Multi-Agent Coordination Patterns: Five Approaches and When to Use Them
This post systematically covers five multi-agent coordination patterns: generator-verifier, orchestrator-subagent, agent teams, message bus, and shared state. For each, it explains the mechanism, where it works well, and known struggles (e.g., verifier quality depends on explicit criteria, orchestrator becomes information bottleneck, agent teams require independent subtasks, message bus tracing is hard, shared state risks reactive loops). It recommends starting with the simplest pattern and evolving based on where it struggles, with decision guides comparing patterns side by side. Suitable for engineering teams building multi-agent systems.
In an earlier post, we explored when multi-agent systems provide value and when a single agent is the better choice. This post is for teams that have made that call and now need to decide which coordination pattern fits their problem.
We've seen teams choose patterns based on what sounds sophisticated rather than what fits the problem at hand. We recommend starting with the simplest pattern that could work, watching where it struggles, and evolving from there. This post examines the mechanics and limitations of five patterns:
Generator-verifier, for quality-critical output with explicit evaluation criteria
Orchestrator-subagent, for clear task decomposition with bounded subtasks
Agent teams, for parallel, independent, long-running subtasks
Message bus, for event-driven pipelines with a growing agent ecosystem
Shared-state, for collaborative work where agents build on each other's findings
在之前的一篇文章中,我们探讨了多智能体系统何时有价值、何时单一智能体是更好的选择。本文面向那些已经做出判断、现在需要决定哪种协调模式适合其问题的团队。
我们观察到,有些团队选择模式的标准是听起来是否高级,而不是是否切合实际的问题。我们建议从最简单、可行的模式入手,观察它在哪些方面运转不畅,再逐步演进。这篇文章剖析了五种模式的具体机制和局限:
生成器-验证器模式(Generator-verifier),适用于质量要求高、有明确评估标准的输出场景
编排器-子智能体模式(Orchestrator-subagent),适用于任务分解清晰、子任务边界明确的情形
智能体团队模式(Agent teams),适用于并行、独立、长期运行的子任务
消息总线模式(Message bus),适用于事件驱动的流水线以及不断增长的智能体生态
共享状态模式(Shared-state),适用于需要智能体相互取长补短的协作工作
Pattern 1: Generator-verifier
This is the simplest multi-agent pattern and among the most deployed. We introduced it as the verification subagent pattern in our previous post, and here we use the broader generator-verifier framing because the generator need not be an orchestrator.
How it works
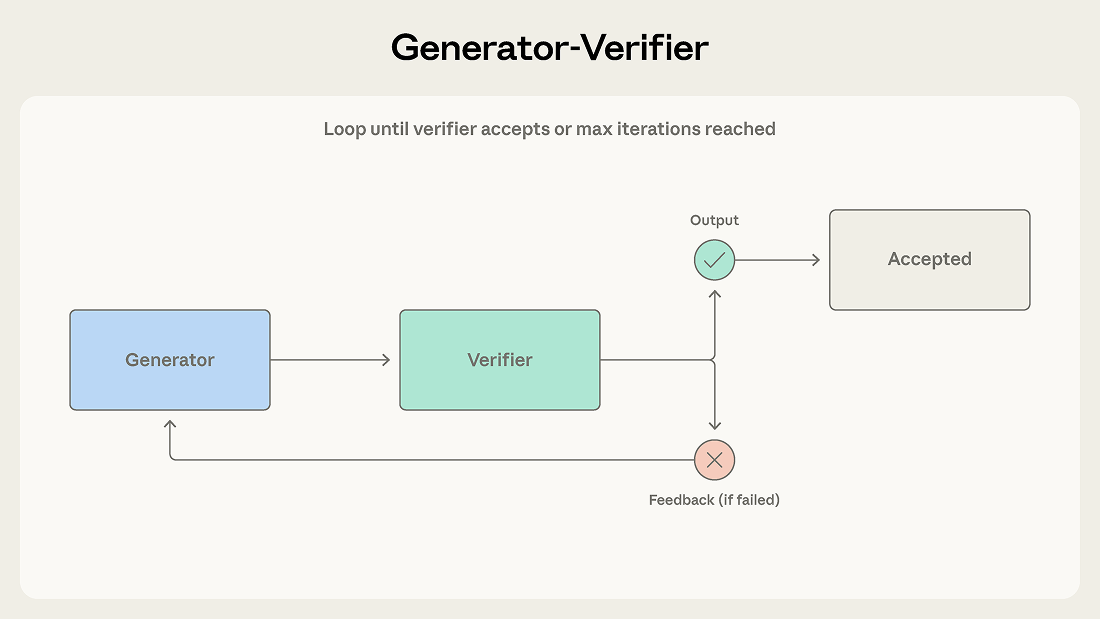
A generator receives a task and produces an initial output, which it passes to a verifier for evaluation. The verifier checks whether the output meets the required criteria and either accepts it as complete or rejects it with feedback. If rejected, that feedback is routed back to the generator, which uses it to produce a revised attempt. This loop continues until the verifier accepts the output or the maximum number of iterations is reached.
模式一:生成器-验证器
这是最简单的多智能体模式,也是部署最广的模式之一。我们在上篇文章中将其称作“验证子智能体模式”,本文采用更宽泛的“生成器-验证器”框架,因为生成器不一定是编排器。
工作方式
一个生成器接收任务并产出初始输出,然后将其传递给验证器进行评估。验证器检查输出是否符合要求,要么接受它并视为完成,要么带着反馈将其拒绝。如果被拒绝,反馈会返回给生成器,生成器据此进行修正。这个过程不断循环,直到验证器接受输出或达到最大迭代次数。
Where it works well
Consider a support system that generates email responses to customer tickets. The generator produces an initial response using product documentation and ticket context. The verifier checks accuracy against the knowledge base, evaluates tone against brand guidelines, and confirms the response addresses each issue raised. Failed checks return to the generator with feedback that names the exact problem, such as a feature misattributed to the wrong pricing tier or a ticket issue left unanswered.
Use this pattern when output quality is critical and evaluation criteria can be made explicit. It's effective for code generation (one agent writes code, another writes and runs tests), fact-checking, rubric-based grading, compliance verification, and any domain where an incorrect output costs more than an additional generation cycle.
适用场景
以一个生成客户工单邮件回复的支持系统为例。生成器利用产品文档和工单上下文起草回复。验证器对照知识库检查准确性,评估语气是否符合品牌规范,并确认回复解决了工单中提出的每个问题。未通过的检查会连同具体反馈返回给生成器,例如某个功能被归错了定价档位,或者工单中某条问题没有回复。
使用此模式的条件是:输出质量至关重要,且评估标准可以明确表达。该模式在代码生成(一个智能体写代码、另一个写并运行测试)、事实核查、基于评分标准的批改、合规验证,以及任何错误输出代价高于额外生成周期的领域都很有效。
Where it struggles
The verifier is only as good as its criteria. A verifier told only to check whether output is good, with no further criteria, will rubber-stamp the generator's output. Teams most often fail by implementing the loop without defining what verification means, which creates the illusion of quality control without the substance. (We discussed this early victory problem in the previous post.)
The pattern also assumes generation and verification are separable skills. If evaluating a creative approach is as hard as generating one, the verifier may not reliably catch problems.
Finally, iterative loops can stall. If the generator can't address the verifier's feedback, the system oscillates without converging. A maximum iteration limit with a fallback strategy (escalate to a human, return the best attempt with caveats) prevents this from becoming an infinite loop.
Pattern 2: Orchestrator-subagent
局限
验证器的效果完全取决于其标准。如果只让验证器检查“输出好不好”,却没有更细的标准,它只会照单全收。团队最常见的失败方式是实现了一个循环,却没有定义验证的具体含义,结果造成质量控制有名无实。(我们在上一篇文章中讨论过这种“早期胜利”问题。)
该模式同时还假设生成和验证是两种可分离的能力。如果评估一个创造性方案的难度与生成它相当,验证器可能无法可靠地发现问题。
最后,迭代循环可能陷入停滞。如果生成器无法回应验证器的反馈,系统就会反复振荡而不能收敛。设置最大迭代次数并配以回退策略(上报给人工、返回带注意事项的最佳尝试)可以防止系统死循环。
模式二:编排器-子智能体
Pattern 2: Orchestrator-subagent
Hierarchy defines this pattern. One agent acts as a team lead that plans work, delegates tasks, and synthesizes results. Subagents handle specific responsibilities and report back.
How it works
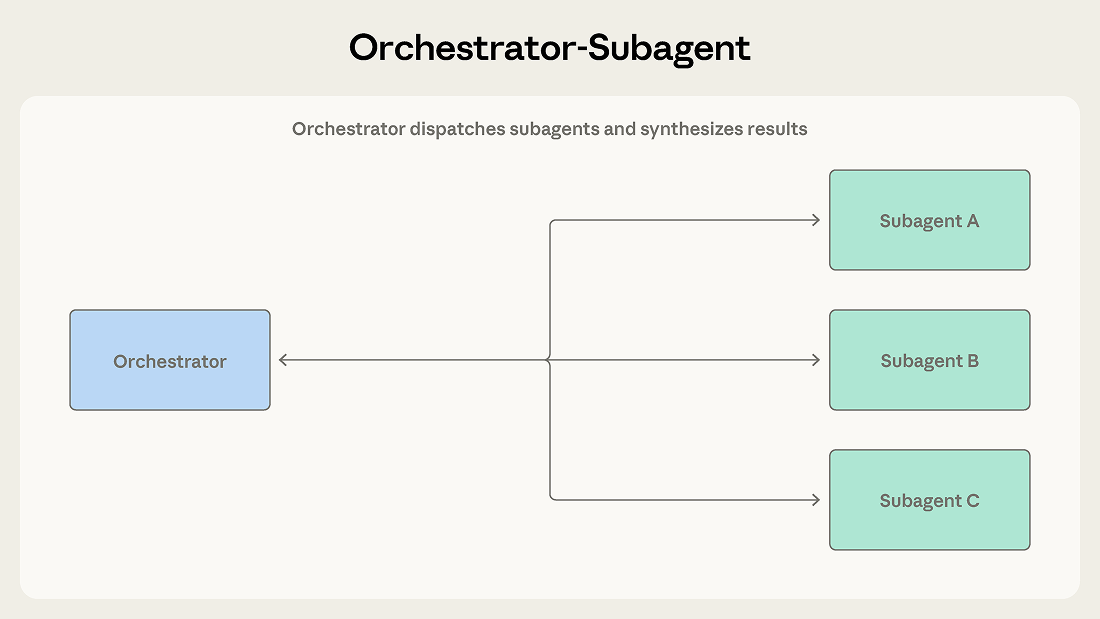
A lead agent receives a task and determines how to approach it. It may handle some subtasks directly while dispatching others to subagents. Subagents complete their work and return results, which the orchestrator synthesizes into a final output.
Claude Code uses this pattern. The main agent writes code, edits files, and runs commands itself, dispatching subagents in the background when it needs to search a large codebase or investigate independent questions so work continues while results stream back. Each subagent operates in its own context window and returns distilled findings. This keeps the orchestrator's context focused on the primary task while exploration happens in parallel.
模式二:编排器-子智能体
层级结构定义了这种模式。一个智能体充当团队领导,负责规划工作、分派任务并汇总结果。子智能体处理具体职责并向其汇报。
工作方式
一个主智能体接收任务并决定如何执行。它可能直接处理部分子任务,同时将其他子任务分派给子智能体。子智能体完成工作后返回结果,由编排器整合为最终输出。
Claude Code 就采用此模式。主智能体自己写代码、编辑文件、运行命令,同时在后天派发子智能体用于搜索大型代码库或调查独立问题,这样在结果源源不断返回的同时,工作可以继续推进。每个子智能体在自己的上下文窗口中运行,并返回提炼后的发现。这让编排器的上下文专注于主要任务,而探索则在后台并行进行。
Where it works well
Consider an automated code review system. When a pull request arrives, the system needs to check for security vulnerabilities, verify test coverage, assess code style, and evaluate architectural consistency. Each check is distinct, requires different context, and produces a clear output. An orchestrator dispatches each check to a specialized subagent, collects the results, and synthesizes a unified review.
Use this pattern when task decomposition is clear and subtasks have minimal interdependence. The orchestrator maintains a coherent view of the overall goal while subagents stay focused on specific responsibilities.
Where it struggles
The orchestrator becomes an information bottleneck. When a subagent discovers something relevant to another subagent's work, that information has to travel back through the orchestrator. If the security subagent finds an authentication flaw that affects the architecture subagent's analysis, the orchestrator must recognize this dependency and route the information appropriately. After several such handoffs, critical details are often lost or summarized away.
Sequential execution also limits throughput. Unless explicitly parallelized, subagents run one after another, meaning the system incurs multi-agent token costs without the speed benefit.
适用场景
以一个自动化代码审查系统为例。当一个拉取请求(PR)到来时,系统需要检查安全漏洞、验证测试覆盖率、评估代码风格和架构一致性。每项检查都各不相同,需要不同的上下文,并能产生清晰的输出。编排器将每项检查分派给专门的子智能体,收集结果,然后整合成统一的审查意见。
使用此模式的条件是:任务分解清晰,且子任务之间依赖最小。编排器保持对整体目标的连贯视图,而子智能体专注于各自的职责。
局限
编排器会成为信息瓶颈。当一个子智能体发现与另一个子智能体工作相关的信息时,该信息必须通过编排器来传递。如果安全子智能体发现了一个影响架构子智能体分析的认证缺陷,编排器必须识别出这种依赖关系并正确路由信息。经过几次这样的传递之后,关键细节常常会丢失或被过度概括。
顺序执行也会限制吞吐量。除非显式并行化,否则子智能体是一个接一个地运行,也就是说,系统承受了多智能体的 token 成本却享受不到速度上的收益。
Pattern 3: Agent teams
When work decomposes into parallel subtasks that can proceed independently for extended periods, orchestrator-subagent can become unnecessarily constraining.
How it works
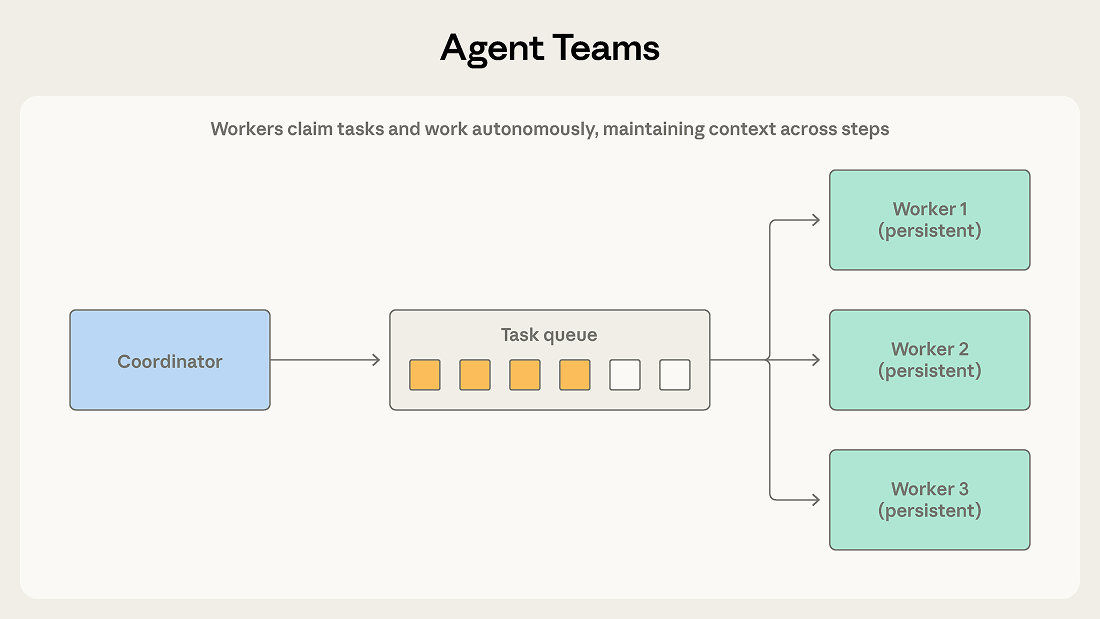
A coordinator spawns multiple worker agents as independent processes. Teammates claim tasks from a shared queue, work on them autonomously across multiple steps, and signal completion.
The difference from orchestrator-subagent is worker persistence. The orchestrator spawns a subagent for one bounded subtask, and the subagent terminates after returning a result. Teammates stay alive across many assignments, accumulating context and domain specialization that improve their performance over time. The coordinator assigns work and collects outcomes but doesn't reset workers between tasks.
模式三:智能体团队
当工作可以分解为能独立长时间运行的并行子任务时,编排器-子智能体模式会变得不必要的局限。
工作方式
协调器将多个工作智能体作为独立进程启动。团队成员从共享队列中领取任务,自主地跨多个步骤工作,并标记完成。
与编排器-子智能体的区别在于工作智能体的持久化。编排器为一个有界的子任务生成一个子智能体,该子智能体在返回结果后就终止了。团队成员则跨多个任务持续活跃,积累上下文和领域专长,从而随着时间的推移提升性能。协调器分配工作并收集结果,但不会在任务之间重置工作智能体。
Where it works well
Consider migrating a large codebase from one framework to another. A teammate can migrate each service independently, with its own dependencies, test suite, and deployment configuration. A coordinator assigns each service to a teammate, and each teammate works through the migration autonomously: dependency updates, code changes, test fixes, validation. The coordinator collects completed migrations and runs integration tests across the full system.
Use this pattern when subtasks are independent and benefit from sustained, multi-step work. Each teammate builds up context about its domain rather than starting fresh with each dispatch.
Where it struggles
Independence is the critical requirement. Unlike orchestrator-subagent, where the orchestrator can mediate between subagents and route information, teammates operate autonomously and can't easily share intermediate findings. If one teammate's work affects another's, neither is aware, and their outputs may conflict.
Completion detection is also harder. Since teammates work autonomously for variable durations, the coordinator must handle partial completion where one teammate finishes in two minutes and another takes twenty.
Shared resources compound both problems. When multiple teammates operate on the same codebase, database, or file system, two teammates may edit the same file or make incompatible changes. The pattern requires careful task partitioning and conflict resolution mechanisms.
适用场景
以将一个大型代码库从一个框架迁移到另一个框架为例。团队中的一个成员可以独立迁移每个服务,该服务拥有自己的依赖项、测试套件和部署配置。协调器将每个服务分配给一位成员,每位成员自主完成迁移工作:依赖更新、代码变更、测试修复、验证。协调器收集完成的迁移任务并运行整个系统的集成测试。
使用此模式的条件是:子任务之间相互独立,并能从持续的多步骤工作中受益。每位成员逐渐积累起与其领域相关的上下文,而不是每次派发都从头开始。
局限
独立性是关键要求。与编排器-子智能体模式不同——后者编排器可以在子智能体之间进行调解和信息路由——团队成员自主运行,不能轻易共享中间发现。如果一位成员的工作影响了另一位,两者都不知道,他们的输出可能相互冲突。
完成检测也更困难。由于团队成员自主工作且持续时间各不相同,协调器必须处理部分完成的情况:一个成员两分钟就完成,另一个却需要二十分钟。
共享资源会加剧这两个问题。当多个成员在同一个代码库、数据库或文件系统上操作时,两个成员可能会编辑同一个文件或做出不兼容的更改。该模式需要精心划分子任务并配备冲突解决机制。
Pattern 4: Message bus
As agent count increases and interaction patterns grow complex, direct coordination becomes difficult to manage. A message bus introduces a shared communication layer where agents publish and subscribe to events.
How it works
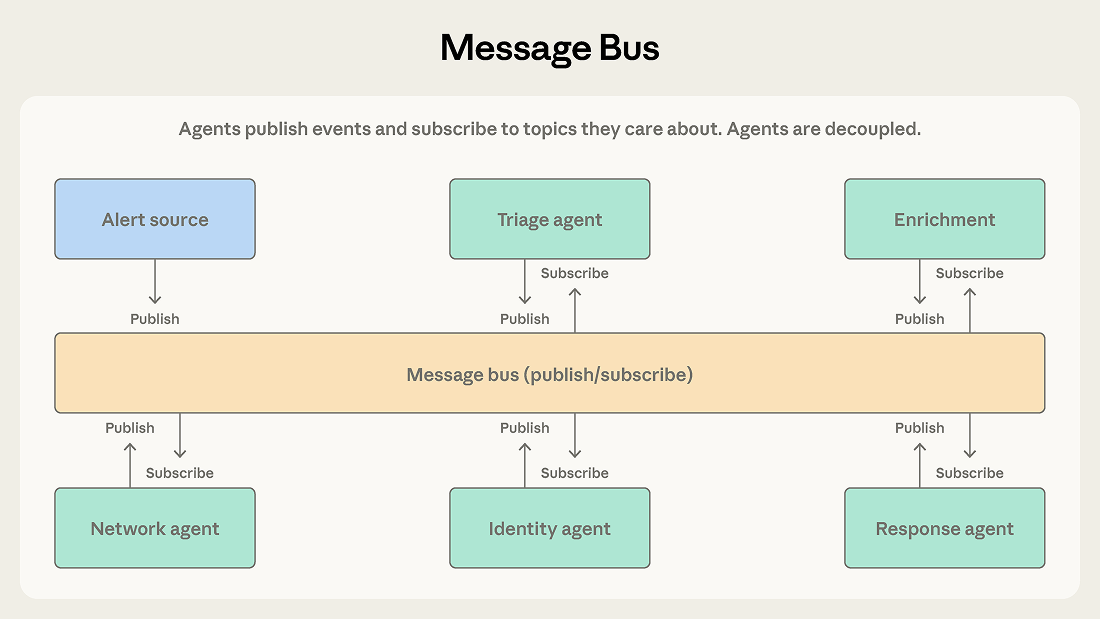
Agents interact through two primitives: publish and subscribe. Agents subscribe to the topics they care about, and a router delivers matching messages. New agents with new capabilities can start receiving relevant work without rewiring existing connections.
Where it works well
A security operations automation system demonstrates where this pattern excels. Alerts arrive from multiple sources, and a triage agent classifies each by severity and type, routing high-severity network alerts to a network investigation agent and credential-related alerts to an identity analysis agent. Each investigation agent may publish enrichment requests that a context-gathering agent fulfills. Findings flow to a response coordination agent that determines the appropriate action.
This pipeline suits the message bus because events flow from one stage to the next, teams can add new agent types as threat categories evolve, and teams can develop and deploy agents independently.
Use this pattern for event-driven pipelines where the workflow emerges from events rather than a predetermined sequence, and where the agent ecosystem is likely to grow.
模式四:消息总线
随着智能体数量增加、交互模式变得复杂,直接的协调将难以管理。消息总线引入了一个共享的通信层,智能体可以发布和订阅事件。
工作方式
智能体通过两种原语进行交互:发布和订阅。智能体订阅自己关心的话题,路由器将匹配的消息投递给他们。新的智能体具备新的能力后,无需重新连接现有系统即可开始接收相关工作。
适用场景
安全运营自动化系统体现了这种模式的优越之处。告警从多个来源到达,一个分诊智能体按严重程度和类型对每条告警进行分类,将高严重性网络告警路由给网络调查智能体,将凭证相关的告警路由给身份分析智能体。每个调查智能体可能会发布扩增请求,由上下文收集智能体来执行。发现结果再流向响应协调智能体,由其决定采取何种行动。
这条流水线非常适合消息总线:事件从上一个阶段流向下一个阶段,团队可以随着威胁类型的演变添加新的智能体类型,并且可以独立开发和部署智能体。
使用此模式的条件是事件驱动的流水线,其中的工作流由事件驱动而非预定顺序,并且智能体生态很可能会不断增长。
Where it struggles
The flexibility of event-driven communication makes tracing harder. When an alert triggers a cascade of events across five agents, understanding what happened requires careful logging and correlation. Debugging is harder than following an orchestrator's sequential decisions.
Routing accuracy is also critical. If the router misclassifies or drops an event, the system fails silently, handling nothing but never crashing. LLM-based routers provide semantic flexibility but introduce their own failure modes.
Pattern 5: Shared state
局限
事件驱动通信的灵活性使得追踪变得更难。当一个告警触发了跨越五个智能体的事件级联时,理解发生了什么需要仔细的记录和关联。调试比跟踪编排器的顺序决策要困难得多。
路由的准确性也至关重要。如果路由器错误分类或丢弃了一个事件,系统会静默地失效:什么也没处理,但从不崩溃。基于 LLM 的路由器提供了语义灵活性,但也引入了自己特有的失败模式。
模式五:共享状态
Pattern 5: Shared state
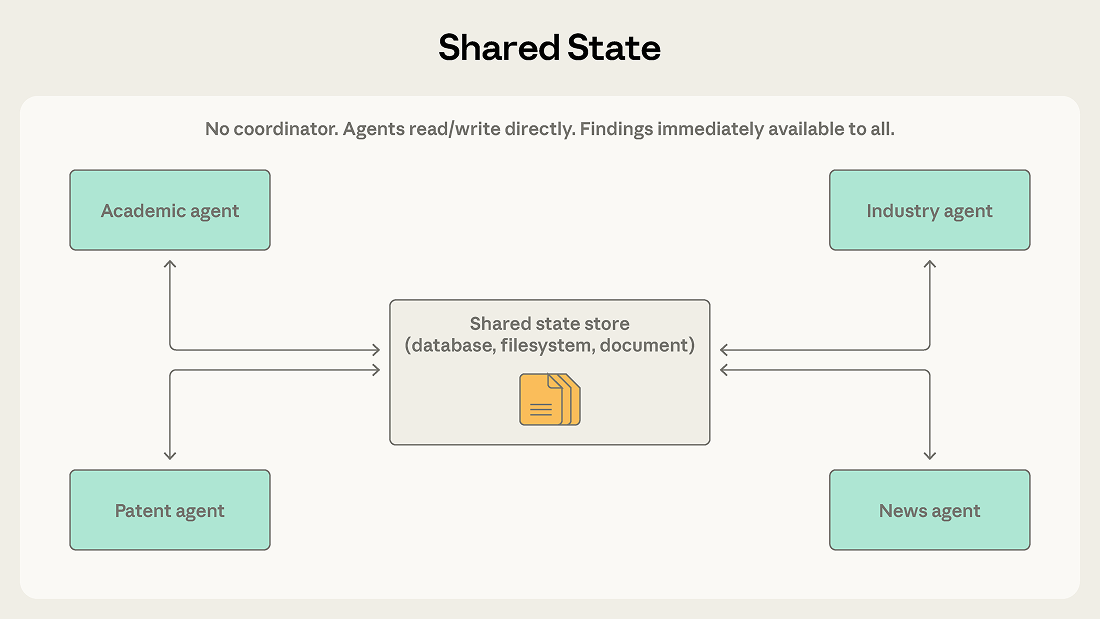
Orchestrators, team leads, and message routers in the previous patterns all centrally manage information flow. Shared state removes the intermediary by letting agents coordinate through a persistent store that all can read and write directly.
How it works
Agents operate autonomously, reading from and writing to a shared database, file system, or document. There's no central coordinator. Agents check the store for relevant information, act on what they find, and write their findings back. Work typically begins when an initialization step seeds the store with a question or dataset, and ends when a termination condition is met: a time limit, a convergence threshold, or a designated agent determining the store contains a sufficient answer.
Where it works well
Consider a research synthesis system where multiple agents investigate different aspects of a complex question. One explores academic literature, another analyzes industry reports, a third examines patent filings, a fourth monitors news coverage. Each agent's findings may inform the others' investigations. The academic literature agent might discover a key researcher whose company the industry agent should examine more closely.
With shared state, findings go directly into the store. The industry agent can see the academic agent's discoveries immediately, without waiting for a coordinator to route the information. Agents build on each other's work, and the shared store becomes an evolving knowledge base.
Shared state also removes the coordinator as a single point of failure. If any one agent stops, the others continue reading and writing. In orchestrator and message-bus systems, a coordinator or router failure halts everything.
模式五:共享状态
在前面的模式中,编排器、团队领导和消息路由器都集中管理信息流。共享状态则移除了中间环节,让智能体通过一个所有智能体都能直接读写持久存储层来进行协调。
工作方式
智能体自主运行,读写一个共享的数据库、文件系统或文档。没有中央协调器。智能体检查存储中是否有相关信息,根据发现执行操作,并将结果写回。工作通常始于一个初始化步骤向存储中填充一个问题或数据集,并结束于满足某个终止条件:时限、收敛阈值,或者某个指定智能体判定存储中已包含足够答案。
适用场景
以一个研究综合系统为例,多个智能体调查一个复杂问题的不同方面。一个探索学术文献,另一个分析行业报告,第三个审查专利文件,第四个监控新闻报道。每个智能体的发现都可能为其他智能体的调查提供信息。学术文献智能体可能发现一位关键研究员,行业智能体就应该更仔细地研究他所在的公司。
有了共享状态,发现结果直接写入存储。行业智能体可以立即看到学术智能体的发现,而无需等待协调器路由信息。智能体彼此在对方的工作基础上推进,共享存储成为一个不断演进的知识库。
共享状态还消除了协调器这个单点故障。如果任何一个智能体停止工作,其他智能体仍能继续读写。而在编排器和消息总线系统中,协调器或路由器一旦故障,整个系统就会停止运转。
Where it struggles
Without explicit coordination, agents may duplicate work or pursue contradictory approaches. Two agents might independently investigate the same lead. Agent interactions produce system behavior rather than top-down design, which makes outcomes less predictable.
The harder failure mode is reactive loops. For example, Agent A writes a finding, Agent B reads it and writes a follow-up, Agent A sees the follow-up and responds. The system keeps burning tokens on work that isn't converging. Duplicate work and concurrent writes have known engineering fixes (locking, versioning, partitioning). Reactive loops are a behavioral problem and need first-class termination conditions: a time budget, a convergence threshold (no new findings for N cycles), or a designated agent whose job is to decide when the store contains a sufficient answer. Systems that treat termination as an afterthought tend to cycle indefinitely or stop arbitrarily when one agent's context fills.
局限
没有显式协调,智能体可能会重复工作或采取相互矛盾的方法。两个智能体可能会独立调查同一条线索。智能体之间的互动产生的是系统行为,而非自顶向下的设计,这使得结果更难预测。
更棘手的失效模式是反应性循环。例如,智能体 A 写下一个发现,智能体 B 读取后写了一个跟踪操作,智能体 A 看到跟踪操作后又做出响应。系统在无法收敛的工作上不断消耗 token。重复工作和并发写入有已知的工程修复方法(加锁、版本控制、分区)。反应性循环是一个行为问题,需要头等的终止条件:时间预算、收敛阈值(连续 N 个周期没有新的发现),或者一个指定智能体负责判断存储中是否已包含足够答案。将终止视为事后考虑的系统的做法会导致无限循环,或者当某个智能体的上下文填满时随意停下来。
Choosing and evolving between patterns
The right pattern depends on a handful of structural questions about the system. In our previous post, we argued for context-centric decomposition, which divides work by what context each agent needs rather than by what type of work it does. That principle applies here too. The patterns differ in how they manage context boundaries and information flow.
Orchestrator-subagent vs. agent teams
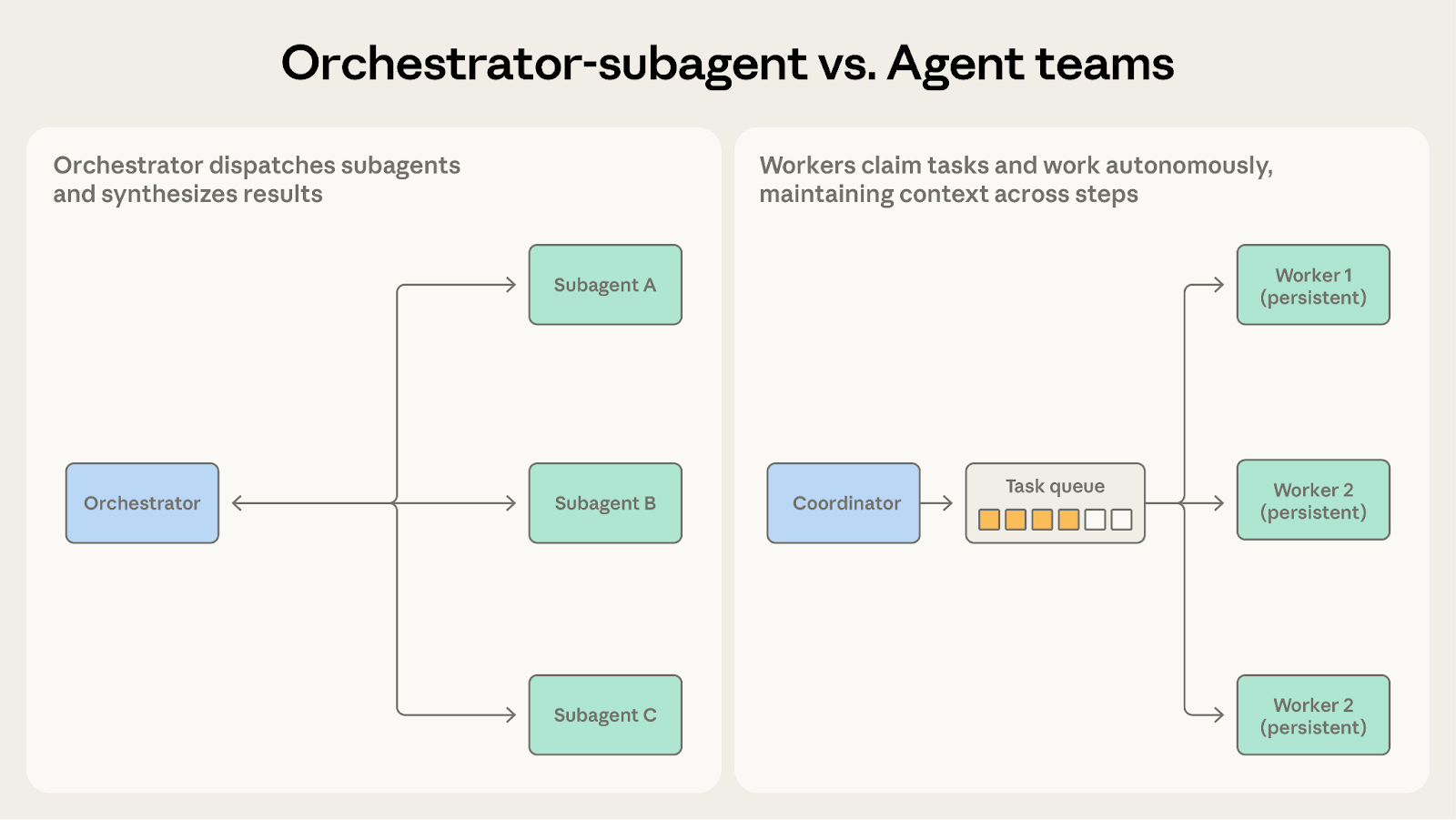
Both involve a coordinator dispatching work to other agents. The question is how long workers need to maintain their context.
Choose orchestrator-subagent when subtasks are short, focused, and produce clear outputs. The code review system works well here because each check runs its analysis, generates a report, and returns within a single bounded invocation. The subagent doesn't need to carry context across multiple cycles.
Choose agent teams when subtasks benefit from sustained, multi-step work. The codebase migration fits here because each teammate develops real familiarity with its assigned service: the dependency graph, test patterns, deployment configuration. That accumulated context improves performance in ways one-shot dispatch can't replicate.
When subagents need to retain state across invocations, agent teams are the better fit.
如何选择和演进模式
正确的模式取决于关于系统的一系列结构性提问。在之前文章中,我们主张以上下文为中心的分解思路:按每个智能体需要什么上下文来划分工作,而不是按工作类型。这个原则在此同样适用。这些模式在管理上下文边界和信息流的方式上各有不同。
编排器-子智能体 vs 智能体团队
两者都涉及协调器向其他智能体分派工作。关键区别在于工作者需要多久地维护其上下文。
子任务短小、专注、产出清晰时选择编排器-子智能体。代码审查系统就很适合:每项检查运行其分析、生成报告,并在一次有界调用中返回。子智能体不需要跨多个周期保持上下文。
子任务从持续的多步骤工作中受益时选择智能体团队。代码库迁移就属于这种情况:每位团队成员对其被分配的服务形成了真正的熟悉程度:依赖图、测试模式、部署配置。这种积累起来的上下文能提升性能,这是一次性派发无法复制的。
当子智能体需要跨调用保留状态时,智能体团队是更合适的选择。
Orchestrator-subagent vs. message bus
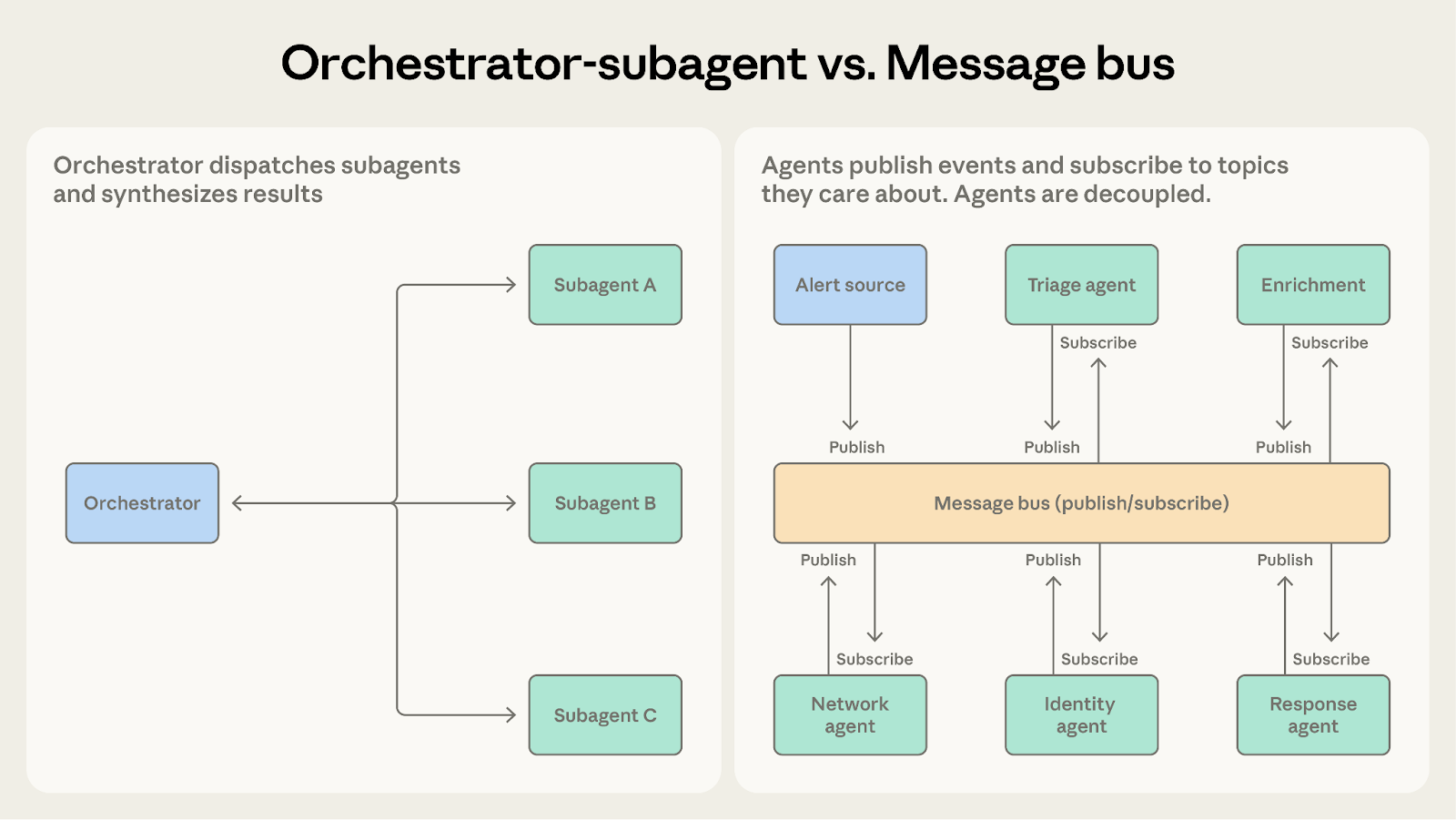
Both can handle multi-step workflows. The question is how predictable the workflow structure is.
Choose orchestrator-subagent when the sequence of steps is known in advance. The code review system follows a fixed pipeline: receive a PR, run checks, synthesize results.
Choose message bus when the workflow emerges from events and may vary based on what's discovered. The security operations system can't predict what alerts will arrive or what investigation paths they'll require. New alert types may emerge that need new handling. The message bus accommodates that variability by routing events to capable agents rather than following a predetermined sequence.
As conditional logic accumulates in the orchestrator to handle an expanding variety of cases, the message bus makes that routing explicit and extensible.
编排器-子智能体 vs 消息总线
两者都可以处理多步骤工作流。关键区别在于工作流结构的可预测性。
步骤次序事先已知时选择编排器-子智能体。代码审查系统遵循一个固定的流水线:接收 PR,运行检查,综合结果。
工作流由事件驱动且可能因发现了什么而变化时选择消息总线。安全运营系统无法预测哪些告警会到达,也无法预测它们需要什么调查路径。新的告警类型可能出现,需要新的处理方式。消息总线通过将事件路由给有能力的智能体来适应这种变化,而不遵循预定顺序。
当编排器中积累的条件逻辑越来越多,以应对不断扩展的各种情况时,消息总线使这种路由显式化且可扩展。
Agent teams vs. shared state
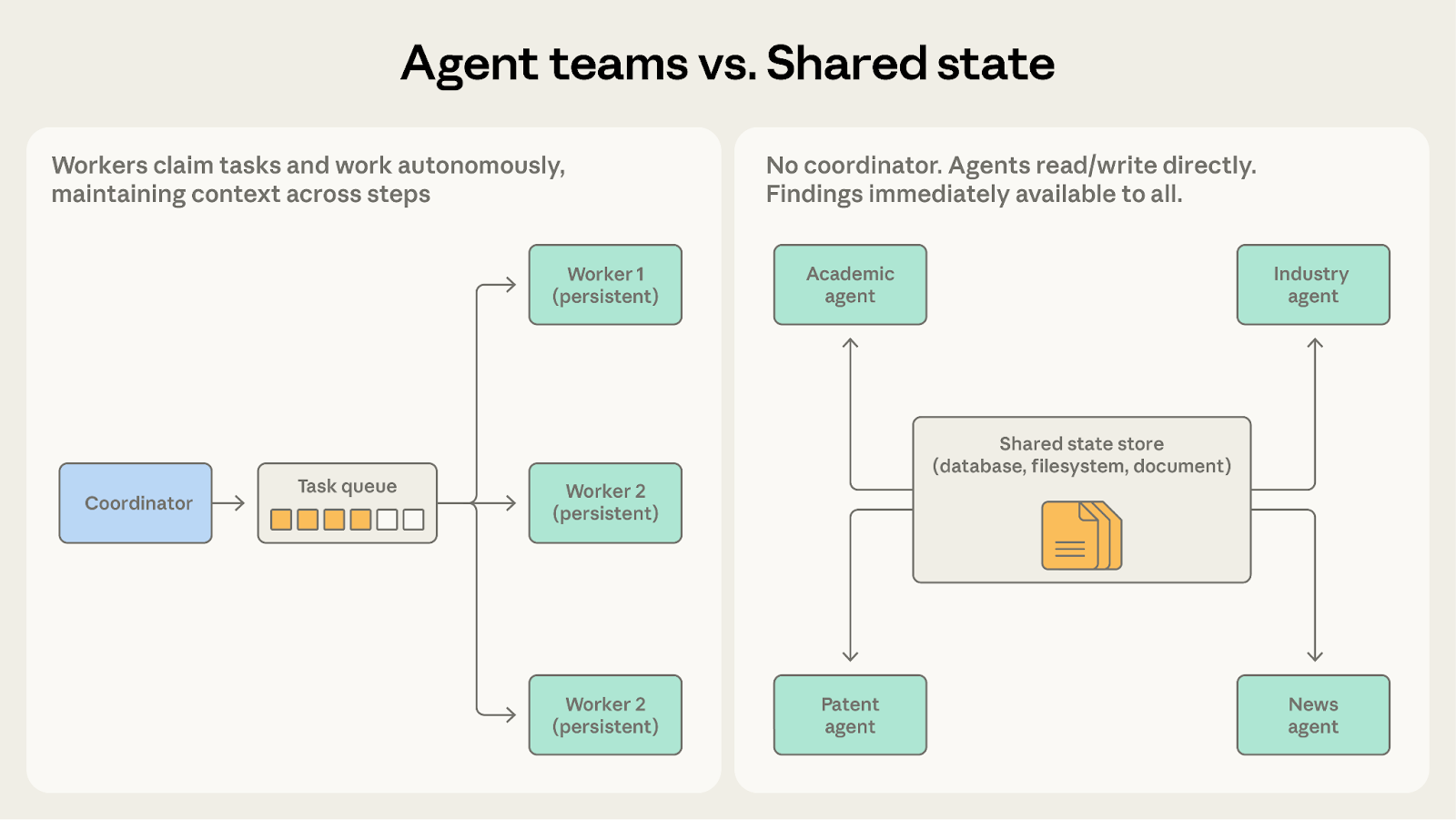
Both involve agents working autonomously. The question is whether agents need each other's findings.
Choose agent teams when agents work on separate partitions that don't interact. The codebase migration fits here because each teammate handles its service and the coordinator combines results at the end.
Choose shared state when agents' work is collaborative and findings should flow between them in real time. The research synthesis system is a better match because the academic agent's discovery of a key researcher immediately becomes relevant to the industry agent's investigation.
Once teammates need to communicate with each other rather than only share final results, shared state makes that more natural.
Message bus vs. shared state
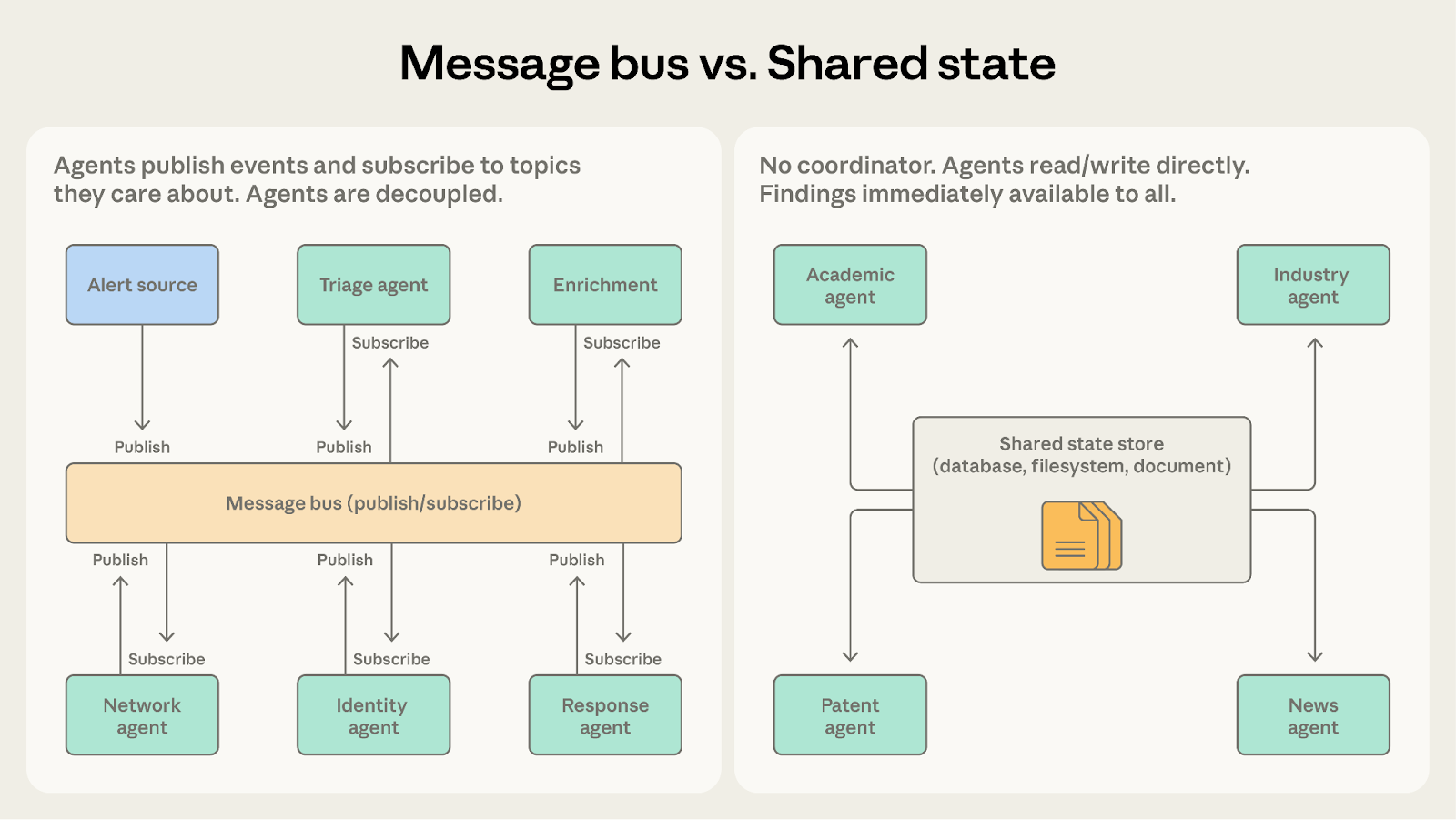
Both support complex multi-agent coordination. The question is whether work flows as discrete events or accumulates into a shared knowledge base.
Choose message bus when agents react to events in a pipeline. The security operations system processes alerts stage by stage, with each event triggering the next before completing. The pattern is efficient at routing events to capable agents.
Choose shared state when agents build on accumulated findings over time. The research synthesis system gathers knowledge continuously. Agents return to the store repeatedly, seeing what others have discovered and adjusting their investigations.
The message bus still has a router, which means a central component decides where events go. Shared state is decentralized. If eliminating single points of failure is a priority, shared state provides that more completely.
If agents in a message bus system are publishing events to share findings rather than trigger actions, shared state is a better fit.
智能体团队 vs 共享状态
两者都涉及智能体自主工作。关键区别是智能体是否需要彼此之间的发现结果。
当智能体在互不交互的独立分区上工作时选择智能体团队。代码库迁移就是如此:每位成员处理自己的服务,协调器在最后汇总结果。
当智能体的工作是协作性的,并且发现结果之间应该实时流动时选择共享状态。研究综合系统更合适,因为学术智能体发现了一位关键研究员,这立即对行业智能体的调查产生了影响。
一旦团队成员之间需要互相通信——而不仅仅共享最终结果——共享状态能让这一点更加自然。
消息总线 vs 共享状态
两者都支持复杂的多智能体协调。关键区别在于工作是作为离散事件流动,还是累积成一个共享的知识库。
智能体在流水线中对事件做出反应时选择消息总线。安全运营系统逐阶段处理告警,每个事件在完成前触发下一个。该模式能高效地将事件路由给有能力处理的智能体。
智能体随着时间的推移在累积发现的基础上推进时选择共享状态。研究综合系统持续收集知识。智能体反复回到存储中,查看其他人发现了什么,并调整自己的调查。
消息总线仍然有一个路由器,这意味着存在一个中心组件决定事件去向何处。共享状态是去中心化的。如果消除单点故障是优先事项,共享状态能更彻底地满足这一要求。
如果消息总线系统中的智能体发布事件是为了共享发现而不是触发动作,那共享状态是更好的选择。
Getting started
Production systems often combine patterns. A common hybrid uses orchestrator-subagent for the overall workflow with shared state for a collaboration-heavy subtask. Another uses message bus for event routing with agent team-style workers handling each event type. These patterns are building blocks, not mutually exclusive choices.
The following table summarizes when each pattern is appropriate.
Situation Pattern
Quality-critical output, explicit evaluation criteria Generator-Verifier
Clear task decomposition, bounded subtasks Orchestrator-Subagent
Parallel workload, independent long-running subtasks Agent Teams
Event-driven pipeline, growing agent ecosystem Message Bus
Collaborative research, agents share discoveries Shared State
No single point of failure required Shared State
For most use cases, we recommend starting with orchestrator-subagent. It handles the widest range of problems with the least coordination overhead. Observe where it struggles, then evolve toward other patterns as specific needs become clear.
In upcoming posts, we will examine each pattern in depth with production implementations and case studies. For background on when multi-agent systems are worth the investment, see Building multi-agent systems: when and how to use them.
Acknowledgements
Written by Cara Phillips, with contributions from Eugene Yan, Jiri De Jonghe, Samuel Weller, and Erik S.
起步建议
生产系统通常会组合多种模式。一种常见的混合方式是:用编排器-子智能体处理整体工作流,同时用共享状态处理协作密集型的子任务。另一种做法是用消息总线进行事件路由,同时用工智能体团队风格的工作者处理每种事件类型。这些模式是构建模块,而非互斥的选择。
下表总结了每种模式适用的情形。
情形 模式
质量要求高、评估标准明确的输出 生成器-验证器
任务分解清晰、子任务有界 编排器-子智能体
并行工作负载、独立的长时间运行子任务 智能体团队
事件驱动的流水线、不断增长的智能体生态 消息总线
协作研究、智能体共享发现 共享状态
需避免单点故障 共享状态
对于大多数用例,我们建议从编排器-子智能体开始。它覆盖最广范围的问题,协调开销也最小。观察它在哪些方面运转不畅,然后随着具体需求的明确再向其他模式演进。
在接下来的文章中,我们将通过生产实现和案例研究深入剖析每种模式。关于多智能体系统何时值得投入的背景,请参见《构建多智能体系统:何时以及如何使用它们》。
致谢
作者:Cara Phillips,感谢 Eugene Yan、Jiri De Jonghe、Samuel Weller 和 Erik S. 的贡献。