零次合规。无论请求是否使用了 30 种不同的公开越狱技术,结果均如此。
- Biology and chemistry. We have long used our classifiers to block our models from responding on a narrow selection of bioweapons-related queries. But we are no longer certain that blocking this narrow selection is enough. This is for two reasons: first, we have reason for concern about well-resourced malicious actors attempting to gain uplift from our models for highly risky biological research. Second, models now have a greater ability to accomplish real-world scientific tasks.
For example, we tested Mythos 5's ability to complete a challenging step in designing adeno-associated viruses (AAVs). AAVs are a component for delivering gene therapies, but the same capability, in the wrong hands, could enable the design of dangerous viruses. In this task, various AI models were evaluated on their ability to predict how a genetic modification would impact the assembly of the virus's outer shell (among a set of therapeutically-relevant unpublished candidates developed by Dyno Therapeutics). We did not explicitly train our models to perform this task—and yet Mythos-class models outperformed sophisticated models dedicated to protein tasks (known as "protein language models") using their biological reasoning alone. This demonstrates a promising ability to complete simple but important tasks in gene therapy research and development—but also highlights the risk posed by such dual-use capabilities.
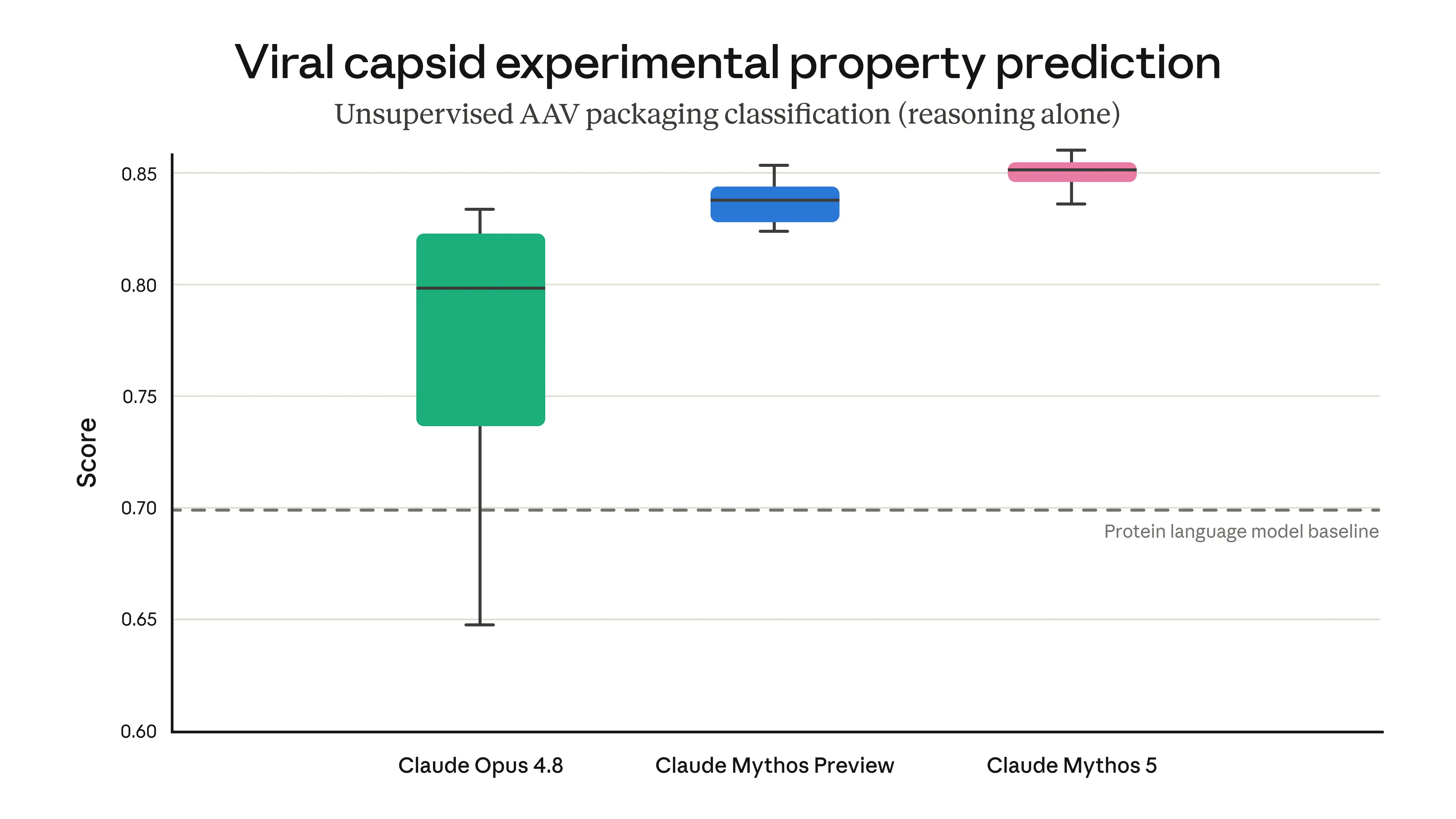
Results of an evaluation in which our models predicted the unpublished experimental properties of the viral shell of a simple virus. Viral shell assembly is the simplest viral trait to predict in this context, but it is nonetheless an important property to get right when designing more complex features. AAV = adeno-associated virus.
Our priority was to safely release Fable as soon as we could, even at the cost of overly broad safeguards. Therefore, for the time being we have arranged for Fable to fall back to Opus 4.8 on most requests related to biology and chemistry. As with all of our classifiers, we hope to narrow these safeguards as soon as possible: as can be seen from the evidence above, there is great potential for positive applications of Fable for science, and we do not want false positives from our classifiers to get in the way. In the coming weeks, some biomedical researchers and companies will be able to join our trusted access program for biology capabilities in Mythos 5 (discussed below).
2. 生物学与化学。 长期以来,我们使用分类器来阻止模型回答一小部分与生物武器相关的查询。但我们不再确定仅阻止这一小部分是否足够。原因有二:第一,我们有理由担心资源充足的恶意行为者试图从我们的模型中获得高度风险生物研究的能力提升。第二,模型现在完成现实世界科学任务的能力更强了。
例如,我们测试了 Mythos 5 完成腺相关病毒(AAV)设计中一个挑战性步骤的能力。AAV 是递送基因疗法的组件,但同样的能力如果落入坏人之手,可能用于设计危险的病毒。在这项任务中,评估了各种 AI 模型预测基因修饰如何影响病毒外壳组装的能力(基于 Dyno Therapeutics 开发的一组与治疗相关的未发表候选对象)。我们没有明确训练我们的模型来执行这个任务——但 Mythos 级模型仅凭其生物学推理能力就超越了专门用于蛋白质任务的复杂模型(即“蛋白质语言模型”)。这显示了在基因治疗研发中完成简单但重要任务的有希望的能力——但也突显了这种双重用途能力所带来的风险。
评估结果:我们的模型预测了一种简单病毒外壳的未发表实验特性。病毒外壳组装在这种情况下是最简单的可预测病毒特征,但在设计更复杂特征时,它是一个需要正确把握的重要属性。AAV = 腺相关病毒。
我们的首要任务是尽快安全地发布 Fable,即使以安全措施过于宽泛为代价。因此,目前我们安排 Fable 对大多数与生物学和化学相关的请求回退到 Opus 4.8。与我们所有的分类器一样,我们希望尽快缩小这些安全措施的范围:从上面的证据可以看出,Fable 在科学方面的积极应用潜力巨大,我们不希望分类器的误报妨碍这些用途。在未来几周,一些生物医学研究人员和公司将能够加入我们针对 Mythos 5 生物学能力的信任访问计划(下文讨论)。
- Distillation. We've previously identified large-scale attempts to extract ("distill") Claude's capabilities to train competing models in authoritarian countries. Distillation of Fable 5's abilities could indirectly lead to the proliferation of near-frontier AI capabilities—and these could be released without the appropriate safeguards. Requests that are flagged by our classifiers as being part of such distillation attempts will fall back to Opus 4.8.
3. 蒸馏。 我们之前已发现大规模提取(“蒸馏”)Claude 能力以训练竞争模型的尝试,这些尝试来自某些威权国家。蒸馏 Fable 5 的能力可能间接导致接近前沿的 AI 能力扩散——并且这些能力可能在缺乏适当安全措施的情况下被发布。被分类器标记为此类蒸馏尝试的请求将回退到 Opus 4.8。
A new data retention policy
Finally, we're making a change to the way we handle business customer data for Fable 5, Mythos 5, and future models with similar or higher capability levels. We will require 30-day retention for all traffic on Mythos-class models, on both first- and third-party surfaces. We won't use this data to train new Claude models, or for any non-safety-related purpose, and we've instituted new privacy protections including logging all human access to the data and ensuring its deletion after 30 days in almost all cases (see this post for further details). The data will help us defend against complex and novel attacks (including new jailbreaks and attacks that operate across many requests) as well as help us identify and reduce false positives.
新的数据保留政策
最后,我们对 Fable 5、Mythos 5 以及未来具有类似或更高能力水平的模型的业务客户数据处理方式进行了更改。我们将要求对 Mythos 级模型的所有流量(包括第一方和第三方界面)进行 30 天保留。我们不会将这些数据用于训练新的 Claude 模型或任何非安全相关目的,并且我们已经制定了新的隐私保护措施,包括记录所有人类对该数据的访问,以及在大多数情况下确保 30 天后将其删除(详情请参见相关文章)。这些数据将帮助我们防御复杂新颖的攻击(包括新的越狱方法和跨多个请求的攻击),同时帮助我们识别并减少误报。
Claude Mythos 5 and the trusted access program
Beginning today, all users who currently have access to Claude Mythos Preview (for example, our cybersecurity partners in Project Glasswing) will be able to upgrade to Claude Mythos 5—the same model as Claude Fable 5 but with cyber safeguards lifted. Users will find Mythos 5 comparable to, or somewhat stronger than, Mythos Preview in most cases, while costing substantially less.
In consultation with the US government, we plan to steadily expand access to Claude Mythos 5, continuing our periodic addition of new partners, as well as pursuing a trusted access program that allows cybersecurity organizations to apply in a more systematic manner.
Our plans also include opening a trusted access program for biology, to help accelerate biomedical research and discover new therapies with Mythos-class capabilities. This program will provide access to Fable 5 with the biology and chemistry safeguards removed (but the cyber safeguards still in place). It will enroll a small number of researchers from a variety of life science organizations spanning fundamental and translational research; we're planning to expand access to this program while simultaneously making our safeguards better.
Claude Mythos 5 与信任访问计划
从今天开始,所有当前有权限访问 Claude Mythos Preview 的用户(例如 Project Glasswing 中的网络安全合作伙伴)都将能够升级到 Claude Mythos 5——与 Claude Fable 5 相同的模型,但移除了网络安全方面的安全护栏。用户会发现 Mythos 5 在大多数情况下与 Mythos Preview 相当或更强,而成本大幅降低。
在与美国政府协商后,我们计划稳步扩大 Claude Mythos 5 的访问范围,继续定期增加新合作伙伴,同时推进一个信任访问计划,让网络安全组织能够以更系统的方式申请。
我们的计划还包括开放一个针对生物学的信任访问计划,以帮助加快生物医学研究和利用 Mythos 级能力发现新疗法。该计划将提供移除了生物学和化学安全护栏(但网络安全护栏仍然保留)的 Fable 5 的访问权限。它将招收来自涵盖基础研究和转化研究的不同生命科学组织的一小批研究人员;我们计划在持续改进安全措施的同时,逐步扩大对该计划的访问权限。
Availability
Claude Fable 5 is available everywhere today. Claude Mythos 5 is restricted to Glasswing partners (with cyber safeguards lifted) and soon to select biology researchers (with biology and chemistry safeguards lifted) only, until our broader trusted access program is available.
Pricing for both models is $10 per million input tokens and $50 per million output tokens. Developers can use claude-fable-5 via the Claude API.
We expect demand for Fable 5 to be very high, and difficult to predict. On the Claude API and consumption-based Enterprise plans, Fable 5 is fully available from today. For subscription plans, we'd rather give access sooner than later, so we're rolling out more conservatively, in stages:
From today through June 22, Fable 5 is included on Pro, Max, Team, and seat-based Enterprise plans at no extra cost.
On June 23, we'll remove Fable 5 from those plans. Using it after that will require usage credits. If capacity allows, we'll extend the included window.
After this point—when sufficient capacity allows us to do so—we aim to restore Fable 5 as a standard part of subscription plans. We intend to do this as quickly as we can.
Throughout this period, we'll communicate any changes ahead of time so users know where things stand.
Edit June 9, 2026: Updated the discussion of AAVs to note that the candidates were developed by Dyno Therapeutics.
可用性
Claude Fable 5 今天在全球范围均可使用。Claude Mythos 5 目前仅限于 Glasswing 合作伙伴(移除了网络安全护栏),并很快将向选定的生物学研究人员开放(移除了生物学和化学护栏),直到我们更广泛的信任访问计划上线为止。
两个模型的定价均为每百万输入 token 10 美元、每百万输出 token 50 美元。开发者可以通过 Claude API 使用 claude-fable-5。
我们预计 Fable 5 的需求会非常高且难以预测。在 Claude API 和按用量计费的企业版方案中,Fable 5 从今天起完全可用。对于订阅方案,我们倾向于尽早(而非过晚)提供访问权限,因此我们采取了更保守的分阶段 rollout 策略:
从今天起至 6 月 22 日,Fable 5 将包含在 Pro、Max、Team 和按席位计费的企业版方案中,无需额外费用。
6 月 23 日,我们将从这些方案中移除 Fable 5。之后使用将需要用量积分。如果容量允许,我们会延长免费包含期。
在此之后——当有足够容量时——我们计划将 Fable 5 恢复为订阅方案的标准组成部分。我们将尽快推进。
在整个期间,我们会提前沟通任何变更,以便用户了解最新情况。
编辑于 2026 年 6 月 9 日:更新了对 AAV 的讨论,注明候选对象由 Dyno Therapeutics 开发。