Claude Code in Large Codebases: Best Practices and Getting Started
This article covers how Claude Code navigates large codebases using agentic search instead of RAG indexing, avoiding stale index issues but requiring good context configuration. It details the 'harness' ecosystem around the model—CLAUDE.md, Hooks, Skills, Plugins, MCP servers, LSP integration, and subagents—and presents three configuration patterns from successful deployments: making the codebase navigable, maintaining CLAUDE.md as models evolve, and assigning ownership for rollout. A practical guide for teams adopting Claude Code at scale.
Claude Code navigates a codebase the way a software engineer would: it traverses the file system, reads files, uses grep to find exactly what it needs, and follows references across the codebase. It operates locally on the developer’s machine and doesn’t require a codebase index to be built, maintained, or uploaded to a server.
RAG-powered AI coding tools work by embedding the entire codebase and retrieving relevant chunks at query time. At large scale, those systems can fail because embedding pipelines can’t keep up with active engineering teams. By the time a developer queries the index, it reflects the codebase as it previously existed weeks, days, or even hours before. Retrieval then returns a function the team renamed two weeks ago, or references a module that was deleted in the last sprint, with no indication that either is out of date.
Agentic search avoids those failure modes. There's no embedding pipeline or centralized index to maintain as thousands of engineers commit new code. Each developer's instance works from the live codebase.
But the approach has a tradeoff: it works best when Claude has enough starting context to know where to look. This means the quality of Claude's navigation is shaped by how well the codebase is set up, layering context with CLAUDE.md files and skills.
Claude Code 像软件工程师一样遍历代码库:它遍历文件系统、读取文件、使用 grep 精确查找所需内容,并在整个代码库中跟踪引用。它在开发者的本地机器上运行,无需构建、维护或上传代码库索引到服务器。
基于 RAG 的 AI 编码工具通过嵌入整个代码库并在查询时检索相关片段。在大规模场景下,这些系统可能会失败,因为嵌入流水线跟不上活跃工程团队的节奏。当开发者查询索引时,它反映的是几周、几天甚至几小时前的代码状态。检索结果可能返回团队两周前重命名的函数,或引用上个迭代已删除的模块,而没有任何过期提示。
代理搜索避免了这些失败模式。无需维护嵌入流水线或中央索引——即使数千名工程师持续提交新代码。每个开发者的实例都基于实时代码库工作。
但这种方法也有取舍:当 Claude 拥有足够的起始上下文来知道在哪里查找时,效果最佳。这意味着 Claude 的导航质量取决于代码库的配置程度——通过 CLAUDE.md 文件和技能层层叠加上下文。
One of the most common misconceptions about Claude Code is that its capabilities are solely defined by the model used. Teams focus on a model’s benchmarks and how it performs on test tasks. In practice, the ecosystem built around the model—the harness—determines how Claude Code performs more than the model alone.
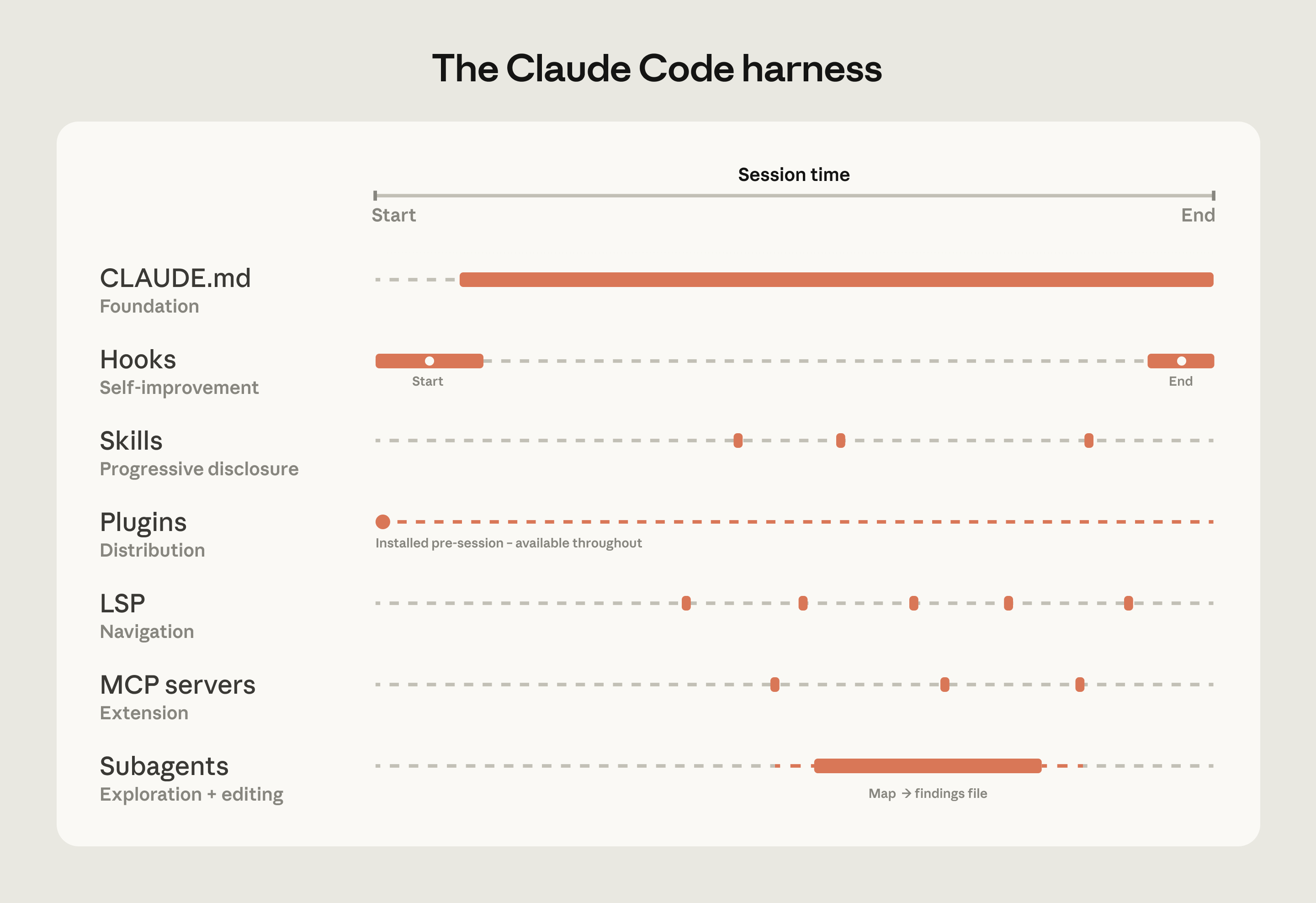
The table below summarizes what each component does, when it loads, and the most common mistakes we see with each: [table omitted for brevity, but in full version include markdown table]
关于 Claude Code 最常见的误解之一是其能力完全由所用模型决定。团队关注模型的基准测试和在测试任务中的表现。但实际上,围绕模型构建的生态系统——扩展层——比模型本身更能决定 Claude Code 的实际表现。
下表总结了每个组件的功能、加载时机以及我们常看到的错误:[为简洁省略表格,但完整版应包含Markdown表格]
CLAUDE.md files come first. These are context files that Claude reads automatically at the start of every session: root file for the big picture, subdirectory files for local conventions. They give Claude the codebase knowledge it needs to do anything well. Because they load in every session regardless of the task, keeping them focused on what applies broadly will prevent them from becoming a drag on performance.
CLAUDE.md 文件是首要的。这些是 Claude 在每次会话开始时自动读取的上下文文件:根目录文件提供全局概况,子目录文件提供局部惯例。它们为 Claude 提供做好任何事情所需的代码库知识。由于它们无论任务如何都会加载,让它们聚焦于广泛适用的内容可以避免成为性能拖累。
Hooks make the setup self-improving. Most teams think of hooks as scripts that prevent Claude from doing something wrong, but their more valuable use is continuous improvement. A stop hook can reflect on what happened during a session and propose CLAUDE.md updates while the context is fresh. A start hook can load team-specific context dynamically so every developer gets the right setup for their module without manual configuration. For automated checks like linting and formatting, hooks enforce the rules deterministically and produce more consistent results than relying on Claude to remember an instruction.
Hook 让配置能够自我改进。大多数团队将 Hook 视为防止 Claude 做错事的脚本,但它们更有价值的用途是持续改进。停止钩子可以反思会话期间发生了什么,并在上下文仍然新鲜时提出 CLAUDE.md 更新。启动钩子可以动态加载团队特定的上下文,使每个开发者无需手动配置就能获得其模块的正确设置。对于代码检查和格式化等自动化检查,挂钩确定性执行规则,比依赖 Claude 记住指令产生更一致的结果。
Skills keep the right expertise available on-demand without bloating every session. In a large codebase with dozens of task types, not all expertise needs to be present in every session. Skills solve this through progressive disclosure, offloading specialized workflows and domain knowledge that would otherwise compete for context space and loading them only when the task calls for it. For example, a security review skill loads when Claude is assessing code for vulnerabilities, while a document processing skill loads when a code change is made and documentation needs to be updated.
Skills can also be scoped to specific paths so they only activate in the relevant part of the codebase.
技能确保在需要时提供正确的专业知识,而不会让每次会话膨胀。在包含数十种任务类型的大型代码库中,并非所有专业知识都需要出现在每次会话中。技能通过渐进式披露解决这个问题:将专门的工作流和领域知识卸载,仅在任务需要时才加载,从而避免占用上下文空间。例如,安全审查技能在 Claude 评估代码漏洞时加载,文档处理技能在代码变更需要更新文档时加载。
技能还可以限定在特定路径,使其仅在代码库的相关部分激活。
Plugins distribute what works. One challenge with large codebases is that good setups can stay tribal. A plugin bundles skills, hooks, and MCP configurations into a single installable package, so when a new engineer installs that plugin on day one, they will immediately have the same context and capabilities as those who have been using Claude already. Plugin updates can be distributed across the organization through managed marketplaces.
插件分发有效配置。大型代码库的一个挑战是好的配置可能停留在小圈子。插件将技能、钩子和 MCP 配置打包成一个可安装的包,使新工程师在第一天安装该插件后,立即拥有与老用户相同的上下文和能力。插件更新可以通过托管市场在组织内分发。
Language server protocol (LSP) integrations give Claude the same navigation a developer has in their IDE. Most large-codebase IDEs already have an LSP running, powering "go to definition" and "find all references." Surfacing this to Claude gives it symbol-level precision: it can follow a function call to its definition, trace references across files, and distinguish between identically named functions in different languages. Without it, Claude pattern-matches on text and can land on the wrong symbol.
语言服务器协议(LSP)集成为 Claude 提供开发者在其 IDE 中拥有的相同导航能力。大多数大型代码库的 IDE 已经运行着 LSP,支持“转到定义”和“查找所有引用”。将其暴露给 Claude 可实现符号级精度:它可以跟踪函数调用到其定义,跨文件追踪引用,并区分不同语言中同名函数。没有 LSP,Claude 将基于文本模式匹配,可能定位到错误的符号。
MCP servers extend everything. MCP servers are how Claude connects to internal tools, data sources, and APIs that it can't otherwise reach. The most sophisticated teams built MCP servers exposing structured search as a tool Claude can call directly. Others connect Claude to internal documentation, ticketing systems, or analytics platforms.
MCP 服务器扩展一切。MCP 服务器是 Claude 连接内部工具、数据源和 API 的方式。最成熟的团队构建了将结构化搜索暴露为工具的 MCP 服务器,Claude 可以直接调用。其他人则连接 Claude 到内部文档、工单系统或分析平台。
A subagent is an isolated Claude instance with its own context window that takes a task, does the work, and returns only the final result to the parent. Once the harness is in place, some teams spin up a read-only subagent to map a subsystem and write findings to a file, then have the main agent edit with the full picture.
子代理是一个独立的 Claude 实例,拥有自己的上下文窗口,它接受任务、完成工作,并将最终结果返回给父实例。一旦扩展层就位,一些团队启动只读子代理来映射子系统并将发现写入文件,然后让主代理在拥有全局信息的情况下进行编辑。
Keeping CLAUDE.md files lean and layered. Claude loads them additively as it moves through the codebase: root file for the big picture, subdirectory files for local conventions. The root file should be pointers and critical gotchas only.
Initializing in subdirectories, not at the repo root. Claude works best when it's scoped to the part of the codebase that's actually relevant to the task.
Scoping test and lint commands per subdirectory.
Using .ignore files to exclude generated files, build artifacts, and third-party code.
Building codebase maps when the directory structure doesn’t do the work.
Running LSP servers so Claude searches by symbol, not by string.
保持 CLAUDE.md 文件简洁且分层。Claude 在代码库中移动时增量加载它们:根目录文件提供全局信息,子目录文件提供局部约定。根目录文件应仅包含指向和关键陷阱。
在子目录中初始化,而不是在仓库根目录。当 Claude 限定在与任务相关的代码库部分时,效果最佳。
为每个子目录限定测试和 lint 命令。
使用 .ignore 文件排除生成文件、构建产物和第三方代码。
当目录结构不足以指导时,构建代码库地图。
运行 LSP 服务器,使 Claude 按符号搜索而非字符串匹配。
As models evolve, instructions written for your current model can work against a future one. CLAUDE.md files that guided Claude through patterns it used to struggle with may either become unnecessary or actively constraining when the next model ships. Skills and hooks built to compensate for specific model limitations become overhead once those limitations no longer exist.
Teams should expect to do a meaningful configuration review every three to six months, but it's also worth doing one whenever performance feels like it's plateaued after major model releases.
随着模型进化,为当前模型编写的指令可能会对未来的模型产生反作用。引导 Claude 克服旧模型困境的 CLAUDE.md 文件,在新模型发布后可能变得不必要甚至成为约束。为弥补特定模型限制而构建的技能和钩子,一旦这些限制不复存在,就会变成开销。
团队应预期每三到六个月进行一次有意义的配置审查,同时在主要模型发布后感觉性能停滞时也值得审查一次。
Technical configuration alone doesn't drive adoption. The rollouts that spread fastest had a dedicated infrastructure investment before broad access. A small team, sometimes even just one person, wired up the tooling so Claude already fit developer workflows when they first touched it.
An emerging role in several organizations is an agent manager: a hybrid PM/engineer function dedicated to managing the Claude Code ecosystem.
Bottoms-up adoption generates enthusiasm but can fragment without someone to centralize what works. In large organizations, governance questions come up early: who controls skills/plugins, how to prevent duplicate efforts, how to ensure AI-generated code undergoes review.
We’ve observed the smoothest deployments at organizations that establish cross-functional working groups early.
仅靠技术配置无法推动采用。推广最快的组织在开放广泛访问之前就投入了专门的基础设施。一个小团队,有时甚至一个人,配置好工具,使 Claude 在开发者第一次使用时就已经适应其工作流。
多个组织中涌现出一个新角色:Agent 管理员——兼具 PM 和工程师职能,专门管理 Claude Code 生态系统。
自下而上的采用能激发热情,但如果没有集中协调,知识会碎片化。在大型组织中,治理问题很早就会出现:谁控制技能/插件,如何避免重复工作,如何确保 AI 生成的代码经过审查。
我们观察到最顺利的部署发生在早期就建立跨职能工作组的组织中。