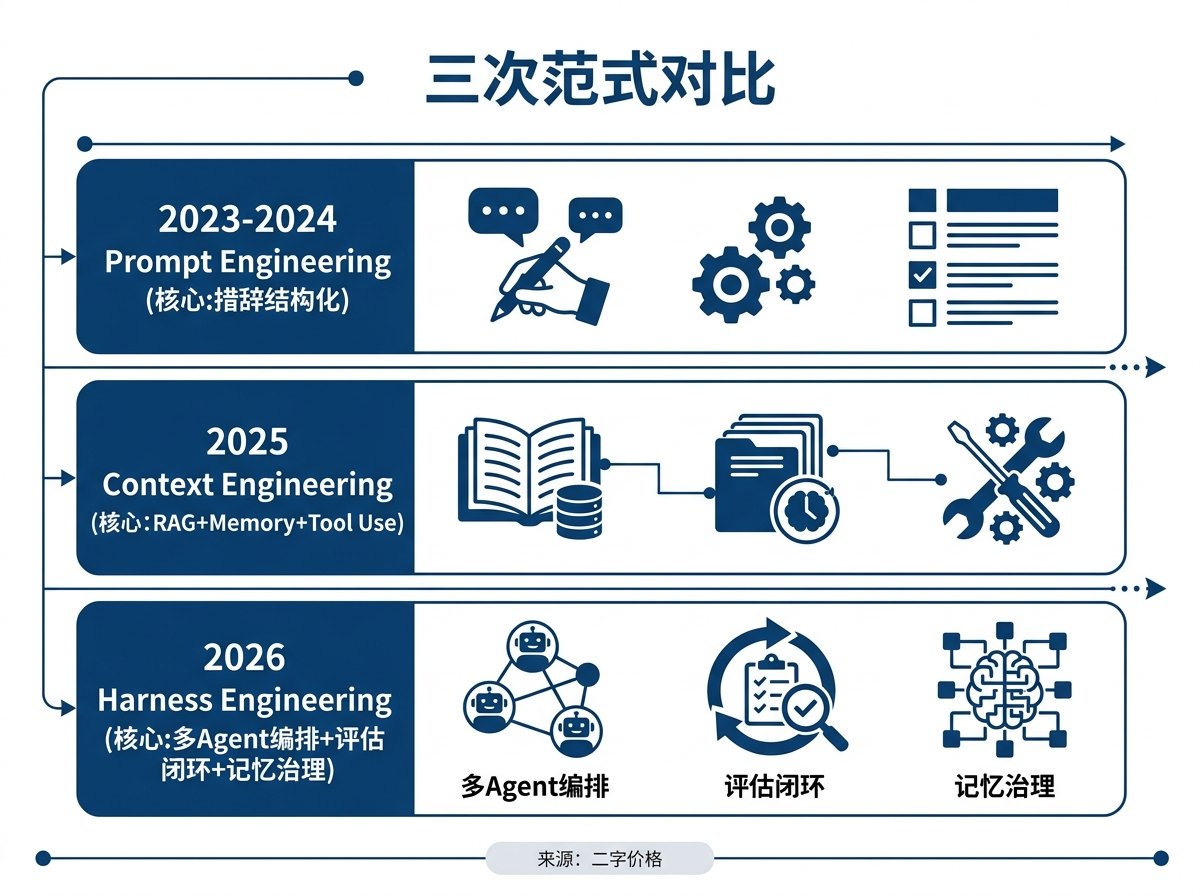
从 Prompt 到 Context 再到 Harness:AI 工程的三次范式转移
文章梳理了AI工程从Prompt Engineering (2023-2024)、Context Engineering (2025) 到Harness Engineering (2026初) 的三代范式转移。Harness Engineering 包含评估闭环、架构约束、记忆治理三层,分别由 Anthropic 和 OpenAI 的实操验证:Anthropic 的评估器 Agent 使 20 分钟产出不可用变为 6 小时产出完整游戏;OpenAI 五个月零手写构建百万行代码生产系统,依赖分层架构和 CI/linter 强制约束。两篇学术论文填补记忆层空白:(S)AGE 记忆系统通过拜占庭容错的 Proof of Experience 共识实现可信共享记忆,使 Agent 校准精度翻倍;纵向学习实验表明 3 行 prompt 加记忆与 200 行专家 prompt 性能持平,但前者随轮次显著提升。适合构建多 Agent 系统的工程师阅读。

In early 2026, Anthropic and OpenAI both published practical articles on Harness Engineering within almost the same week. Along with two academic papers on Agent memory infrastructure and community discussions on the evolution of three engineering paradigms, a complete picture is emerging.
2026年初,Anthropic 和 OpenAI 几乎同一周发了各自关于 Harness Engineering 的实践文章。加上两篇关于 Agent 记忆基础设施的学术论文,以及社区里关于三代工程范式演进的讨论,一个完整的图景正在浮现

The years 2023 to 2024 were the era of Prompt Engineering. The core challenge was how to talk to a model to get better responses. Wording, formatting, few-shot examples, Chain of Thought—all techniques revolved around a single conversation.
2023到2024年是 Prompt Engineering 的时代。核心问题是怎么跟模型说话,让它给出更好的回答。措辞、格式、few-shot 示例、Chain of Thought,所有技巧都围绕"一次对话"展开
In 2025, Context Engineering became a mainstream concept. Shopify CEO Tobi's statement 'Context engineering is the new skill' was widely shared. The core issue shifted: prompting alone wasn't enough; the entire context window had to be engineered. RAG retrieval, long-context management, tool use orchestration, and memory systems all fell under this umbrella. You were optimizing all the information the model sees.
2025年 Context Engineering 成为主流概念。Shopify CEO Tobi 的那句"Context engineering is the new skill"被广泛传播。核心问题变了:单靠提示词不够,需要把整个上下文窗口当作工程对象来设计。RAG 检索、长上下文管理、tool use 编排、memory 系统全部属于这个范畴。你在优化的是模型看到的全部信息
In early 2026, the concept of Harness Engineering was proposed almost simultaneously by two major companies. The core challenge escalated again: Agents could now run autonomously for hours or even days, so optimizing a single context window was far from sufficient. You needed to design the entire runtime environment for the Agent—including multi-agent collaboration architectures, evaluation feedback loops, mechanized enforcement of architectural constraints, and memory governance and verification mechanisms. The relationship among the three paradigms: each encompasses the previous one. Harness includes Context, Context includes Prompt. But the core problems they solve are fundamentally different.
2026年初 Harness Engineering 这个概念被两家大厂几乎同时提出。核心问题再次升级:Agent 可以自主运行几个小时甚至几天了,单次上下文的优化远远不够。你需要设计的是 Agent 的整个运行环境,包括多 Agent 协作架构、评估反馈闭环、架构约束的机械化执行、记忆的治理和验证机制 三代之间的关系:每一代都包含前一代。Harness 包含 Context,Context 包含 Prompt。但每一代解决的核心问题完全不同
Anthropic engineer Prithvi Rajasekaran's experiment revealed a counterintuitive fact: an Agent evaluating its own work is basically useless. Regardless of output quality, an Agent always gives itself positive ratings. The effect changed completely once generation and evaluation were split into two independent Agents. The evaluator didn't just read code and score—it used Playwright to actually interact with the page, clicking buttons, filling forms, and verifying functionality, then scored on four dimensions: design quality, originality, craftsmanship, and functional completeness.
Anthropic 工程师 Prithvi Rajasekaran 的实验揭示了一个反直觉的事实:Agent 评估自己的工作基本没用 不管输出质量高低,Agent 给自己的评价永远是正面的。把生成和评估拆成两个独立 Agent 之后效果完全不同。评估器不是读代码打分,而是用 Playwright 实际操作页面,点按钮、填表单、验证功能,然后根据四个维度打分:设计质量、原创性、工艺细节、功能完整度
In the frontend design experiment, after 5 to 15 rounds of back-and-forth between the generator and the evaluator, the generator produced a 3D spatial navigation solution around the tenth round.
前端设计实验里,生成器经过5到15轮和评估器的来回迭代,在第十轮做出了一个3D空间导航方案。
The full-stack development experiment was more complex, with three Agents taking on separate roles: a planner expanded a one-sentence requirement into a full product specification, a generator implemented it step by step using React+FastAPI+PostgreSQL, and an evaluator performed QA testing.
全栈开发实验更复杂,三个 Agent 分工:规划器把一句话需求展开成完整产品规格、生成器用 React+FastAPI+PostgreSQL 逐步实现、评估器做 QA 测试
The comparison data was clear. A single Agent in 20 minutes cost $9 and produced unusable output. A full harness in 6 hours cost $200 and delivered a complete game with sprite animations, AI integration, and export functionality. The most valuable finding: as Opus 4.6 improved, sprint decomposition could be removed, but the evaluator could not. Every component of the Harness encodes assumptions about model limitations. As models get stronger, some assumptions no longer hold, but some always will. Identifying which to keep and which to discard is a core skill of harness engineering.
对比数据很直观。单 Agent 20分钟花9美元,产出不能用。完整 harness 6小时花200美元,交付了带精灵动画、AI 集成和导出功能的完整游戏 最有价值的发现:随着 Opus 4.6 能力提升,sprint 分解可以去掉了,但评估器不能去掉。Harness 的每个组件都编码了对模型局限性的假设。模型变强之后有些假设不再成立,但有些永远成立。识别哪些该留哪些该删,是 harness engineering 的核心技能

OpenAI's experiment was more aggressive. In five months, a small team used Codex Agent to build a production system of roughly one million lines of code. Zero hand-written. Application logic, documentation, CI configuration, observability infrastructure, toolchains—all generated by the Agent. The role of engineers completely changed. They did three things: design the development environment, express intent through structured prompts, and provide feedback loops to the Agent. OpenAI called this 'depth-first working': breaking down large goals into small building blocks, letting the Agent construct each block, and then using those blocks to unlock more complex tasks.
OpenAI 的实验更激进。五个月,一个小团队用 Codex Agent 构建了大约一百万行代码的生产系统。零手写。应用逻辑、文档、CI 配置、可观测性基础设施、工具链全部由 Agent 生成 工程师的角色彻底变了。他们做三件事:设计开发环境、用结构化 prompt 表达意图、给 Agent 提供反馈循环。OpenAI 管这个叫 depth-first working:把大目标拆成小构件,让 Agent 构建每个构件,然后用这些构件解锁更复杂的任务
Architecture governance was key to making this system work. Dependencies were organized into six strict layers: Types, Config, Repo, Service, Runtime, UI. Boundaries between layers were enforced mechanically by linters and CI—not by documentation conventions, but by code enforcement. PRs from the Agent that violated architectural constraints were automatically rejected.
架构治理是这套系统能跑起来的关键。依赖层级严格分六层:Types、Config、Repo、Service、Runtime、UI。每一层的边界用 linter 和 CI 机械化执行,不是靠文档约定,是靠代码强制。Agent 违反架构约束的 PR 会被自动拒绝
Martin Fowler's comment is spot-on: Harness Engineering encodes context engineering, architectural constraints, and garbage collection into machine-readable artifacts that Agents can systematically execute.
Martin Fowler 的评价很到位:Harness Engineering 把 context engineering、架构约束和垃圾回收编码成了机器可读的制品,Agent 可以系统性地执行

Anthropic discussed evaluation loops, OpenAI discussed architectural constraints, but neither delved deeply into memory. That gap was exactly filled by two academic papers. The first, the (S)AGE paper, proposed a Byzantine fault-tolerant multi-agent memory infrastructure. The core question: when multiple Agents share a knowledge base, how do you ensure the knowledge written is trustworthy? An Agent could write false information due to hallucination, or could be attacked adversarially with fake memory injection.
Anthropic 讲评估闭环,OpenAI 讲架构约束,但两家都没有深入讨论记忆。这恰好是两篇学术论文填补的空白 第一篇是 (S)AGE 论文,提出了拜占庭容错的多 Agent 记忆基础设施。核心问题:当多个 Agent 共享一个知识库的时候,怎么保证写入的知识是可信的。一个 Agent 可能因为幻觉写入了错误信息,也可能被对抗性攻击注入虚假记忆
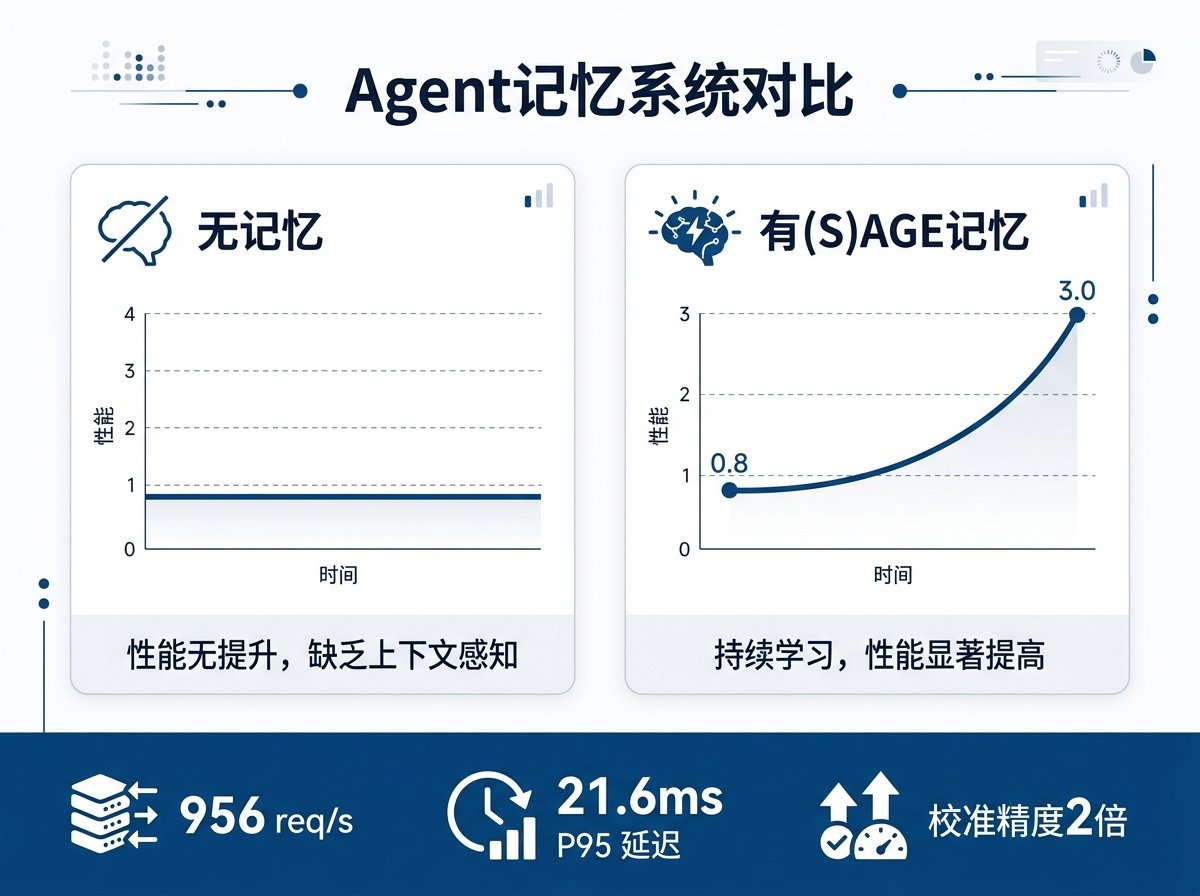
Their solution is the Proof of Experience consensus mechanism. Each Agent has a reputation weight determined by four factors: historical accuracy, domain relevance, activity level, and number of independent verifications. Any memory an Agent submits must pass a weighted vote before being written to the knowledge base. Deployed on a 4-node BFT network, it achieved 956 req/s writes and 21.6ms P95 queries. Agents with this memory system had calibration accuracy twice that of the memory-less baseline.
他们的方案是 Proof of Experience 共识机制。每个 Agent 有声誉权重,权重由四个因子决定:历史准确率、领域相关性、活跃度、独立验证数。Agent 提交的记忆需要经过加权投票验证才能写入知识库。部署在4节点 BFT 网络上,956 req/s 写入、21.6ms P95 查询。有这套记忆系统的 Agent 校准精度是无记忆基线的两倍
The second longitudinal learning paper addressed a more fundamental question: do agentic systems with memory actually improve over time? The experiment design was clever. Treatment group: 3-line prompt + (S)AGE memory, able to query all accumulated knowledge from previous rounds each round. Control group: 50 to 200 lines of expertly crafted prompts, but no memory, starting from scratch each round. After 10 rounds, the treatment group's red-teaming difficulty score rose from 0.8 to 3.0 (Spearman rho=0.716, p=0.020), while the control group showed no growth trend (rho=0.040, p=0.901). The most critical point: there was no statistical difference in absolute performance between the two groups (Cohen's d = -0.07). A 3-line prompt with memory tied with a 200-line expert prompt. The difference lay in the learning trajectory: the system with memory got better over time, while the one without memory stayed at the same level.
第二篇纵向学习论文回答了一个更根本的问题:有记忆的 Agent 系统真的会随时间变好吗 实验设计很巧妙。治疗组:3行 prompt + (S)AGE 记忆,每轮可以查询之前所有轮次积累的知识。对照组:50到200行专家精心编写的 prompt,但没有记忆,每轮从零开始。跑10轮之后,治疗组的红队评估难度从0.8增长到3.0(Spearman rho=0.716, p=0.020),对照组完全没有增长趋势(rho=0.040, p=0.901) 最关键的一点:两组的绝对性能水平没有统计差异(Cohen's d = -0.07)。3行 prompt 加记忆和200行专家 prompt 打了个平手。差异在于学习轨迹,有记忆的系统越跑越好,没记忆的永远在同一个水平线上
This means the memory layer gives agentic systems not higher initial performance, but organizational-level longitudinal learning capability. A human organization's 100th project is usually better than its first because of process documentation, post-mortems, and accumulated knowledge bases. Now agentic systems are beginning to show the same pattern.
这意味着记忆层给 Agent 系统带来的不是更高的初始性能,而是组织级的纵向学习能力。人类组织的第100个项目通常比第1个好,因为有过程文档、事后复盘、知识库积累。现在 Agent 系统也开始展现同样的特征
The differences among the three engineering paradigms can be summed up in one sentence: Prompt Engineering optimizes the interface between humans and models; Context Engineering optimizes the model's input space; Harness Engineering optimizes the entire runtime environment of Agents. Anthropic's experiments proved that evaluation loops are orders of magnitude more effective than self-evaluation. OpenAI's experiments proved that architectural constraints can maintain consistency in Agents at the million-line code level. The two papers proved that a consensus-verified memory system can give agentic organizations longitudinal learning capabilities. Together, these three layers form a complete Harness: evaluation mechanisms + architectural constraints + memory governance. Missing any one layer, and the agentic system will spin out of control in some dimension.
三代工程范式的区别可以用一句话概括 Prompt Engineering 优化的是人和模型之间的接口 Context Engineering 优化的是模型的输入空间 Harness Engineering 优化的是 Agent 的整个运行时环境 Anthropic 的实验证明了评估闭环比自评估有效几个数量级。OpenAI 的实验证明了架构约束可以让 Agent 在百万行代码级别保持一致性。两篇论文证明了共识验证的记忆系统可以让 Agent 组织具备纵向学习能力 这三层加在一起就是完整的 Harness:评估机制 + 架构约束 + 记忆治理。少了任何一层,Agent 系统都会在某个维度上失控
via Anthropic Engineering Blog / OpenAI Blog / (S)AGE Paper / Longitudinal Learning Paper
via Anthropic Engineering Blog / OpenAI Blog / (S)AGE Paper / Longitudinal Learning Paper