Why Your “AI-First” Strategy Is Probably Wrong
The CTO of an agent platform shares their journey of rebuilding the entire engineering workflow around AI: 99% of production code is written by AI, shipping features within a day. The article critiques the superficial “AI-assisted” approach and introduces “harness engineering,” detailing their tech stack, self-healing feedback loop, and the new engineer roles of Architect and Operator. Real-world results include 3–8 deployments per day. Valuable for teams and CTOs seeking genuine AI integration.
99% of our production code is written by AI. Last Tuesday, we shipped a new feature at 10 AM, A/B tested it by noon, and killed it by 3 PM because the data said no. We shipped a better version at 5 PM. Three months ago, a cycle like that would have taken six weeks.
We didn't get here by adding Copilot to our IDE. We dismantled our engineering process and rebuilt it around AI. We changed how we plan, build, test, deploy, and organize the team. We changed the role of everyone in the company.
CREAO is an agent platform. Twenty-five employees, 10 engineers. We started building agents in November 2025, and two months ago I restructured the entire product architecture and engineering workflow from the ground up.
OpenAI published a concept in February 2026 that captured what we'd been doing. They called it harness engineering: the primary job of an engineering team is no longer writing code. It is enabling agents to do useful work. When something fails, the fix is never "try harder." The fix is: what capability is missing, and how do we make it legible and enforceable for the agent?
We arrived at that conclusion on our own. We didn't have a name for it.

我们 99% 的生产代码是由 AI 编写的。上周二,我们上午 10 点发布了一个新功能,中午进行 A/B 测试,下午 3 点因为数据不理想就终止了它。下午 5 点我们发布了更好的版本。三个月前,这样的周期需要六周。
我们不是靠在 IDE 里加 Copilot 走到这一步的。我们拆解了原有工程流程,围绕 AI 重新构建。我们改变了计划、构建、测试、部署的方式,也重塑了团队组织和每个人的角色。
CREAO 是一个智能体平台。公司只有 25 人,10 名工程师。我们从 2025 年 11 月开始构建智能体,两个月前我彻底重构了产品架构和工程流程。
OpenAI 在 2026 年 2 月发表了一个概念,精准概括了我们一直在做的事:驾驭工程(harness engineering)——工程团队的主要工作不再是编写代码,而是让智能体能够完成有用工作。当出问题时,改进方法不是“更努力”,而是找出缺失了哪种能力,以及如何让这种能力对智能体变得清晰且可执行。
我们自己也得出了同样的结论,只是没给它命名。

Most companies bolt AI onto their existing process. An engineer opens Cursor. A PM drafts specs with ChatGPT. QA experiments with AI test generation. The workflow stays the same. Efficiency goes up 10 to 20 percent. Nothing structurally changes.
That is AI-assisted.
AI-first means you redesign your process, your architecture, and your organization around the assumption that AI is the primary builder. You stop asking "how can AI help our engineers?" and start asking "how do we restructure everything so AI does the building, and engineers provide direction and judgment?"
The difference is multiplicative.
I see teams claim AI-first while running the same sprint cycles, the same Jira boards, the same weekly standups, the same QA sign-offs. They added AI to the loop. They didn't redesign the loop.
A common version of this is what people call vibe coding. Open Cursor, prompt until something works, commit, repeat. That produces prototypes. A production system needs to be stable, reliable, and secure. You need a system that can guarantee those properties when AI writes the code. You build the system. The prompts are disposable.
大多数公司只是把 AI 嫁接到现有流程上:工程师使用 Cursor,PM 用 ChatGPT 起草规格,QA 尝试 AI 生成测试。流程照旧,效率提升 10%–20%,但结构上没有任何改变。
这就是 AI 辅助。
AI 优先则意味着,你假设 AI 是主要构建者,并据此重新设计流程、架构和组织。你不再问“AI 如何帮助工程师?”,而是问“我们如何重构一切,让 AI 负责构建,工程师提供方向和判断?”
两者之间的差异是倍增级的。
我看到有团队自称 AI 优先,却依然维持相同的 Sprint 周期、Jira 看板、每周站会和 QA 签字流程。他们只是在既有循环里加入了 AI,而没有重新设计这个循环。
常见的一种做法是人们所说的“氛围编码”:打开 Cursor,不断用提示词直到跑通,然后提交,如此反复。这只能产出原型。生产系统需要稳定、可靠和安全。你必须构建一个系统,当 AI 写代码时能确保这些属性。系统是构建出来的,提示词则是消耗品。
Last year, I watched how our team worked and saw three bottlenecks that would kill us.
The Product Management Bottleneck
Our PMs spent weeks researching, designing, specifying features. Product management has worked this way for decades. But agents can implement a feature in two hours. When build time collapses from months to hours, a weeks-long planning cycle becomes the constraint.
It doesn't make sense to think about something for months and then build it in two hours.
PMs needed to evolve into product-minded architects who work at the speed of iteration, or step out of the build cycle. Design needed to happen through rapid prototype-ship-test-iterate loops, not specification documents reviewed in committee.
The QA Bottleneck
Same dynamic. After an agent shipped a feature, our QA team spent days testing corner cases. Build time: two hours. Test time: three days.
We replaced manual QA with AI-built testing platforms that test AI-written code. Validation has to move at the same speed as implementation. Otherwise you've built a new bottleneck ten feet downstream from the old one.
The Headcount Bottleneck
Our competitors had 100x or more people doing comparable work. We have 25. We couldn't hire our way to parity. We had to redesign our way there.
Three systems needed AI running through them: how we design product, how we implement product, and how we test product. If any single one stays manual, it constrains the whole pipeline.
去年我观察团队的工作方式,发现三个瓶颈会拖垮我们。
产品管理瓶颈
我们的 PM 花数周时间调研、设计、撰写功能规格。产品管理这么干了几十年。但智能体可以用两小时实现一个功能。当构建时间从几个月缩短到几小时,长达数周的规划周期就成了瓶颈。
花几个月时间去思考,然后用两小时去构建,这没有意义。
PM 需要进化为具备产品思维的架构师,能以迭代速度工作,否则就得退出构建循环。设计应当通过快速的原型-发布-测试-迭代循环来完成,而不是通过委员会审阅的规格文档。
QA 瓶颈
同样的困境。智能体交付一个功能后,QA 团队花几天时间测试边界情况。构建时间两小时,测试时间三天。
我们用 AI 构建的测试平台取代了人工 QA,让它去测试 AI 写的代码。验证速度必须与实现速度匹配,否则你只是在下游十英尺处制造了一个新瓶颈。
人力瓶颈
竞争对手有百倍甚至更多的人员在做类似工作。我们只有 25 人。我们无法通过招聘来拉平差距,只能通过重新设计来实现。
有三个系统必须让 AI 贯穿其中:产品设计方式、产品实现方式和产品测试方式。任何一个环节保持人工,就会制约整个流水线。
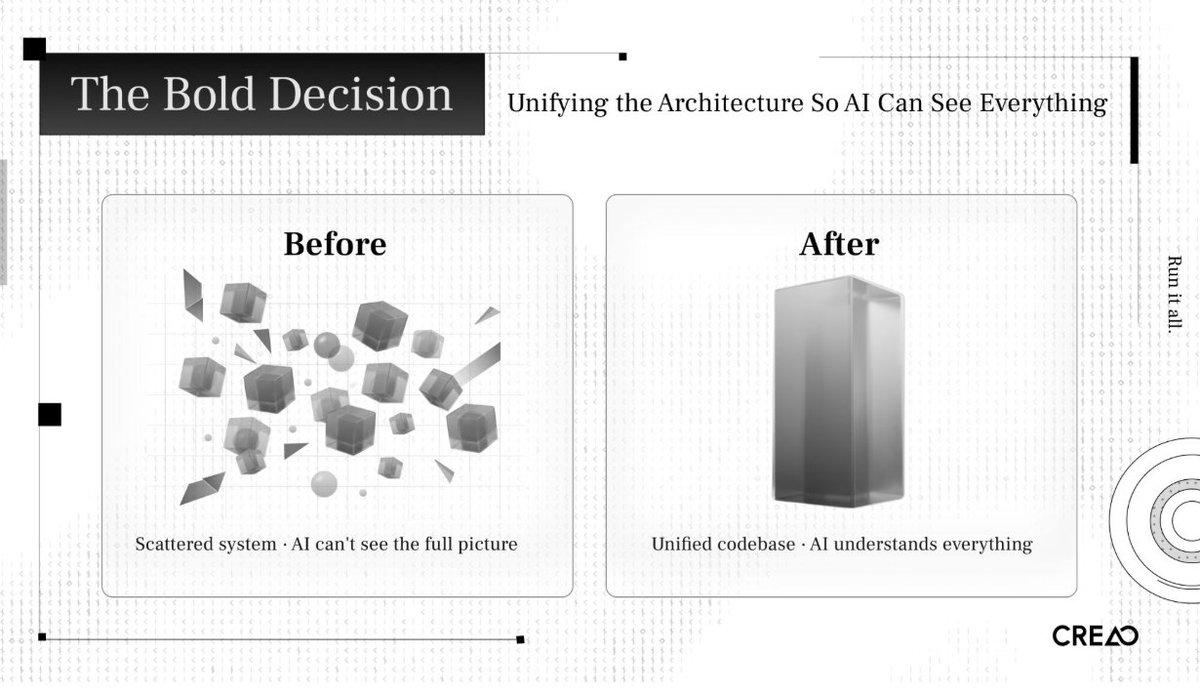
I had to fix the codebase first.
Our old architecture was scattered across multiple independent systems. A single change might require touching three or four repositories. From a human engineer's perspective, it is manageable. From an AI agent's perspective, opaque. The agent can't see the full picture. It can't reason about cross-service implications. It can't run integration tests locally.
I had to unify all the code into a single monorepo. One reason: so AI could see everything.
This is a harness engineering principle in practice. The more of your system you pull into a form the agent can inspect, validate, and modify, the more leverage you get. A fragmented codebase is invisible to agents. A unified one is legible.
I spent one week designing the new system: planning stage, implementation stage, testing stage, integration testing stage. Then another week re-architecting the entire codebase using agents.
CREAO is an agent platform. We used our own agents to rebuild the platform that runs agents. If the product can build itself, it works.
我必须先搞定代码库。
我们的旧架构散落在多个独立系统里。一个改动可能需要碰三四个代码仓库。从人类工程师角度看,这能对付;但从 AI 智能体角度看,这是不透明的。智能体看不到全貌,无法推理跨服务的影响,也无法在本地运行集成测试。
我必须把所有代码统一到一个单体仓库里。原因之一:让 AI 能看见一切。
这是驾驭工程原则在实践中的体现。你越将系统纳入智能体可以检查、验证和修改的形式,得到的杠杆就越大。碎片化的代码库对智能体来说是不可见的,统一的则是可读的。
我花了一周设计新系统:规划阶段、实现阶段、测试阶段、集成测试阶段。然后又花了一周时间,用智能体重新架构了整个代码库。
CREAO 是个智能体平台。我们用自家智能体重建了运行智能体的平台。如果产品能构建自身,就证明它有效。
Here is our stack and what each piece does.
Infrastructure: AWS
We run on AWS with auto-scaling container services and circuit-breaker rollback. If metrics degrade after a deployment, the system reverts on its own.
CloudWatch is the central nervous system. Structured logging across all services, over 25 alarms, custom metrics queried daily by automated workflows. Every piece of infrastructure exposes structured, queryable signals. If AI can't read the logs, it can't diagnose the problem.
CI/CD: GitHub Actions
Every code change passes through a six-phase pipeline:
Verify CI → Build and Deploy Dev → Test Dev → Deploy Prod → Test Prod → Release
The CI gate on every pull request enforces typechecking, linting, unit and integration tests, Docker builds, end-to-end tests via Playwright, and environment parity checks. No phase is optional. No manual overrides. The pipeline is deterministic, so agents can predict outcomes and reason about failures.
这是我们的技术栈及每部分的作用。
基础设施:AWS
我们在 AWS 上运行,采用自动伸缩的容器服务和断路器回滚机制。如果部署后指标恶化,系统会自动回滚。
CloudWatch 是中枢神经系统。所有服务输出结构化日志,设置了超过 25 个告警,自定义指标每天被自动化工作流查询。每块基础设施都暴露结构化、可查询的信号。如果 AI 读不懂日志,就无法诊断问题。
CI/CD:GitHub Actions
每次代码变更都要经过六阶段流水线:
验证 CI → 构建和部署开发环境 → 测试开发环境 → 部署生产环境 → 测试生产环境 → 发布
每个拉取请求的 CI 关口强制进行类型检查、代码规范检查、单元测试、集成测试、Docker 构建、Playwright 端到端测试以及环境一致性校验。没有任何阶段可跳过,没有人工覆盖。流水线是确定性的,因此智能体可以预测结果并对失败进行推理。
AI Code Review: Claude
Every pull request triggers three parallel AI review passes using Claude Opus 4.6:
Pass 1: Code quality. Logic errors, performance issues, maintainability.
Pass 2: Security. Vulnerability scanning, authentication boundary checks, injection risks.
Pass 3: Dependency scan. Supply chain risks, version conflicts, license issues.
These are review gates, not suggestions. They run alongside human review, catching what humans miss at volume. When you deploy eight times a day, no human reviewer can sustain attention across every PR.
Engineers also tag @claude in any GitHub issue or PR for implementation plans, debugging sessions, or code analysis. The agent sees the whole monorepo. Context carries across conversations.
AI 代码审查:Claude
每个拉取请求都会触发三个并行的 AI 审查流程,使用 Claude Opus 4.6:
第一轮:代码质量。逻辑错误、性能问题、可维护性。
第二轮:安全。漏洞扫描、认证边界检查、注入风险。
第三轮:依赖扫描。供应链风险、版本冲突、许可证问题。
这些是审查关口,而非建议。它们与人工审查并行运行,能在大量提交中捕捉人类遗漏的问题。当你一天部署八次时,没有人类审查者能对每个 PR 保持全神贯注。
工程师还可以在任何 GitHub 问题或 PR 中 @claude,以获取实现计划、调试会话或代码分析。智能体能看到整个单体仓库,上下文在对话中延续。
The Self-Healing Feedback Loop
This is the centerpiece.
Every morning at 9:00 AM UTC, an automated health workflow runs. Claude Sonnet 4.6 queries CloudWatch, analyzes error patterns across all services, and generates an executive health summary delivered to the team via Microsoft Teams. Nobody had to ask for it.
One hour later, the triage engine runs. It clusters production errors from CloudWatch and Sentry, scores each cluster across nine severity dimensions, and auto-generates investigation tickets in Linear. Each ticket includes sample logs, affected users, affected endpoints, and suggested investigation paths.
The system deduplicates. If an open issue covers the same error pattern, it updates that issue. If a previously closed issue recurs, it detects the regression and reopens.
When an engineer pushes a fix, the same pipeline handles it. Three Claude review passes evaluate the PR. CI validates. The six-phase deploy pipeline promotes through dev and prod with testing at each stage. After deployment, the triage engine re-checks CloudWatch. If the original errors are resolved, the Linear ticket auto-closes.

Each tool handles one phase. No tool tries to do everything. The daily cycle creates a self-healing loop where errors are detected, triaged, fixed, and verified with minimal manual intervention.
I told a reporter from Business Insider: "AI will make the PR and the human just needs to review whether there's any risk."
自愈反馈循环
这是核心部分。
每天 UTC 上午 9:00,自动化健康检查工作流启动。Claude Sonnet 4.6 查询 CloudWatch,分析所有服务的错误模式,生成一份执行健康摘要,通过 Microsoft Teams 递送给团队。谁也没要求,它就自动来了。
一小时后,分类引擎运行。它将来自 CloudWatch 和 Sentry 的生产错误聚类,对每个聚类在九个严重性维度上打分,并在 Linear 中自动生成调查工单。每个工单包含示例日志、受影响的用户和端点,以及建议的调查路径。
系统会去重。如果已有一个开放工单覆盖相同错误模式,它就更新该工单。如果之前关闭的工单再次发生,它会检测到回归并重新打开。
当工程师推送修复时,同一条流水线接管。三轮 Claude 审查评估 PR,CI 验证通过,六阶段部署流水线依次推进开发和生产环境并测试。部署后,分类引擎重新检查 CloudWatch,如果原始错误已解决,Linear 工单自动关闭。
每个工具处理一个阶段,没有任何工具试图包揽一切。这个每日循环创造了一个自愈回路:错误被检测、分类、修复和验证,都只需最低限度的人工干预。
我告诉《商业内幕》的记者:“AI 会生成 PR,人类只需审查是否存在风险。”
Feature Flags and the Supporting Stack
Statsig handles feature flags. Every feature ships behind a gate. The rollout pattern: enable for the team, then gradual percentage rollout, then full release or kill. The kill switch toggles a feature off instantly, no deploy needed. If a feature degrades metrics, we pull it within hours. Bad features die the same day they ship. A/B testing runs through the same system.
Graphite manages PR branching: merge queues rebase onto main, re-run CI, merge only if green. Stacked PRs allow incremental review at high throughput.
Sentry reports structured exceptions across all services, merged with CloudWatch by the triage engine for cross-tool context. Linear is the human-facing layer: auto-created tickets with severity scores, sample logs, and suggested investigation. Deduplication prevents noise. Follow-up verification auto-closes resolved issues.
功能标志与支持栈
Statsig 负责功能标志。每个功能都在一个开关后发布。发布模式:对团队内部开启,然后按百分比逐步放量,最后全量或终止。终止开关可以瞬间关闭功能,无需重新部署。如果功能使指标恶化,我们几小时内就撤回。差劲的功能在发布当天就会被毙掉。A/B 测试通过同一系统运行。
Graphite 管理 PR 分支:合并队列先变基到主分支,重新运行 CI,只有全部通过才合并。堆叠 PR 允许在高吞吐量下进行增量审查。
Sentry 报告所有服务的结构化异常,由分类引擎与 CloudWatch 合并以获取跨工具上下文。Linear 是面向人工的层面:自动创建的工单附带严重性评分、示例日志和建议调查方向。去重减少噪音;跟踪验证自动关闭已解决的问题。
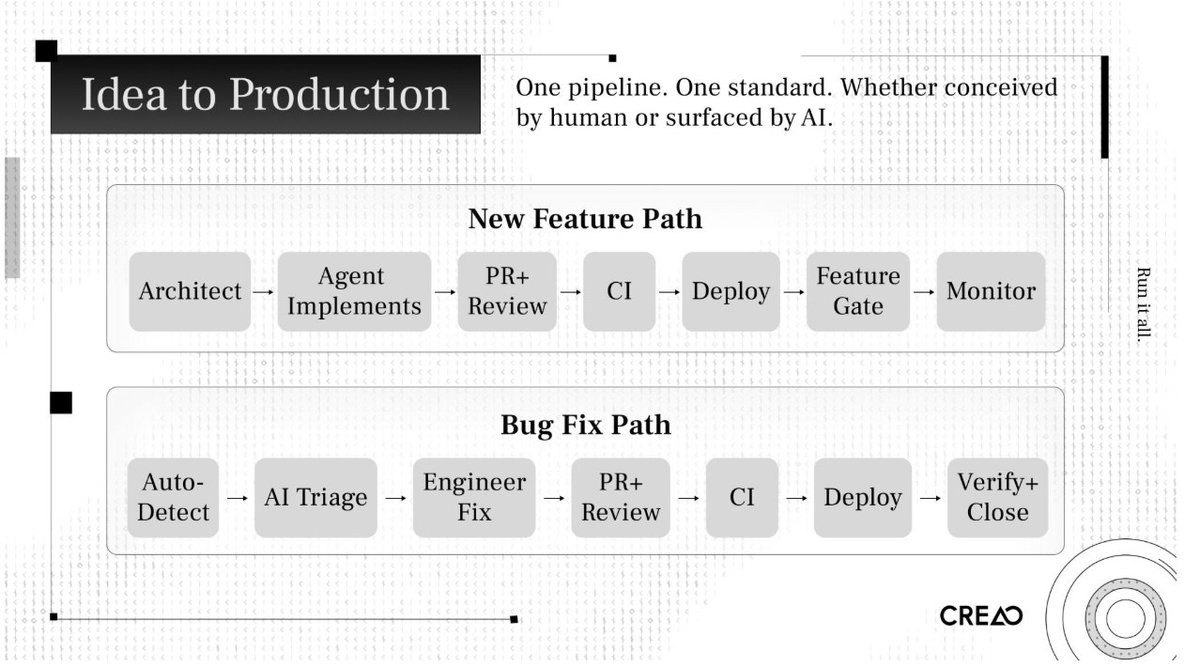
New Feature Path
-
The architect defines the task as a structured prompt with codebase context, goals, and constraints.
-
An agent decomposes the task, plans implementation, writes code, and generates its own tests.
-
A PR opens. Three Claude review passes evaluate it. A human reviewer checks for strategic risk, not line-by-line correctness.
-
CI validates: typecheck, lint, unit tests, integration tests, end-to-end tests.
-
Graphite's merge queue rebases, re-runs CI, merges if green.
-
Six-phase deploy pipeline promotes through dev and prod with testing at each stage.
-
Feature gate turns on for the team. Gradual percentage rollout. Metrics monitored.
-
Kill switch available if anything degrades. Circuit-breaker auto-rollback for severe issues. Bug Fix Path
-
CloudWatch and Sentry detect errors.
-
Claude triage engine scores severity, creates a Linear issue with full investigation context.
-
An engineer investigates. AI has already done the diagnosis. The engineer validates and pushes a fix.
-
Same review, CI, deploy, and monitoring pipeline.
-
Triage engine re-verifies. If resolved, ticket auto-closes. Both paths use the same pipeline. One system. One standard.
新功能路径
- 架构师将任务定义为结构化提示词,包含代码库上下文、目标和约束。
- 智能体分解任务,规划实现,编写代码并生成自己的测试。
- 发起 PR。三轮 Claude 审查评估。人类审查者检查战略风险,而非逐行正确性。
- CI 验证:类型检查、规范检查、单元测试、集成测试、端到端测试。
- Graphite 合并队列变基,重新运行 CI,通过后合并。
- 六阶段部署流水线依次推进开发和生产环境并测试。
- 功能开关对团队开启,按百分比逐步放量,监控指标。
- 一旦有任何恶化,终止开关可用。严重问题时断路器自动回滚。
Bug 修复路径
- CloudWatch 和 Sentry 检测错误。
- Claude 分类引擎评分严重性,在 Linear 中创建包含完整调查上下文的工单。
- 工程师调查。AI 已完成诊断,工程师验证并推送修复。
- 同样的审查、CI、部署和监控流水线。
- 分类引擎重新验证,解决后工单自动关闭。
两条路径共用同一流水线,一套系统,一个标准。
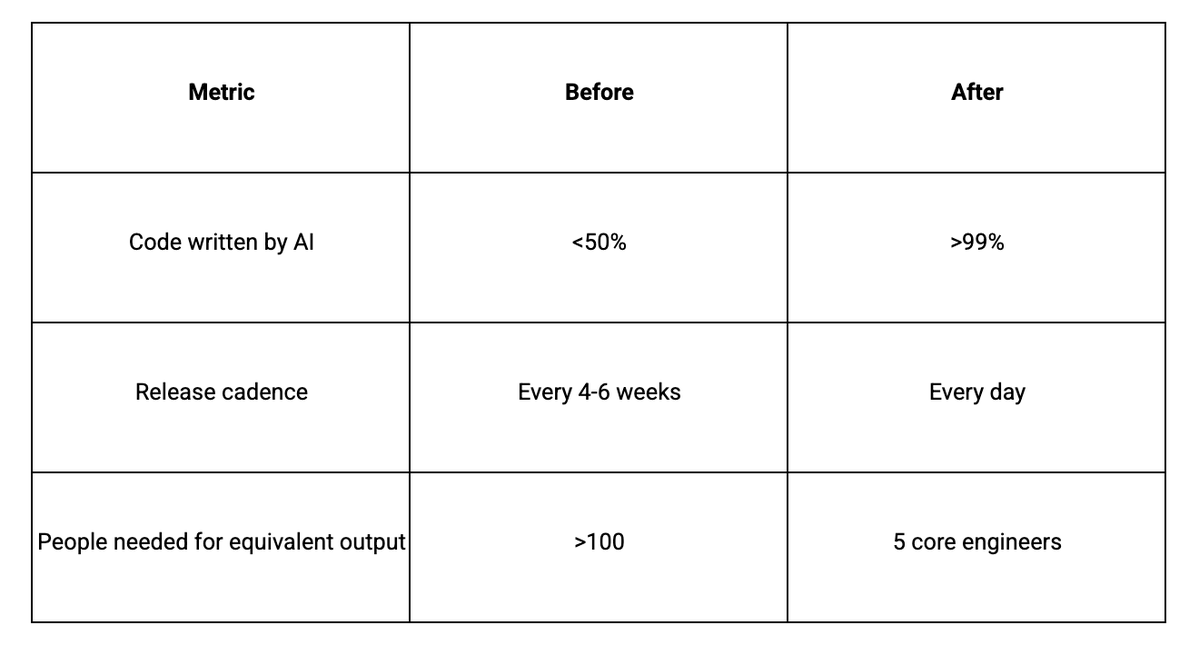
Over 14 days, we averaged three to eight production deployments per day. Under our old model, that entire two-week period would have produced not even a single release to production.
Bad features get pulled the same day they ship. New features go live the same day they're conceived. A/B tests validate impact in real time.
People assume we're trading quality for speed. User engagement went up. Payment conversion went up. We produce better results than before, because the feedback loops are tighter. You learn more when you ship daily than when you ship monthly.
在 14 天内,我们平均每天部署 3 到 8 次生产环境。在旧模式下,那整整两周可能连一次生产发布都没有。
坏功能发布当天就被撤回,新功能产生当天就能上线,A/B 测试实时验证效果。
人们以为我们是用质量换速度,但实际上用户参与度上升了,付费转化率也上升了。我们产出的结果比过去更好,因为反馈回路更紧密了。每天发布学到的东西远比每月发布来得多。
Two types of engineers will exist.
The Architect
One or two people. They design the standard operating procedures that teach AI how to work. They build the testing infrastructure, the integration systems, the triage systems. They decide architecture and system boundaries. They define what "good" looks like for the agents.
This role requires deep critical thinking. You criticize AI. You don't follow it. When the agent proposes a plan, the architect finds the holes. What failure modes did it miss? What security boundaries did it cross? What technical debt is it accumulating?
I have a PhD in physics. The most useful thing my PhD taught me was how to question assumptions, stress-test arguments, and look for what's missing. The ability to criticise AI will be more valuable than the ability to produce code.
This is also the hardest role to fill.
The Operator
Everyone else. The work matters. The structure is different.
AI assigns tasks to humans. The triage system finds a bug, creates a ticket, surfaces the diagnosis, and assigns it to the right person. The person investigates, validates, and approves the fix. AI makes the PR. The human reviews whether there's risk.
The tasks are bug investigation, UI refinement, CSS improvements, PR review, verification. They require skill and attention. They don't require the architectural reasoning the old model demanded.
Who Adapts Fastest
I noticed a pattern I didn't expect. Junior engineers adapted faster than senior engineers.
Junior engineers with less traditional practice felt empowered. They had access to tools that amplified their impact. They didn't carry a decade of habits to unlearn.
Senior engineers with strong traditional practice had the hardest time. Two months of their work could be completed in one hour by AI. That is a hard thing to accept after years of building a rare skill set.
I'm not making a judgment. I'm describing what I observed. In this transition, adaptability matters more than accumulated skill.
未来会存在两类工程师。
架构师
一个团队里有一到两人。他们设计标准操作流程(SOP),教 AI 如何工作;构建测试基础设施、集成系统和分类系统;决定架构和系统边界;定义智能体眼中的“好”标准。
这个角色需要深度批判性思维。你批判 AI,而不是追随它。当智能体提出一个方案,架构师要找出漏洞:它忽略了哪些故障模式?越过了哪些安全边界?累积了哪些技术债?
我拥有物理学博士学位,博士生涯教会我最有用的事,就是如何质疑假设、压力测试论证、寻找遗漏点。批判 AI 的能力将比产出代码的能力更有价值。
这也是最难招到的角色。
操作员
其他人都是操作员。工作依然重要,但结构不同。
AI 向人类分配任务。分类系统发现一个 bug,创建工单,呈现诊断结果,并指派给合适的人。那人调查、验证、批准修复。AI 生成 PR,人类审查是否有风险。
任务包括 bug 调查、UI 细化、CSS 改进、PR 审查和验证。这些任务需要技能和专注,但不需要旧模式所要求的架构推理能力。
谁适应得最快
我观察到一种出乎意料的模式:初级工程师比高级工程师适应得更快。
传统实践较少的初级工程师感到被赋能了。他们获得了能放大自己影响力的工具,也没有十年养成的习惯需要摒弃。
传统实践扎实的高级工程师则最为挣扎。他们两个月的工作, AI 一小时就能完成。这对于多年积累稀缺技能的人来说很难接受。
我并非在做评判,只是在描述观察到的现象。在这个转型期,适应能力比积累的技能更重要。
Management Collapsed
Two months ago, I spent 60% of my time managing people. Aligning priorities. Running meetings. Giving feedback. Coaching engineers.
Today: below 10%.
The traditional CTO model says to empower your team to do architecture work, train them, delegate. But if the system only needs one or two architects, I need to do it myself first. I went from managing to building. I code from 9 AM to 3 AM most days. I design the SOPs and architecture of the system. I maintain the harness.
More stressful. But I'm enjoying building, not aligning.
Less Arguing, Better Relationships
My relationships with co-founders and engineers are better than before.
Before the transition, most of my interaction with the team was alignment meetings. Discussing trade-offs. Debating priorities. Disagreeing about technical decisions. Those conversations are necessary in a traditional model. They're also draining.
Now I still talk to my team. We talk about other things. Non-work topics. Casual conversations. Offsite trips. We get along better because we stopped arguing about work that can be easily done by our system.
Uncertainty Is Real
I won't pretend everyone is happy.
When I stopped talking to people every day, some team members felt uncertain. What does the CTO not talking to me mean? What is my value in this new world? Reasonable concerns.
Some people spend more time debating whether AI can do their work than doing the work. The transition period creates anxiety. I don't have a clean answer for it.
I do have a principle: we don't fire an engineer because they introduced a production bug. We improve the review process. We strengthen testing. We add guardrails. The same applies to AI. If AI makes a mistake, we build better validation, clearer constraints, stronger observability.
管理崩塌
两个月前,我 60% 的时间花在管理人上:对齐优先级、开会、给反馈、辅导工程师。
如今这一比例不到 10%。
传统的 CTO 模式说,要赋能团队做架构工作,培养他们,授权他们。但如果系统只需要一两位架构师,我首先得自己干。我从管理转向了构建。大多数日子我会从早 9 点码到凌晨 3 点。我设计系统的 SOP 和架构,维护这套驾驭体系。
压力更大,但我享受构建,而不是对齐。
争论减少,关系变好
我与联合创始人及工程师的关系比以前更好了。
转型前,我与团队的大部分互动都是对齐会议:讨论权衡、辩论优先级、在技术决策上产生分歧。这些对话在传统模式下是必要的,也让人精疲力竭。
现在我仍和团队交流,但我们聊别的事情:非工作话题、闲聊、团建出游。我们相处得更好,因为不再为那些可以被系统轻易完成的工作争吵了。
不确定性真实存在
我不会假装每个人都很开心。
当我停止每天和人们交谈时,一些团队成员感到不安:CTO 不和我说话意味着什么?我在新世界里有什么价值?这些都是合理的关切。
有些人花在争论 AI 能否做自己工作上的时间,比做工作本身还多。转型期会带来焦虑,对此我没有干净的答案。
但有一条原则:我们不会因为工程师引入一个生产 bug 就解雇他,而是改进审查流程、加强测试、增加护栏。同样适用于 AI。如果 AI 犯了错,我们就构建更好的验证、更清晰的约束、更强大的可观测性。
I see other companies adopt AI-first engineering and leave everything else manual.
If engineering ships features in hours but marketing takes a week to announce them, marketing is the bottleneck. If the product team still runs a monthly planning cycle, planning is the bottleneck.
At CREAO, we pushed AI-native operations into every function:
- Product release notes: AI-generated from changelogs and feature descriptions.
- Feature intro videos: AI-generated motion graphics.
- Daily posts on socials: AI-orchestrated and auto-published.
- Health reports and analytics summaries: AI-generated from CloudWatch and production databases. Engineering, product, marketing, and growth run in one AI-native workflow. If one function operates at agent speed and another at human speed, the human-speed function constrains everything.
我看到有些公司工程部门变成 AI 优先,但其他部门还是老样子。
如果工程能在几小时内交付特性,而市场营销要一周才能发布公告,那么市场营销就是瓶颈。如果产品团队仍然按月做规划,那么规划就是瓶颈。
在 CREAO,我们将 AI 原生操作推入每个职能:
- 产品发布说明:AI 根据变更日志和功能描述生成。
- 功能介绍视频:AI 生成的动态图形。
- 社交媒体每日帖子:AI 编排并自动发布。
- 健康报告和分析摘要:AI 从 CloudWatch 和生产数据库生成。 工程、产品、营销和增长都在同一个 AI 原生工作流中运行。如果某个职能以智能体速度工作,而另一个却以人类速度,那么人类速度的那个就会约束一切。
For Engineers
Your value is moving from code output to decision quality. The ability to write code fast is worth less every month. The ability to evaluate, criticize, and direct AI is worth more.
Product sense or taste matters. Can you look at a generated UI and know it's wrong before the user tells you? Can you look at an architecture proposal and see the failure mode the agent missed?
I tell our 19-year-old interns: train critical thinking. Learn to evaluate arguments, find gaps, question assumptions. Learn what good design looks like. Those skills compound.
For CTOs and Founders
If your PM process takes longer than your build time, start there.
Build the testing harness before you scale agents. Fast AI without fast validation is fast-moving technical debt.
Start with one architect. One person who builds the system and proves it works. Onboard others into operator roles after the system runs.
Push AI-native into every function.
Expect resistance. Some people will push back.
For the Industry
OpenAI, Anthropic, and multiple independent teams converged on the same principles: structured context, specialized agents, persistent memory, and execution loops. Harness engineering is becoming a standard.
Model capability is the clock driving this. I attribute the entire shift at CREAO to the last two months. Opus 4.5 couldn't do what Opus 4.6 does. Next-gen models will accelerate it further.
I believe one-person companies will become common. If one architect with agents can do the work of 100 people, many companies won't need a second employee.
给工程师
你的价值正从代码产出转向决策质量。写代码快的价值每月都在缩水,而评估、批判和指导 AI 的价值则在上升。
产品感觉或品味至关重要。你能看着生成的 UI 就知道它有问题,而无需等用户反馈吗?你能看着架构提案,就发现智能体遗漏的故障模式吗?
我告诉公司 19 岁的实习生:训练批判性思维,学会评估论证、发现漏洞、质疑假设,搞明白什么是好的设计。这些能力会不断复利。
给 CTO 和创始人
如果产品管理流程比构建时间还长,就从那里下手。
在规模化智能体之前,先构建测试驾驭体系。没有快速验证的快节奏 AI 只是在快速积累技术债。
从一位架构师开始,让他构建系统并证明其有效,在系统跑起来后再引导其他人进入操作员角色。
将 AI 原生推动到每一个职能。
预计会遭遇抵制,有些人会推回去。
给行业
OpenAI、Anthropic 以及多个独立团队殊途同归:结构化上下文、专业化智能体、持久记忆和执行循环。驾驭工程正在成为一种标准。
模型能力是背后的时钟。我将 CREAO 的全部转变归功于过去两个月——Opus 4.5 做不到 Opus 4.6 所做的事情。下一代模型只会进一步加速。
我相信一人公司将会常见。如果一位架构师加上智能体就能完成 100 人的工作,许多公司就不再需要第二个员工。
Most founders and engineers I talk to still operate the traditional way. Some think about making the shift. Very few have done it.
A reporter friend told me she'd talked to about five people on this topic. She said we were further along than anyone: "I don't think anyone's just totally rebuilt their entire workflow the way you have."
The tools exist for any team to do this. Nothing in our stack is proprietary.
The competitive advantage is the decision to redesign everything around these tools, and the willingness to absorb the cost. The cost is real: uncertainty among employees, the CTO working 18-hour days, senior engineers questioning their value, a two-week period where the old system is gone and the new one isn't proven.
We absorbed that cost. Two months later, the numbers speak.
We build an agent platform. We built it with agents.
我聊过的大多数创始人和工程师仍在用传统方式。有些人考虑转型,但很少有人已经做到。
一位记者朋友告诉我,她大概和五个人聊过这个话题。她说我们走得比谁都远:“我不认为有人像你们那样彻底重建了整个工作流。”
工具任何团队都能用,我们的技术栈里没有专有组件。
竞争优势在于下定决心围绕这些工具重新设计一切,以及愿意承受代价。代价是真实的:员工中的不确定性,CTO 每天工作 18 小时,资深工程师质疑自己的价值,还有两周时间旧系统已不复存在、新系统尚未验证。
我们承受了这个代价。两个月后,数字说明了一切。
我们构建智能体平台,并用智能体构建了它。