Building effective human-agent teams
Anthropic shares four lessons from months of internal testing on building human-agent teams. The shift is from a single-player experience (one human, one AI) to a multiplayer model where agents hold their own credentials, persistent memory, and broad access, joining team channels as full members. The key insights: work in public so agents have context, define clear roles and tool access for every member, set an ambitious north star to make agents proactive, and build trust by granting autonomy gradually. Includes practical examples like agent-led bug backlogs and doer-verifier patterns. A must-read for teams embedding AI agents into collaborative workflows.
Working with AI used to mean one person interfacing with a single chat window. Over time, AI has become increasingly capable at handling complex, long-running work, like coding, research, and financial analysis. With this, we’ve seen many new ways to use AI—from the terminal and IDE to spreadsheets and decks—but the work has still very much been a “single-player” experience: one human worked with one agent to accomplish individual tasks.
This is changing with the release of tools like Claude Tag. Now, humans and agents can work together in the same workspace, collaborating in service of goals shared by a team. Work now looks a lot more like a multiplayer game, with teams of humans setting the strategy, and Claude executing the work.
This involves some new ways of working. At Anthropic, we’ve been testing the technology required to make human-agent teams successful for the last several months. In this article, we explain what multiplayer agents are, and the lessons we’ve learned for building with them.
过去与 AI 协同工作,意味着一个人面对单个聊天窗口。随着时间的推移,AI 处理复杂、长周期任务(如编程、研究和财务分析)的能力日益增强。我们看到了许多使用 AI 的新方式——从终端和 IDE 到电子表格和演示文稿——但工作在很大程度上仍是一种“单人游戏”体验:一个人与一个代理协作完成个人任务。
随着 Claude Tag 等工具的问世,这种情况正在改变。现在,人类和代理可以一起在同一工作空间中协作,朝着团队共享的目标推进。工作变得更像多人游戏:人类团队制定战略,Claude 负责执行。
这带来了一些新的工作方式。过去几个月里,Anthropic 一直在测试让人机协作团队成功运作所需的技术。在本文中,我们将解释什么是多人代理,以及我们从中汲取的构建经验。
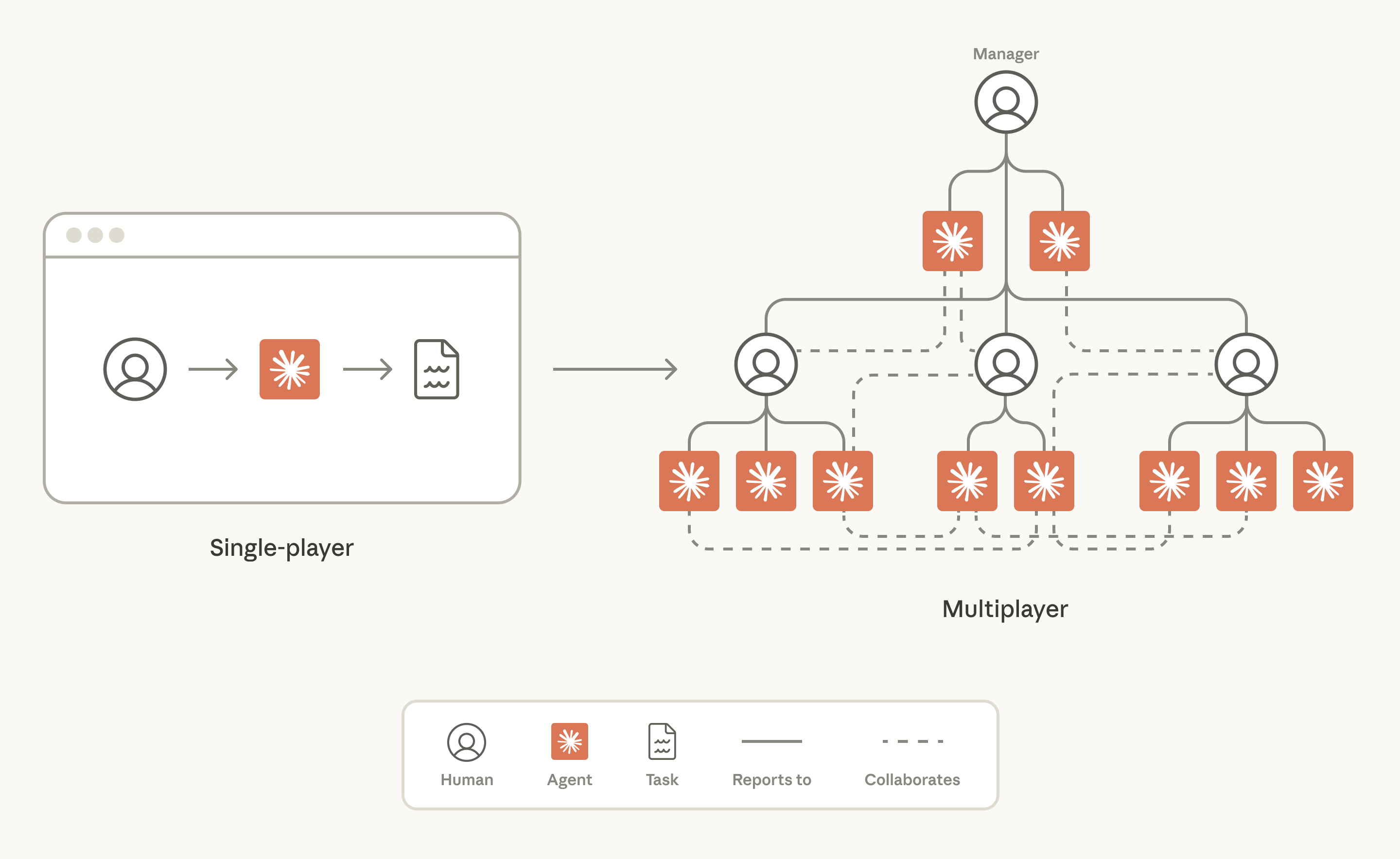
What are multiplayer agents?
“Multiplayer agents” is how we refer here to AI models that work with many different humans at the same time. Much like regular agents, they have their own memory and skills. But in other respects they're quite different. They have their own credentials and they live in places where work happens. At Anthropic, that's inside team collaboration tools like Slack.
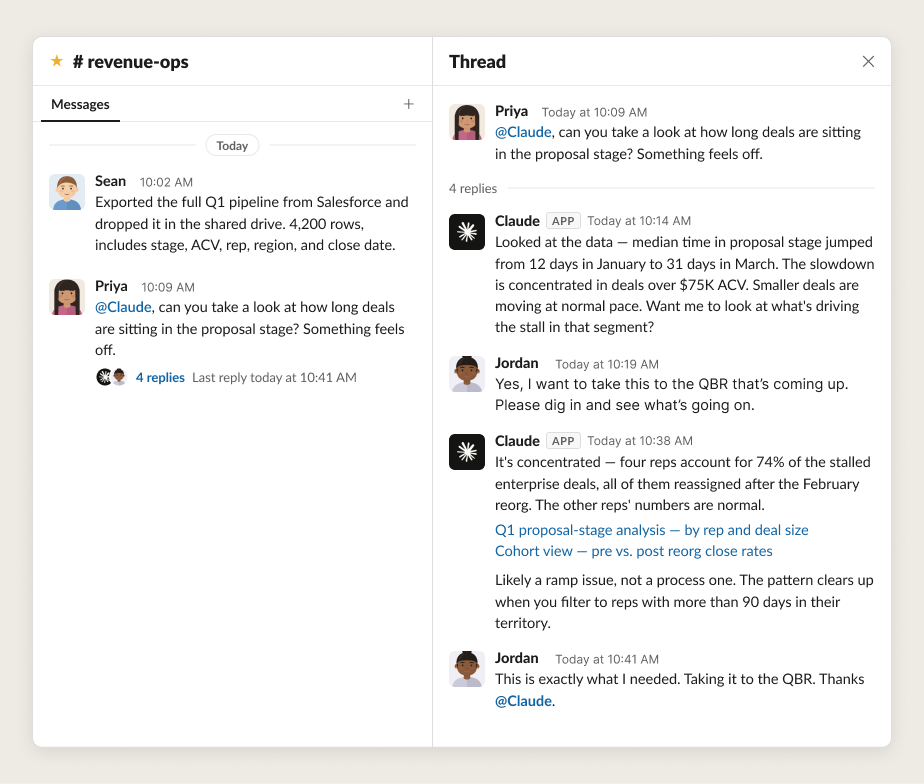
Here’s an example of a human-agent team analyzing a dataset together in Slack:
For agents to productively participate in a team channel, they need specific capabilities:
Persistent memory, so they can remember goals and tune their execution towards them
Credentials not tied to humans, so they can operate within safe, predictable guardrails
Ongoing broad access to information, so they can learn how the organization works and take action to execute tasks in service of the team’s goals
These capabilities amount to the technical foundation required for an agent to participate productively across a team of many humans. However, making human-agent teams successful requires more than this: teams need specific ways of working and shared norms, too.
什么是多人代理?
“多人代理”是指能够同时与多个不同人类协作的 AI 模型。与普通代理类似,它们拥有自己的记忆和技能。但在其他方面,它们却大不相同。它们拥有自己的凭证,并且存在于工作发生的地方。在 Anthropic,它们就在 Slack 等团队协作工具中。
下面是一个人机协作团队在 Slack 中共同分析数据集的示例:
为了让代理有效参与团队频道,它们需要具备以下特定能力:
持久记忆,以便记住目标并根据目标调整执行;
独立于人类的凭证,以便在安全、可预测的护栏内运作;
持续广泛的信息访问,以便了解组织的运作方式,并采取行动执行有助于实现团队目标的任务。
这些能力构成了代理在多人团队中有效参与所需的技术基础。然而,让人机协作团队成功运行还需要更多:团队需要特定的工作方式和共享规范。
Lesson 1: Work in public and give agents broad context
Teams at Anthropic share information proactively and openly. This is especially true when agents are on the team, because agents build their understanding entirely from the text a team makes searchable: Slack, code, docs, and meeting notes. Private messages, hallway conversations, and restricted documents can’t provide agents with context. For an agent, if it’s not written down and accessible, it doesn’t exist.
Instead of deciding what information should be available to agents one doc or Slack channel at a time, we use clearly defined security boundaries that apply to entire Slack workspaces, as well as to meeting transcripts and doc libraries. Within the security boundary, context flows to every teammate—whether human or AI. Not only does this increase what agents and humans get access to, it also reduces confusion about what can be shared and with whom. Humans and agents alike find it difficult to navigate the soft boundaries of per-item sharing: should this channel be public or private? Can I share this doc with that person? Is this agent allowed to see that thread? A small number of clear, workspace-level boundaries removes decision fatigue from day-to-day work.
A high degree of transparency has a reward. For instance, agents that can read decisions from team meetings won't suggest tasks or projects that were deprioritized. Agents with access to product specs beyond their own team can recommend patterns that have succeeded for others. And because agents can read enormous volumes of text far faster than humans do, they routinely surface relevant work that humans would otherwise have missed. We lean on our agents heavily to stay informed and coordinated in a busy, fast-moving industry.
At Anthropic, working in public looks like:
Choosing a handful of security boundaries at the company and creating workspaces and document sharing settings that match each security boundary
Defaulting new communication channels to public within the organization, and ensuring decisions land in channels, docs, and meeting notes every time
Writing artifacts and meeting notes so that agents can find them, since agents are now a primary consumer of team documentation
Making sure AI has access to the right tools and information needed to get their job done
Defaulting information to be internally public can require cultural shifts. However, the difference between human-agent teams with context and those without is too stark to ignore.
Of course, some interactions are sensitive and will need to be private between a single human and AI. For those, with Claude Tag you can send @Claude a direct message, or you can use the existing Claude.ai and Claude Cowork applications. These tools give Claude access to private information via your personal MCP connectors, with the knowledge that your conversation and what you share with the agent will remain private.
经验一:公开工作并提供广泛上下文
Anthropic 的团队会主动、公开地分享信息。当团队中有代理时尤其如此,因为代理完全依赖于团队可搜索的文本(如 Slack、代码、文档和会议笔记)来建立理解。私人消息、走廊交谈和受限文档无法为代理提供上下文。对于代理来说,如果信息没有被记录下来且可访问,它就不存在。
我们不会逐个文档或逐个 Slack 频道地决定哪些信息应提供给代理,而是使用明确的安全边界,这些边界适用于整个 Slack 工作区、会议记录和文档库。在安全边界内,上下文会流向每位团队成员——无论是人类还是 AI。这不仅增加了代理和人类可访问的信息量,还减少了关于可分享内容及分享对象的困惑。人类和代理在按项共享的软边界中都会感到困惑:这个频道应该是公开还是私密的?我能把这份文档分享给那个人吗?这个代理能看到那个讨论串吗?少量清晰的工作区级边界消除了日常工作中的决策疲劳。
高度透明会带来回报。例如,能够阅读团队会议决策的代理不会提出那些已被降优先级的任务或项目。能够访问自己团队之外产品规格的代理可以推荐其他团队成功采用的方法。而且,由于代理阅读大量文本的速度远快于人类,它们常常能发现人类原本会错过的相关工作。我们严重依赖代理来帮助我们在繁忙、快节奏的行业中保持信息同步和协调。
在 Anthropic,公开工作的具体做法包括:
在公司层面选择少数几个安全边界,并创建与每个安全边界相匹配的工作区和文档共享设置;
将组织内部的新通信频道默认为公开,并确保每次决策都记录在频道、文档和会议笔记中;
编写产物和会议笔记,以便代理能够找到它们——因为代理现在是团队文档的主要消费者;
确保 AI 拥有完成工作所需的正确工具和信息;
将信息默认对内公开可能需要文化转变。然而,拥有上下文的人机协作团队与没有上下文的团队之间的差异太过明显,不容忽视。
当然,某些交互是敏感的,需要在单个人类和 AI 之间保持私密。对于这些情况,使用 Claude Tag 可以向 @Claude 发送直接消息,或使用现有的 Claude.ai 和 Claude Cowork 应用程序。这些工具通过您的个人 MCP 连接器让 Claude 访问私人信息,同时确保您的对话以及与代理分享的内容保持私密。
Lesson 2: Every human and agent get a defined role with the right tools for the job
Human-agent teams share one roster, one set of artifacts, and one working space. Agents have their own credentials, skills, and tool access. Different agents also hold different roles: for instance, while one might own the data analysis for a project, another will hold and enforce the design standard, and a third will run research synthesis.
When a project kicks off, humans chat with the agents to figure out which roles to assign, and how the humans and agents will work together.
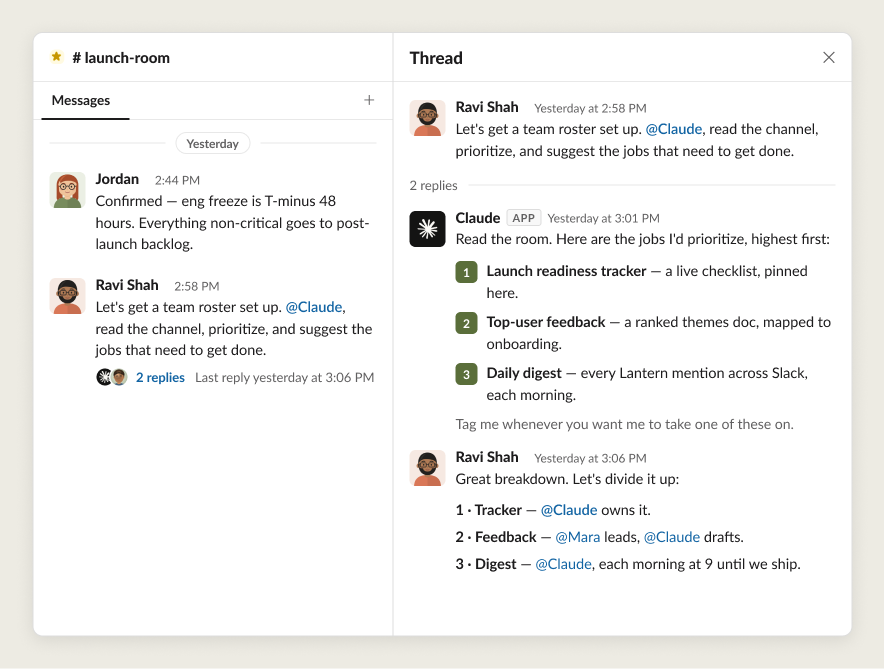
Once the jobs for humans and agents are clear, an agent might spin up other agents to make sure that specific tasks are handled by the agents with the right memory and appropriate access. Importantly, they need access to all the tools required to accomplish the job: one that handles data analysis might need access to BigQuery, and one that performs QA might need access to the Playwright MCP.
Clearly defined roles and responsibilities set human-agent teams up for success. Humans often work in the same threads the agents do, but they hold the roles only humans can hold. This ensures everything works together and human judgment is applied to the most important decisions. Without clear roles, people end up running fleets of personal AIs on the side, duplicating work and fracturing the team's context. Metrics tracking is a common case: a multiplayer agent can do the job once and let everyone see the same numbers.
At Anthropic, having clearly defined roles on human-agent teams looks like:
An agreed-upon task set: the team's humans and its agents agree on who does what
Humans and agents working in the same shared threads, so anyone can pick up where anyone left off
Humans and agents that have access to the right tools to accomplish their respective jobs
Descriptions of agents’ roles and scopes

Claude agents share the day-to-day maintenance of a codebase, triaging feedback, planning, writing code, reviewing changes, and reporting status. Each owns a clear task and works on its own schedule; people set the goals and review output.
An engineering team at Anthropic started creating rosters to help codify human and agent roles because it made driving their work much easier and more concrete. Some things that clicked for them early on:
Specific roles also help humans easily track where responsibility for a task lies, whether that’s in individual tasks or an entire team’s set of responsibilities
Writing skill files to define specific agents’ roles helps to make specialization easy, and allows people across the company to quickly stand up other agents of the same type
The team adds new agents to focus on new areas when projects get more complex. For example, they added a release manager agent to deal with new software releases.
These methods let humans' mental model of a human-agent team scale as the number of agents grows.
经验二:明确角色与工具分配
人机协作团队共享一个花名册、一套产物和一个工作空间。代理拥有自己的凭证、技能和工具访问权限。不同的代理承担不同的角色:例如,一个代理可能负责项目的数据分析,另一个负责维护和执行设计标准,第三个则负责研究整合。
项目启动时,人类与代理沟通以确定分配哪些角色,以及人类和代理将如何协作。
一旦人类和代理的任务明确,代理可能会启动其他代理,以确保特定任务由具有适当记忆和权限的代理处理。重要的是,它们需要访问完成工作所需的所有工具:负责数据分析的代理可能需要访问 BigQuery,而执行 QA 的代理可能需要访问 Playwright MCP。
明确定义的角色和职责为人机协作团队的成功奠定基础。人类通常与代理在同一讨论串中工作,但他们承担只能由人类承担的角色。这确保一切协同工作,而人类判断力被应用于最重要的决策。没有明确的角色,人们最终会各自运行私人 AI 集群,导致工作重复和团队上下文割裂。指标追踪是常见案例:多人代理可以一次性完成工作,让所有人看到相同的数字。
在 Anthropic,人机协作团队中明确角色分配的做法包括:
商定的任务集:团队的人类和代理就谁做什么达成一致;
人类和代理在相同的共享讨论串中工作,以便任何人都可以接手他人留下的工作;
人类和代理能访问完成各自工作所需的正确工具;
代理角色和范围的描述。
Claude 代理分担代码库的日常维护工作,包括分类反馈、规划、编写代码、审查变更和报告状态。每个代理拥有明确的任务并按自己的节奏工作;人类设定目标并审查输出。
Anthropic 的一个工程团队开始创建花名册,以帮助规范人类和代理的角色,因为这让推动工作变得更加容易和具体。他们早期的一些收获包括:
具体角色还能帮助人类轻松追踪任务的负责人,无论是单个任务还是整个团队的职责集合;
编写技能文件来定义特定代理的角色有助于轻松实现专业化,并让公司内其他人能快速搭建同类代理;
当项目变得更复杂时,团队会添加新的代理来专注于新领域。例如,他们添加了一个发布经理代理来处理新的软件发布。
这些方法让人类对人机协作团队的心智模型能够随着代理数量的增长而扩展。
Lesson 3: Set a north star to make agents more proactive
Although some agents at Anthropic simply complete assigned tasks, the most important ones proactively suggest new projects and workstreams. This often happens when a team that has already given its agents rich context and clear roles adds another guide: a north star.
North stars are ambitious, wide-reaching goals that help teams decide which tasks and workstreams are the right ones. At Anthropic, humans always set the north star, grounding it in the mission and goals of the business.
Once a north star is clearly articulated in writing, humans share it with the agents on their team. Then, importantly, humans choose which agents should proactively suggest new workstreams to help achieve this long-term goal. (It’s unlikely that every agent on the team will have the prerequisite skills and trust to proactively suggest work successfully.)
For example, an internal tools team with a north star to “make product onboarding more helpful” saw an agent proactively recommended copy revisions to the onboarding flow error messages. These changes measurably increased onboarding success the following week.
At Anthropic, setting a north star looks like:
Having humans discuss, debate, and document an ambitious north star goal for their human-agent team—one that’s rooted in the company’s mission and business goals
Sharing the north star with agents on the team and explicitly naming which agents can proactively recommend new workstreams
Keeping high-fidelity human time protected on the calendar, with meetings now focused on the most important work
A clear north star gives agents a consistent direction to work toward and meaningful opportunities to proactively support a team’s work.
经验三:设定北极星目标以激发代理主动性
虽然 Anthropic 的一些代理只是完成分配的任务,但最重要的那些代理会主动提出新项目和工作流。这通常发生在团队已经为代理提供了丰富的上下文和明确的角色之后,再增加一个指南针:北极星目标。
北极星目标是雄心勃勃、影响广泛的目标,帮助团队决定哪些任务和工作流是正确的。在 Anthropic,北极星目标始终由人类设定,并植根于公司的使命和业务目标。
一旦北极星目标以书面形式明确阐述,人类就会将其分享给团队中的代理。然后,重要的是,人类会选择哪些代理应该主动建议新的工作流来帮助实现这一长期目标。(并非团队中每个代理都具备成功主动提出工作的先决技能和信任。)
例如,一个内部工具团队设定了“让产品上手流程更有帮助”的北极星目标,他们发现一个代理主动建议修改上手流程中错误信息的文案。这些更改显著提高了下一周的上手成功率。
在 Anthropic,设定北极星目标的做法包括:
人类讨论、辩论并记录一个雄心勃勃的北极星目标——植根于公司的使命和业务目标;
将北极星目标分享给团队中的代理,并明确说明哪些代理可以主动推荐新工作流;
保护日历上高质量的“人类时间”,会议现在聚焦于最重要的工作。
清晰的北极星目标为代理提供了一致的工作方向,并为主动支持团队工作提供了有意义的机会。
Lesson 4: Build trust over time
Teams at Anthropic grant agents autonomy in proportion to demonstrated reliability, then expand it deliberately. Engineers have successfully dispatched agents on their team to handle 500 bug fixes independently, but things certainly didn’t start off that way.
When a new human colleague joins the team, it takes time to assess their capabilities and develop strong working routines. It usually takes multiple feedback cycles to externalize all the tacit information about how tasks are best completed. The same is true for agents. Users have to experiment with giving agents many different tasks so they can learn what the agent is capable of, how to clearly describe the goal, what skill files it needs, and what prompts work best to elicit a desired behavior. It’s also important to retest tasks as models change and improve. Prompts may need re-wording and guardrails that used to be helpful may constrain a smarter model from pursuing more creative solutions.
Notably, we’ve found that the best long-running agents have many different ways to verify their work before a human looks at it. Code has tests, of course, but most other work can be verified as well. For example, technical docs can have rubrics and style guides applied to them. When humans set the bar and ensure all work assigned to an agent can be vetted, quality stays high and doesn’t drift from the original intention. Separately, as with humans, it often helps to give one agent the job of doing the task and another agent the job of checking the first agent’s work. This is often called the “Doer-Verifier” agent harness.
At Anthropic, building trust with agents over time looks like:
Reviewing agent work manually in the beginning to vet quality, provide feedback, and design task verification checklists
Telling the agent to use a “verifier” agent to check its work as part of the task
Building reflection into the cycle and asking agents to review their own misses so work improves over time
Tracking which kinds of tasks each agent has earned autonomy on and expanding scope per task type after repeated successes
One engineering leader at Anthropic took on a new team with a big backlog. To get a handle on it, he invited a few humans and a few agents to help him sort through the backlog and prioritize what was most important. One set of agents on the team read through all of the items in the backlog, figured out if anyone was working on the items, and assigned a complexity score to anything that was unowned. The other set read from the list, filtered to the medium and low complexity items, and created code changes. At the beginning, humans reviewed every decision made by an agent and marked any that required human input. Then the humans taught the agents to surface those decisions to humans directly, ensuring that decisions with hard tradeoffs always had a human in the loop.

Every week, the leader and his team asked the agents to compile a weekly report that included “lessons & missteps” so the agents would keep track of mistakes and avoid making them again in the future. Over time, the leader was able to give more and more complex code changes to his agents and spend less time guiding the agents’ day to day tasks.
And once the agents were more independent, the leader coached them to treat human attention as the scarce resource it is: to batch questions to be answered in a single pass, repeat key context to get a human up to speed quickly, and limit how many things each human sees at once.
Helping agents communicate well ensures that they remain helpful and effective. Some people have agents in their team with the sole role of deciding how to batch and elevate only the most important communication for human team members. Others set guardrails around how much work agents should do per day, so that humans are able to meaningfully engage with the work. Such guardrails ensure that humans maintain skills that are important to them, and that the number of items requiring human review stays sustainable.
经验四:逐步建立信任
Anthropic 的团队会根据代理展示出的可靠性给予相应程度的自主权,然后有意识地扩大它。工程师们已经成功让团队中的代理独立处理了 500 个 bug 修复,但事情并非一开始就这样。
当一位新的人类同事加入团队,需要时间评估其能力并建立扎实的工作惯例。通常需要多个反馈周期才能将所有关于如何最好完成任务的隐性知识外化。对代理也是如此。用户必须尝试给代理分配许多不同的任务,以了解代理的能力范围、如何清晰描述目标、需要哪些技能文件,以及哪些提示最能激发出期望行为。随着模型的变化和改进,重新测试任务也很重要。提示可能需要重新措辞,曾经有用的护栏可能会限制更智能的模型探索更多创意解决方案。
值得注意的是,我们发现最好的长效代理在人类检查之前有多种方式验证其工作。代码当然有测试,但大多数其他工作也可以被验证。例如,技术文档可以应用量规和风格指南。当人类设定标准并确保分配给代理的所有工作都可以被审查时,质量就能保持高水平,不会偏离原始意图。另外,就像对待人类一样,将任务交给一个代理执行,再让另一个代理检查第一个代理的工作,通常会有所帮助。这通常被称为“执行者-验证者”代理框架。
在 Anthropic,与代理逐步建立信任的做法包括:
最初手动审查代理工作以评估质量、提供反馈,并设计任务验证清单;
告诉代理在任务中使用“验证者”代理来检查其工作;
在循环中建立反思机制,要求代理回顾自己的失误,以持续改进工作;
追踪每个代理在哪些类型的任务上获得了自主权,并在重复成功后按任务类型扩大范围。
Anthropic 的一位工程负责人接手了一个积压了大量任务的新团队。为了理清头绪,他邀请了几位人类和几位代理帮助他梳理积压任务并确定优先级。团队中的一组代理阅读了积压中的所有条目,判断是否有人在处理这些条目,并为所有无人认领的条目分配了复杂度评分。另一组代理从列表中筛选出中低复杂度的条目,并创建代码更改。开始时,人类审查代理做出的每一个决策,并标记任何需要人类输入的内容。然后,人类教代理将这些决策直接呈现给人类,确保涉及艰难权衡的决策始终有人参与。
每周,这位负责人和他的团队要求代理编制一份包含“经验教训与失误”的周报,以便代理记录错误并避免未来再犯。随着时间的推移,这位负责人能够把越来越复杂的代码更改交给代理,并减少用于指导代理日常任务的时间。
当代理变得更加独立后,这位负责人指导它们将人类的注意力视为稀缺资源:将问题批量打包以便一次性解答,重复关键上下文以快速让人进入状态,并限制每个人类同时看到太多信息。
帮助代理良好沟通确保它们保持有用和高效。一些人让团队中的代理专门负责决定如何批量处理并提升仅需人类成员关注的最重要沟通。另一些人则设定关于代理每日工作量的护栏,以便人类能够有意义地参与工作。这类护栏确保人类保持对他们重要的技能,并且需要人类审查的项目数量保持在可持续的水平。
Questions to ask
As you’re laying the foundation for your human-agent teams, consider the following questions:
Is all the information and access that agents and humans need both public and broadly searchable?
Can you write down your team's roster (humans and agents), and say what each member owns?
Does every human and agent on the team have access to the right tools to perform their job?
Do you have rubrics or tests for humans and agents to verify key work products?
Does your team have a clear north star that everyone can reference?
需要思考的问题
在你为人机协作团队奠定基础时,请考虑以下问题:
代理和人类所需的所有信息和访问权限是否都已公开且广泛可搜索?
能否写下团队的花名册(包括人类和代理),并说明每个成员负责什么?
团队中的每位人类和代理是否都有执行其工作所需的正确工具?
是否有供人类和代理验证关键工作成果的量规或测试?
团队是否有清晰的北极星目标可供每个人参考?
Moving forward
None of these patterns are new—at least not for humans. A strong north star, clear roles, strong documentation, a shared bar for quality, and room to learn from mistakes are the healthy team habits we’ve known for decades. Agents just make it even more important not to skip them.
The teams getting the most from their agents are the ones who are most intentional about applying these fundamentals.
Acknowledgements
This article was written by Kristen Swanson, a member of the Education team at Anthropic. She’d like to thank Matt Bell, Erik Olesund, Hasnain Lakhani, Shale Craig, Nolan Caudill, Mike Schiraldi, Aleks Todorova, and Molly Vorwerck for their contributions to this piece.
Start building multiplayer agents using agent teams in Claude Code or by using Claude Tag.
未来展望
这些模式并不新鲜——至少对人类来说不是。强大的北极星目标、明确的角色、完善的文档、共享的质量标准以及从错误中学习的空间,是我们几十年来就知道的健康团队习惯。代理只是让不跳过这些步骤变得更加重要。
从代理那里获益最多的团队,正是那些最用心应用这些基本原则的团队。
致谢
本文由 Anthropic 教育团队成员 Kristen Swanson 撰写。她感谢 Matt Bell、Erik Olesund、Hasnain Lakhani、Shale Craig、Nolan Caudill、Mike Schiraldi、Aleks Todorova 和 Molly Vorwerck 对本文的贡献。
现在即可以通过 Claude Code 中的代理团队或使用 Claude Tag 开始构建多人代理。