How to Master Dynamic Workflows in Claude Code: 6 Patterns and 14 Steps
This article provides a systematic guide to Dynamic Workflows in Claude Code, shipped in late May 2026. It moves beyond manual prompt chaining by letting Claude generate a bespoke JavaScript harness for a specific task. The author first explains the mental model: how workflows structurally fix agentic laziness, self-preferential bias, and goal drift inherent in single-context sessions. It then breaks down six core patterns—classify-and-act, fan-out-and-synthesize, adversarial verification, generate-and-filter, tournament, and loop until done—each with code skeletons. Real-world use cases show how to compose patterns for migrations, deep research, triage, and lightweight evals. Practical controls like /goal, /loop, token budgets, and the quarantine pattern for untrusted inputs are covered. It also advises on saving successful workflows and shipping them as Skills. This guide is for engineers aiming to tackle long-running, parallel, or adversarial tasks beyond a single Claude Code session.
Most Claude Code users still write their workflows by hand. They chain prompts, copy outputs, paste them into the next prompt, fix what went wrong, repeat.
9 out of 10 builders haven't tried Dynamic Workflows even once, even though they shipped two weeks ago.
They write 50 prompts when one workflow would do. This is the 14-step roadmap and the 6 patterns Anthropic's own engineers actually use - for migrations, research, sorting, root-cause, triage, and evals.
大多数 Claude Code 用户仍手动编写工作流。他们串联提示词、复制输出、粘贴到下一轮提示、修复问题、重复。
尽管动态工作流已发布两周,仍有 9/10 的开发者从未尝试过。
他们写了 50 条提示词,而一个工作流就能搞定。下文是 Anthropic 工程师实际使用的 14 步路线图和 6 种模式——用于迁移、研究、排序、根因分析、分类和评估。
Dynamic Workflows shipped in Claude Code on May 28, 2026. The default Claude Code harness is built for coding - and that works well for most coding tasks. But there are classes of work where one context window starts to break down: long-running, massively parallel, highly structured, or adversarial.
For those, Anthropic used to build custom harnesses themselves (Research, Code Review, agent teams). With Dynamic Workflows, Claude writes that harness for you on the fly, custom-built for your task, in JavaScript.
动态工作流于 2026 年 5 月 28 日在 Claude Code 中发布。默认的 Claude Code 运行时是为编码而设计的,这对大多数编码任务都很有效。但有一类工作会让单一上下文窗口开始失效:长时间运行、大规模并行、高度结构化或对抗性的场景。
对于这些场景,Anthropic 过去会自行构建自定义运行时(用于研究、代码审查、智能体团队)。有了动态工作流,Claude 会为你即时编写这个运行时,针对任务用 JavaScript 定制构建。
The default Claude Code harness has Claude plan and execute in the same context window. For most coding work, this is great. For long-running, parallel, or adversarial work, it breaks down.
A Dynamic Workflow is Claude writing its own custom harness for the task - a JavaScript file with a few special functions that spawn and coordinate subagents, plus standard JavaScript (Math, JSON, Array) to process the data flowing between them.
Three things this gives you that the default harness cannot:
- Per-agent isolation. Each subagent gets its own context window with one focused goal. No cross-contamination.
- Per-agent model choice. The workflow picks which model each subagent uses - Opus for hard reasoning, Haiku for cheap exploration, Sonnet for the middle.
- Per-agent isolation level. Worktree (isolated git checkout) or remote (no checkout). The workflow decides what each agent needs.
Start one by either asking Claude directly (“make a workflow that…”) or with the trigger word ultracode. If a workflow is interrupted - user action, terminal quit - resuming the session picks up where it left off.
默认的 Claude Code 运行时让 Claude 在同一上下文窗口内规划和执行。对于大多数编码工作,这很合适。对于长时间运行、并行或对抗性的工作,它就会失效。
动态工作流是 Claude 为任务自行编写定制的运行时——一个 JavaScript 文件,包含几个特殊函数来生成和协调子智能体,以及标准 JavaScript(Math、JSON、Array)来处理它们之间流动的数据。
这为你带来了默认运行时无法提供的三个能力:
- 每个智能体相互隔离。每个子智能体都有自己的上下文窗口和一个聚焦的目标。没有交叉污染。
- 每个智能体可选模型。工作流为每个子智能体选择模型——Opus 处理硬核推理、Haiku 用于低成本探索、Sonnet 处理中间任务。
- 每个智能体隔离级别。工作树(隔离的 git checkout)或远程(无 checkout)。工作流决定每个智能体需要什么。
启动工作流:直接要求 Claude(“创建一个工作流,用来……”),或使用触发词 ultracode。如果工作流被中断(用户操作、终端退出),恢复会话会从断点继续。
To know when a workflow is the right tool, you have to know what it fixes. The longer Claude works on a complex task in a single context window, the more it becomes susceptible to three specific failure modes - named directly in the Anthropic launch writing:
- Agentic laziness - Claude stops before finishing a complex, multi-part task and declares done after partial progress. Addresses 20 of the 50 items in a security review and calls the rest “handled.”
- Self-preferential bias - Claude prefers its own results when asked to verify or judge them against a rubric. A verifier with skin in the game can't be a fair verifier.
- Goal drift - the gradual loss of fidelity to the original objective across many turns, especially after compaction. Each summarization step is lossy. “Don't do X” constraints quietly disappear at turn 47.
A workflow solves all three structurally: separate Claudes with their own contexts, focused goals, and isolated state. If your task suffers from any of these patterns - that's the signal to reach for a workflow.
要知道何时该用工作流,就得先清楚它解决了什么问题。Claude 在单个上下文窗口中处理复杂任务的时间越长,就越容易出现三种特定的失效模式——Anthropic 在发布文章中直接命名了它们:
- 智能体懒惰——Claude 在完成复杂的多部分任务之前就停下来,声明部分进度后觉得“完成了”。比如安全审查时处理了 50 项中的 20 项,就把其余的称为“已处理”。
- 自我偏好偏见——当要求 Claude 按标准评估或核查自己的结果时,它倾向于偏爱自己的结果。一个有利害关系的审查者不可能是公平的审查者。
- 目标漂移——经过多轮对话后,特别是上下文压缩后,逐渐丧失对原始目标的忠实度。每次摘要步骤都会有信息损失。“不要做 X”的约束在第 47 轮悄悄消失。
工作流从结构上解决了所有三个问题:独立的 Claude 实例,各自拥有自己的上下文、聚焦的目标和隔离的状态。如果你的任务遇到这些模式之一——那就是该用工作流的信号。
You may have already built static workflows using the Claude Agent SDK or claude -p - coordinating multiple Claude Code instances together.
- Static workflows are generic: written once to handle every edge case. They work, but they have to be conservative.
- Dynamic Workflows are different: Claude writes this workflow for this task. The harness is tailor-made. Below is the same question handled both ways:
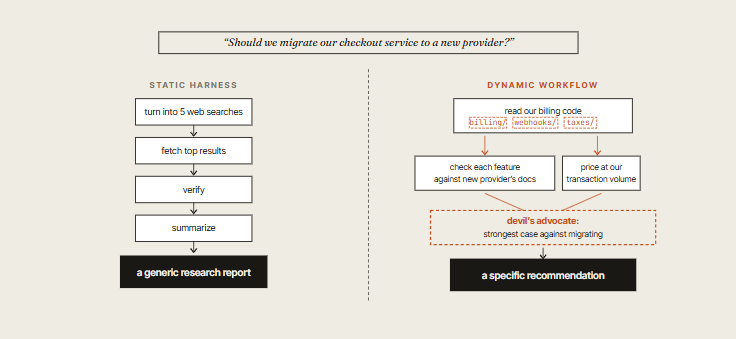
The reason the dynamic version wins isn't the search step - both can search.
It's that the workflow gets to shape itself around your context: read your billing code, check each feature against the actual new provider docs, price at your transaction volume, and run an adversarial “why not to migrate” pass against its own emerging answer.
A static harness can't do this because it doesn't know your code exists.
你可能已经使用 Claude Agent SDK 或 claude -p 构建过静态工作流——协调多个 Claude Code 实例。
- 静态工作流是通用的:一次编写就能处理所有边缘情况。它们能工作,但必须很保守。
- 动态工作流则不同:Claude 为这个任务编写这个工作流。运行时是量身定制的。下图展示了同一个问题两种处理方式的对比:
动态版本胜出的原因不在于搜索步骤——两者都可以搜索。
而是工作流能够根据你的上下文来塑造自己:读取你的计费代码,对照实际的新提供商文档检查每个功能,根据你的交易量定价,并针对自己正在形成的答案运行一轮对抗性“为什么不要迁移”的检查。
静态运行时做不到这一点,因为它不知道你的代码存在。
Three functions do most of the work in a workflow. Knowing them is enough to read any workflow Claude writes for you and to nudge Claude when you want a specific shape.
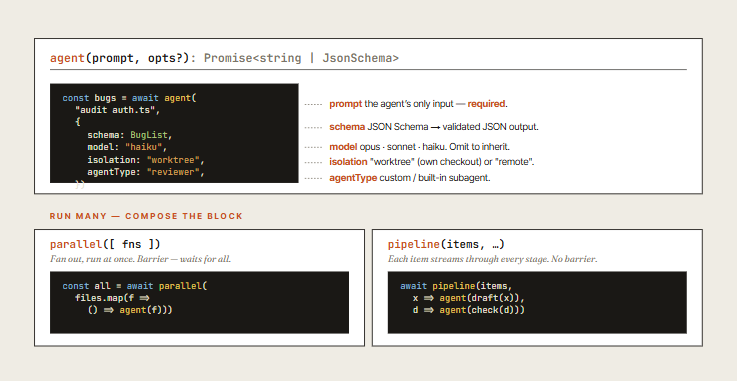
parallel() is a barrier: it fans out, then waits for everything before returning. pipeline() is streaming: each item flows through every stage independently.
Pick by the question: do I need all results before I can do anything next? Yes → parallel. No → pipeline (cheaper, faster overall).
三个函数完成了工作流中的大部分工作。了解它们就足以读懂 Claude 为你写的任何工作流,并能在你希望采用特定形状时引导 Claude。
parallel() 是一个屏障:它分派任务,然后等待所有任务完成再返回结果。pipeline() 是流式的:每个项目独立流经每个阶段。
按以下问题选择:在开始下一步之前,我是否需要所有结果?是 → 用 parallel。否 → 用 pipeline(成本更低,整体更快)。
A classifier agent decides on the type of task, then the workflow routes to different agents or behaviors based on the answer. Or a classifier runs at the end, sorting raw outputs into buckets for whatever comes next.
When this pattern earns its keep:
- The task is heterogeneous - different sub-types need different treatment.
- You want to spend the expensive model only where complexity demands it (classifier on cheap, then route to Opus only when needed).
- The decomposition of work is itself non-trivial and benefits from a model deciding the shape.
Example: “Explain how the auth module works.” A classifier subagent reads the codebase first, estimates complexity, then routes the actual explanation task to Sonnet for a 10-file module or Opus for a 100-file one. The right model for the job, decided after the work is understood.
分类智能体判断任务类型,然后工作流根据答案路由到不同的智能体或行为。或者分类器在最后运行,将原始输出分类存放,供下一步使用。
这种模式在以下场景最为实用:
- 任务是异构的——不同子类型需要不同的处理方式。
- 你希望只在复杂性要求的地方才使用昂贵的模型(分类器用便宜模型,仅在需要时路由到 Opus)。
- 任务分解本身就不简单,借助模型来决定分解形态更有优势。
示例:“解释 auth 模块如何工作。”分类子智能体先读取代码库,评估复杂度,然后将实际解释任务路由给 Sonnet(处理 10 个文件的模块)或 Opus(处理 100 个文件的模块)。理解工作之后,再为任务选择合适的模型。
Split a task into many smaller steps. Run an agent on each step in parallel. Synthesize the results into one answer.
The synthesize step is a barrier - it waits for every fan-out agent, then merges their structured outputs.
Why this pattern dominates in practice: it solves the “too many things at once” failure of single-context work. Each subagent sees only its piece. The orchestrator never gets distracted by 50 unrelated details.
Each step benefits from its own clean window so they don't cross-contaminate.
Use this when:
- You have a clearly enumerable list of work items (50 files, 200 endpoints, 100 reviews).
- Each item is independent - no item needs another's output to begin.
- You want a single consolidated answer at the end, not a pile of partial reports.
// Fan out: one agent per file. Barrier: wait for all.
const reviews = await parallel(
files.map(file => () => agent(
`Review ${file} for security issues`,
{ model: "haiku", schema: IssueList }
))
)
// Synthesize: one Opus agent merges everything.
const report = await agent(
`Merge these reviews into one prioritized report:\n${JSON.stringify(reviews)}`,
{ model: "opus" }
)
将任务拆解成许多更小的步骤。让一个智能体并行处理每个步骤。将结果整合成一个答案。
整合步骤是一个屏障——它等待所有分派出去的智能体完成,然后合并它们结构化的输出。
为什么这种模式在实践中占据主导:它解决了单一上下文工作“一次性处理太多事情”的失败。每个子智能体只看到自己那部分。编排器永远不会被 50 个不相关的细节分心。
每个步骤都受益于自己干净的工作窗口,因此不会交叉污染。
在以下情况下使用此模式:
- 你有一个清晰可枚举的工作项列表(50 个文件、200 个端点、100 条审查)。
- 每个项目都是独立的——没有项目需要另一个项目的输出才能开始。
- 你希望最终得到一个整合的答案,而不是一堆零散的报告。
// 分派:每个文件一个智能体。屏障:等待所有完成。
const reviews = await parallel(
files.map(file => () => agent(
`Review ${file} for security issues`,
{ model: "haiku", schema: IssueList }
))
)
// 整合:一个 Opus 智能体合并所有。
const report = await agent(
`Merge these reviews into one prioritized report:\n${JSON.stringify(reviews)}`,
{ model: "opus" }
)
This is the structural fix for self-preferential bias. For each spawned agent, run a separate spawned agent that adversarially verifies its output against a rubric. The verifier has never seen the original work; it can't favor it.
The pattern matters most for:
- Claim-checking - every factual statement in a report gets its own verifier subagent, checking against the original source.
- Code review - the author agent writes the fix, the reviewer agent (separate context) reviews it. Never the same Claude judging itself.
- Quality gates - before any artifact ships, an adversary tries to find the weakest case against it. If the adversary can't, you ship.
The pairing rule: the verifier should know only the rubric and the artifact, not who produced it. Otherwise self-preference creeps back in through hints in the prompt.
这是对自我偏好偏见的结构性修复。对于每个生成的智能体,运行一个单独的对抗性验证智能体,按照标准检查其输出。验证者从未见过原始工作,因此不会有所偏爱。
此模式在以下场景最为关键:
- 声明核查——报告中的每个事实陈述都有自己独立的验证子智能体,对照原始来源进行检查。
- 代码审查——作者智能体编写修复方案,审阅智能体(独立上下文)审查它。永远不要让同一个 Claude 自我评判。
- 质量关卡——在任何交付物上线之前,由一个对抗方尝试找出最弱的案例来反驳它。如果对抗方做不到,就上线。
配对规则:验证者应该只知道标准和交付物,不知道是谁生成的。否则,自我偏好会通过提示中的线索悄悄重现。
Generate a number of ideas on a topic, then filter them by a rubric or by verification. Dedupe duplicates. Return only the highest quality, tested ideas.
Where this pattern shines:
- Brainstorming - 30 product names, then a verifier kills clichés, trademark conflicts, and weak phonetics. You see 3.
- Hypothesis generation - 5 different approaches to a problem, then each gets scored against your constraints. The winner has earned it.
- Solution design - 5 different approaches to a problem, then each gets scored against your constraints. The winner has earned it.
The opposite of asking Claude for “the best answer.” Asking for the best answer makes Claude commit early. Generate-and-filter makes Claude commit late, after every option has been challenged.
围绕一个主题生成多个想法,然后按标准或验证进行筛选。去重后只返回最高质量、经过检验的想法。
这种模式在以下场景表现突出:
- 头脑风暴——生成 30 个产品名称,然后验证者淘汰陈词滥调、商标冲突和发音不佳的。你最终只看到 3 个。
- 假设生成——针对一个问题生成 5 种不同方法,然后每种方法都根据你的约束条件打分。胜者实至名归。
- 解决方案设计——针对一个问题生成 5 种不同方法,然后每种方法都根据你的约束条件打分。胜者实至名归。
这与直接让 Claude“找出最佳答案”相反。要求最佳答案会让 Claude 过早做出承诺。生成并筛选让 Claude 在每一个选项都受到挑战之后才做出最终决定。
Instead of dividing the work, have agents compete on it. Spawn N agents that each attempt the same task using different approaches, then judge the results in pairwise fashion until one wins.
Comparative judgment is more reliable than absolute scoring - especially for taste-based work.
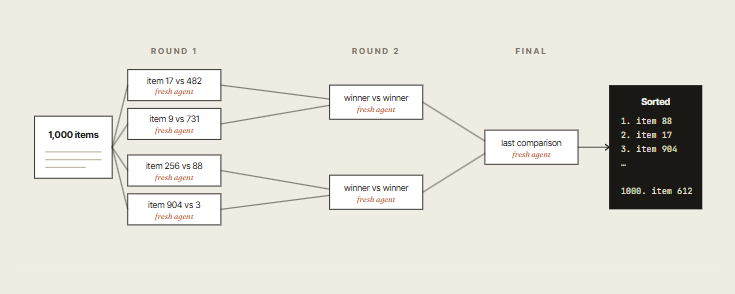
Why this beats sort-by-score: trying to sort 1,000 items in one prompt fails on two fronts - quality degrades, and it won't fit in context. A tournament splits the bracket across fresh agents, each comparing just two items.
The bracket itself lives in deterministic loop code, not in context. Each comparison is fast, fair, and isolated. Same idea works for taste-based ranking: design choices, candidate selection, content prioritization.
与其分派工作,不如让智能体相互竞争。生成 N 个智能体,每个智能体尝试用不同方法完成同一任务,然后通过两两比较评判结果,直到产生一个胜者。
比较判断比绝对评分更可靠——尤其是对于品味相关的工作。
为什么这比“按分数排序”更好:尝试在一条提示中对 1000 个项目进行排序会在两方面失败——质量下降,而且放不进上下文。锦标赛将胜负树拆分成每个全新的智能体只比较两个项目。
胜负树本身存在于确定性的循环代码中,而不是上下文里。每次比较都快速、公平且隔离。相同的思路也适用于基于品味的排名:设计选择、候选人筛选、内容优先级排序。
For tasks with an unknown amount of work, loop spawning agents until a stop condition is met - no new findings, no more errors in the logs, theory verified - instead of running a fixed number of passes.
This pattern is the answer to “keep going until it's actually done”:
- Flaky test debugging - reproduce, form theories, test them, until one theory holds.
- Bug hunting - keep finding bugs until a full pass returns zero.
- Mining for patterns - cluster, identify rules, until no new clusters appear.
Pair this pattern with /goal to set a hard completion requirement (“don't stop until one theory works”) and with /loop if you want the entire workflow itself to run on a recurring schedule.
The bracket and the stop condition live in code; only the active iteration stays in context.
对于工作量未知的任务,循环生成智能体,直到满足停止条件——不再有新发现、日志中没有更多错误、理论得到验证——而不是执行固定次数的轮次。
这种模式是“一直走下去直到真正完成”的答案:
- 不稳定测试调试——复现、形成理论、测试它们,直到某个理论成立。
- Bug 搜寻——持续发现 bug,直到完整一轮返回零个 bug。
- 模式挖掘——聚类、识别规则,直到没有新聚类出现。
将此模式与 /goal 配对以设置硬性完成要求(“直到一个理论成功才能停止”),如果你希望整个工作流按计划定期运行,则与 /loop 配对。
胜负树和停止条件存在于代码中;只有当前活跃的迭代保留在上下文中。
The 6 patterns rarely appear alone. A real workflow composes 2-4 of them. The matrix below pairs each use case from the Anthropic launch writing with the patterns it tends to use:
- Migrations and refactors. Fan-out (one agent per callsite/failing test in a worktree) → adversarial verification (a separate agent reviews each fix) → loop until done. This is the pattern Anthropic used to rewrite Bun from Zig to Rust.
- Deep research (the /deep-research skill). Fan-out (parallel web searches) → adversarial verification (each claim verified independently) → synthesize (one cited report).
- Deep verification of a draft. Identify all factual claims (one agent) → fan-out (one verifier per claim, each agent checks against source) → meta-verifier (checks the verifier's sources are high quality).
- Sorting 1,000+ items. Tournament (steps 5-9) - pairwise comparison, bucket-rank, or bracket. Comparative judgment, never absolute scoring.
- Memory and rule adherence. Verifier per rule (fan-out) → skeptic persona reviews the rules themselves to avoid false positives.
- Root-cause investigation. Generate theories from disjoint evidence (different agents read logs, files, data) → panel of verifiers and refuters for each theory → loop until one survives.
- Triage at scale. Classify-and-act → dedupe against existing tickets → either attempt the fix or escalate. Pair with /loop for continuous triage.
- Exploration and taste (design, naming, UI choices). Generate-and-filter (5-20 options) → tournament with a rubric → rank or pick.
- Lightweight evals. Run the candidate in a worktree → comparison agents grade against rubric → refine and re-grade. Same shape as a tournament but for grading, not ranking.
The right way to internalize these: identify which failure mode your current task is failing under, then pick the pattern that structurally prevents it.
Drift → fan-out. Self-preference → adversarial verification. Open-ended → loop until done. Hard-to-score → tournament.
6 种模式很少单独出现。一个真实的工作流通常会组合 2-4 种模式。下表将 Anthropic 发布文章中提到的每个用例与其常用的模式配对:
- 迁移和重构。分派(工作树中每个调用点/失败的测试对应一个智能体)→ 对抗性验证(单独的智能体审查每个修复)→ 循环直至完成。这是 Anthropic 用来将 Bun 从 Zig 重写为 Rust 的模式。
- 深度研究(/deep-research 技能)。分派(并行网络搜索)→ 对抗性验证(每个声明独立验证)→ 整合(一份带引用的报告)。
- 草稿深度验证。识别所有事实声明(一个智能体)→ 分派(每个声明一个验证者,每个智能体对照来源检查)→ 元验证者(检查验证者的来源是否高质量)。
- 对 1000+ 个项目排序。锦标赛(步骤 5-9)——两两比较、分桶排名或胜者树。使用比较判断,绝不使用绝对评分。
- 记忆与规则遵循。每个规则一个验证者(分派)→ 怀疑者角色审查规则本身以避免误报。
- 根因调查。从分散的证据生成理论(不同智能体读取日志、文件、数据)→ 每个理论的验证者和反驳者小组 → 循环直到一个幸存。
- 大规模分类。分类并执行 → 对现有工单去重 → 尝试修复或升级。与 /loop 配对以进行持续分类。
- 探索与品味(设计、命名、UI 选择)。生成并筛选(5-20 个选项)→ 带标准的锦标赛 → 排名或选择。
- 轻量级评估。在工作树中运行候选方案 → 比较型智能体按标准评分 → 优化和重新评分。与锦标赛形状相同,但用于评分而非排名。
内化这些模式的方法:识别你当前任务已经属于哪种失效模式,然后选择从结构上预防该失效的模式。
目标漂移 → 分派。自我偏好 → 对抗性验证。开放式 → 循环直至完成。难以评分 → 锦标赛。
Workflows can be expensive. Three controls turn them from “cool but costly” into “a tool I run unattended.”
- /goal sets a hard completion requirement. Pair it with the loop pattern: “don't stop until one theory works.” Without /goal, a workflow stops at a soft completion point. With /goal, it iterates until the actual end condition is met.
- /loop runs the entire workflow on a recurring schedule. Use it for workflows you want running continuously - triage, weekly research updates, recurring verification.
- Explicit token budgets. Tell Claude in the prompt: “use 10k tokens.” This sets a cap on the workflow run. Without a cap, an ambitious workflow can balloon to 5–10× the tokens you expected.
> ultracode quick adversarial review of this assumption:
"moving to Postgres eliminates our shard rebalancing."
Use 5k tokens. /goal don't stop until you have either
a counterexample or three independent confirmations.
Quoting the Claude Code team directly: “Best practices are still developing. Dynamic workflows often use more tokens, so think carefully about when and how to use them.” Most traditional coding tasks do not need a panel of 5 reviewers.

Ask yourself: does this task really need more compute? If a regular Claude Code session would finish it in five minutes, you don't need a workflow.
工作流可能很昂贵。三个控制机制将它们从“很酷但很贵”变成“我可以无人值守运行的可靠工具”。
- /goal 设置硬性完成要求。与循环模式配对使用:“直到一个理论有效才能停止”。没有 /goal,工作流会在一个软完成点停止。有了 /goal,它会迭代直到满足实际结束条件。
- /loop 按定期计划运行整个工作流。用于希望持续运行的工作流——分类、每周研究更新、定期验证。
- 显式 token 预算。在提示中告诉 Claude:“使用 10k tokens”。这设置了工作流运行的预算上限。没有上限,一个雄心勃勃的工作流可能膨胀到你预期 token 数的 5-10 倍。
> ultracode quick adversarial review of this assumption:
"moving to Postgres eliminates our shard rebalancing."
Use 5k tokens. /goal don't stop until you have either
a counterexample or three independent confirmations.
直接引用 Claude Code 团队的话:“最佳实践仍在发展中。动态工作流通常使用更多 token,所以请仔细考虑何时以及如何使用它们。”大多数传统编码任务不需要 5 个审查者的评审组。
问自己:这个任务真的需要更多计算吗?如果普通的 Claude Code 会话能在五分钟内完成它,你就不需要工作流。
Any workflow that reads untrusted public content - support tickets, bug reports, user feedback, scraped data - needs to assume that content might contain prompt injection.
The fix: quarantine. Bar the agents that read the untrusted content from taking any high-privilege actions. Separate agents, with no exposure to the raw content, do the acting.
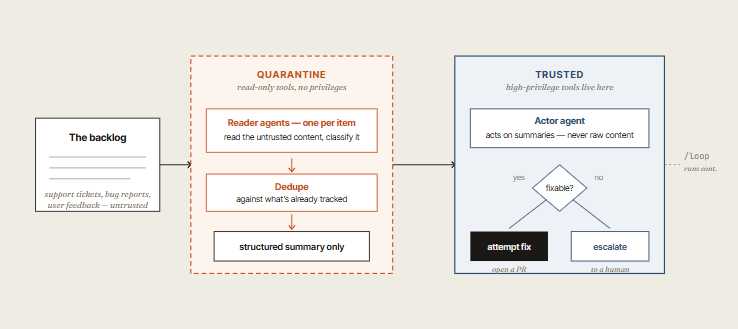
Any workflow that processes user-submitted content (support tickets, bug reports, customer feedback, social media), scrapes public web pages, or runs against output from a third-party API.
If the input wasn't written by you or a trusted teammate, quarantine it. A 30-line read-only reader agent costs almost nothing and removes an entire class of prompt injection risk.
任何读取不受信任的公开内容的工作流——支持工单、Bug 报告、用户反馈、爬取的数据——都需要假设这些内容可能包含提示注入。
解决方案:隔离。禁止读取不受信内容的智能体执行任何高权限操作。由另外的、未暴露原始内容的智能体执行实际操作。
任何处理用户提交内容(支持工单、Bug 报告、客户反馈、社交媒体)、爬取公开网页或处理第三方 API 输出的工作流,都应使用此模式。
如果输入不是你或可信队友编写的,就隔离它。一个 30 行的只读读取智能体几乎不花成本,却能消除一整类提示注入风险。
Once a workflow works, save it: press s in the workflow menu. Saved workflows go to ~/.claude/workflows. From there you have two paths:
- Keep it local - reuse it across your own projects.
- Ship it as a Skill - bundle the JavaScript file inside a Skill folder, reference it in SKILL.md, and anyone who installs the Skill runs the same workflow.

One practical nuance worth knowing: when you package a workflow into a Skill, prompt Claude to treat the workflow as a template, not a script to run verbatim.
That leaves room for Claude to adapt the workflow shape to the specific task at hand while keeping the overall structure intact. Especially useful for workflows like “deep verification” or “triage” that need to flex per use case.
一旦工作流运行正常,保存它:在工作流菜单中按 s。保存的工作流位于 ~/.claude/workflows。你有两种方式使用:
- 保留在本地——在你的项目中重复使用。
- 作为技能发布——将 JavaScript 文件打包到技能文件夹中,在 SKILL.md 中引用它,任何安装该技能的人都能运行相同的工作流。
一个值得了解的实际细节:将工作流打包成技能时,提示 Claude 将工作流视为模板,而不是逐字运行的脚本。
这样 Claude 就能在保持整体结构不变的前提下,根据具体任务调整工作流的形状。对于“深度验证”或“分类”这类需要根据用例灵活调整的工作流尤其有用。
- Reaching for a workflow when a regular Claude Code session would do. Most traditional coding tasks don't need a panel of 5 reviewers.
- No token budget. Ambitious workflows balloon to 5–10× what you expected without an explicit cap.
- One agent doing both the work and the verification. Self-preferential bias makes the verifier favor the worker. They must be separate.
- Treating parallel() and pipeline() as interchangeable. The barrier matters - parallel waits for all, pipeline streams.
- Skipping /goal on loop patterns. The workflow stops early at the first soft completion point. /goal forces hard completion.
- Letting untrusted content reach the actor. Quarantine isn't optional once you process anything user-submitted.
- Sorting with absolute scores. Comparative judgment is more reliable. Use a tournament.
- Never saving working workflows. Re-prompting the same shape every week. Save with s, ship as a Skill.
- 在普通 Claude Code 会话足以完成任务时使用工作流。大多数传统编码任务不需要 5 名审查者的评审组。
- 没有 token 预算。雄心勃勃的工作流在没有明确上限时会膨胀到你预期 token 数的 5-10 倍。
- 同一个智能体既做工作又做验证。自我偏好偏见会让验证者偏向工作者。两者必须分离。
- 将 parallel() 和 pipeline() 混为一谈。屏障很重要——parallel 等待所有结果,pipeline 流式传输。
- 在循环模式中跳过 /goal。工作流会在第一个软完成点提前停止。/goal 强制硬性完成。
- 让不受信内容到达执行者。一旦处理任何用户提交的内容,隔离就不是可选项。
- 使用绝对评分排序。比较判断更可靠。使用锦标赛模式。
- 从不保存正常的工作流。每周都要重新提示同样的形状。——按 s 保存,作为技能发布。